W↓
All docs
🔑
Sign Up/Sign In
doc.replicache.dev/
Public Link
Apr 8, 2025, 12:47:42 PM - complete - 248.1 kB
Created by:
****ad@vlad.studio
Starting URLs:
https://doc.replicache.dev/
## Page: https://doc.replicache.dev/ This tutorial takes about 15 minutes, and will walk you through the basics of using Replicache. It runs in the browser so there’s nothing to install or setup. The app you'll build is a counter that is synced across browsers. 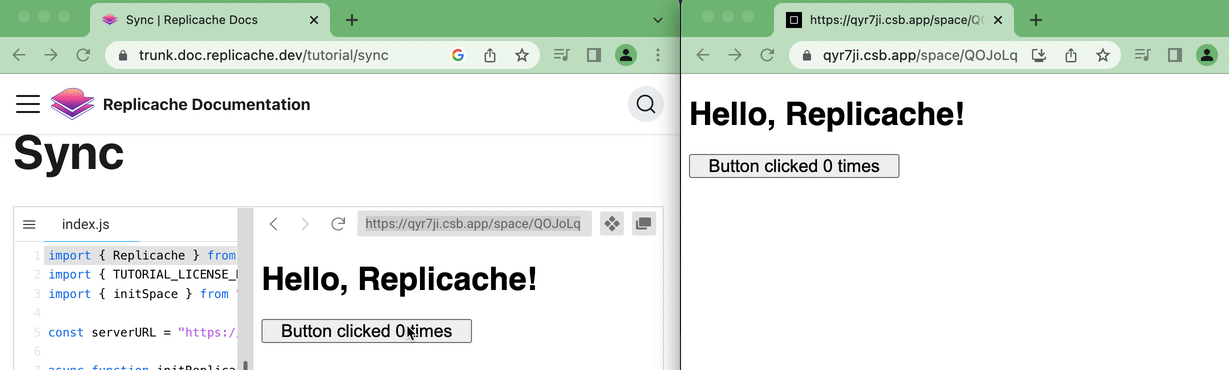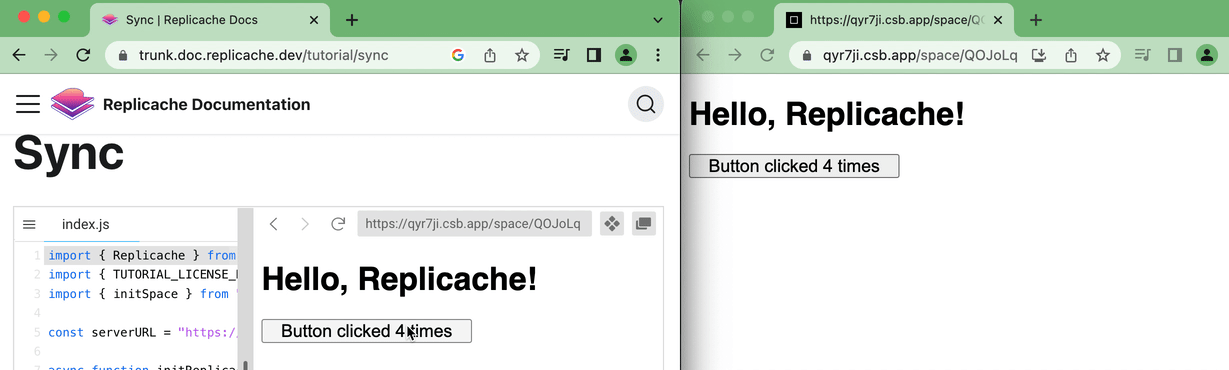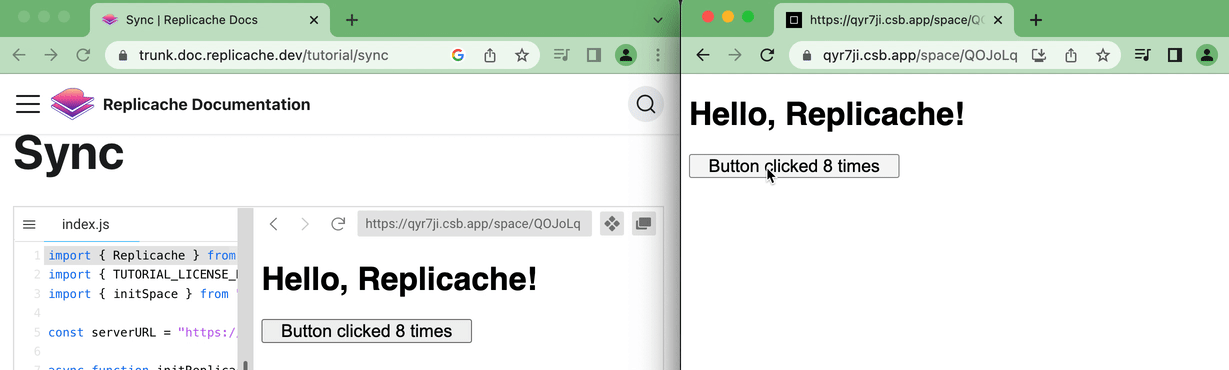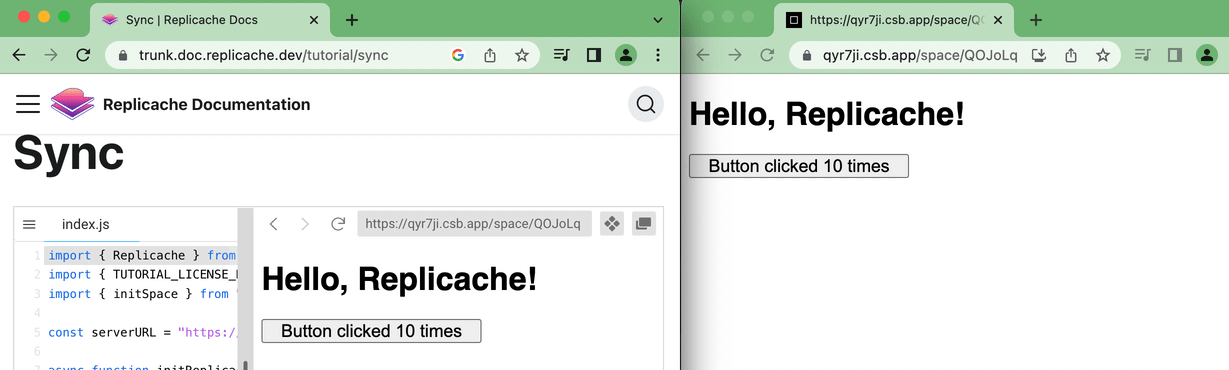 Once you finish, your app will have these features: * Realtime collaboration * Instant (optimistic) mutations * Rollback of optimistic UI when server mutations fail * Offline support You will also have a good understanding of Replicache's key concepts of * Mutations * Subscriptions * Synchronization If you’d prefer to learn more about how Replicache works first, see How Replicache Works. Or if you want to jump right in with a working template, see Todo Examples. --- ## Page: https://doc.replicache.dev/tutorial/constructing-replicache The Replicache constructor requires `name` and `licenseKey`. Replicache stores data persistently in the browser using IndexedDB. Instances that have the same `name` share storage. You should typically use the logged-in user's ID as the `name`, to keep their storage separate from any other users on the same device. For licenseKey, this sample uses a `TUTORIAL_LICENSE_KEY`. This license key is intended for tutorials in Replicache's documentation. To build your own Replicache apps later, you'll need to create your own license key. ## Challenge Get your own license key and use it here instead of `TUTORIAL_LICENSE_KEY`. --- ## Page: https://doc.replicache.dev/tutorial/adding-mutators * * Hello, Replicache * Adding Mutators _Mutators_ are how you change data in Replicache. Mutators are arbitrary functions that run once on the client immediately (aka “optimistically”), **and then run again later on the server** (”authoritatively”) during sync. Replicache queues mutations locally until the server acknowledges them during sync. Once the authoritative server result is known, Replicache reverts the optimistic version completely. For a deeper understanding of how the authoritative server works please read about synchronization. Mutators are fast Although the methods of `tx` are marked `async`, they almost always responds instantly (in the same event, < 1ms after call). The only reason access is async is for the rare case when Replicache must load data from local storage, such as at startup. Replicache is designed to be memory-fast and you should not need additional layers of caching above it. See performance for more information. ## Challenge Try adding your own multiply mutator. Previous Constructing Replicache Next Subscriptions --- ## Page: https://doc.replicache.dev/tutorial/subscriptions * * Hello, Replicache * Subscriptions _Subscriptions_ work similarly to other reactive JS frameworks. You can subscribe to a _query_ of Replicache and you will get notified when that query changes for any reason — either because of local optimistic changes, or because of sync. Subscriptions are Fast Replicache goes to significant trouble to make reactive renders efficient: * Replicache only calls the query function (the parameter to subscribe) when any of the keys it accessed last time change. * The `onData` callback is only called when the result of the query function changes. * Replicache will usually return objects with the same identity across queries, so you can use things like React’s `useMemo` to avoid re-renders. ## Challenge Modify the sample to increment by zero, and verify that the `onData` callback is not called. This is because even though the `count` key was re-written, its value didn't change. So Replicache didn't call the `onData` callback. Previous Adding Mutators Next Sync --- ## Page: https://doc.replicache.dev/tutorial/sync Finally, let’s start syncing our changes to the server! Replicache can sync with any server that implements the Replicache sync protocol. You can learn how to build such a server in the BYOB Tutorial. For now, we’ll just connect to an existing server by adding `pushURL` and `pullURL` parameters to the constructor. **Copy the preview URL (i.e. xxxxx.csb.app/space/123) into a different tab or browser, and click increment to see the two tabs sync.** Spaces What's that `initSpace()` call? For each run of this demo, we create a new _space_ on the server to store data in. This ensures each visitor to this demo sees only their own counts and isn't confused by seeing other users incrementing the count at the same time. To support realtime updates, most Replicache server support an optional _poke channel_. Replicache _pokes_ are zero-length messages that serve as a hint from server to clients that a space has changed and that the clients should pull again soon. This sample server implements a poke channel using Server-Sent Events. For a deeper understanding of how poke works please refer to our poke documentation. ## Challenge Replicache mutators are not required to compute the same result on the client as the server. This is a feature! The server can have different or better information than the client. Also, this prevents clients from lying or cheating. Try modifying your increment mutator to compute an incorrect result. You will see the incorrect result momentarily on the client or for as long as you are offline. But after sync, the clients snaps into alignment with the correct answer from the server automatically. --- ## Page: https://doc.replicache.dev/tutorial/next-steps Congratulations! You should now understand the basics of using Replicache on the client. From here, you have a number of options: * **Browse Examples** - Check out our example todo apps, built on a variety of stacks. Tinker with Replicache by starting with a working example. * **Build Your Own Backend** - Continue the fun and learn how to build your own Replicache server from scratch. * **Learn More about How Replicache Works** - Read the Replicache design doc for a deep dive in how Replicache does its thing. --- ## Page: https://doc.replicache.dev/examples/todo This page contains several different implementations of the same simple todo app, demonstrating different ways to build a Replicache app. You can study them as an example of how to use a particular technique, or just clone them to play with a complete working app, before diving into building your own server.  ### todo-nextjs **Frontend:** Next.js **Backend:** Next.js/Vercel **Mutators:** Shared **Database:** Supabase **Strategy:** Global Versioning **Pokes:** Supabase Realtime ### todo-wc **Frontend:** Web Components / Vanilla JS **Backend:** Node.js/Express **Mutators:** Shared **Database:** Postgres **Strategy:** Per-Space Versioning **Pokes:** Server-Sent Events ### todo-row-versioning **Frontend:** React **Backend:** Node.js/Express **Mutators:** Unshared **Database:** Postgres **Strategy:** Row Versioning **Pokes:** Server-Sent Events --- ## Page: https://doc.replicache.dev/byob/intro This guide walks you through the steps required to build a complete Replicache app, including the backend, from scratch. 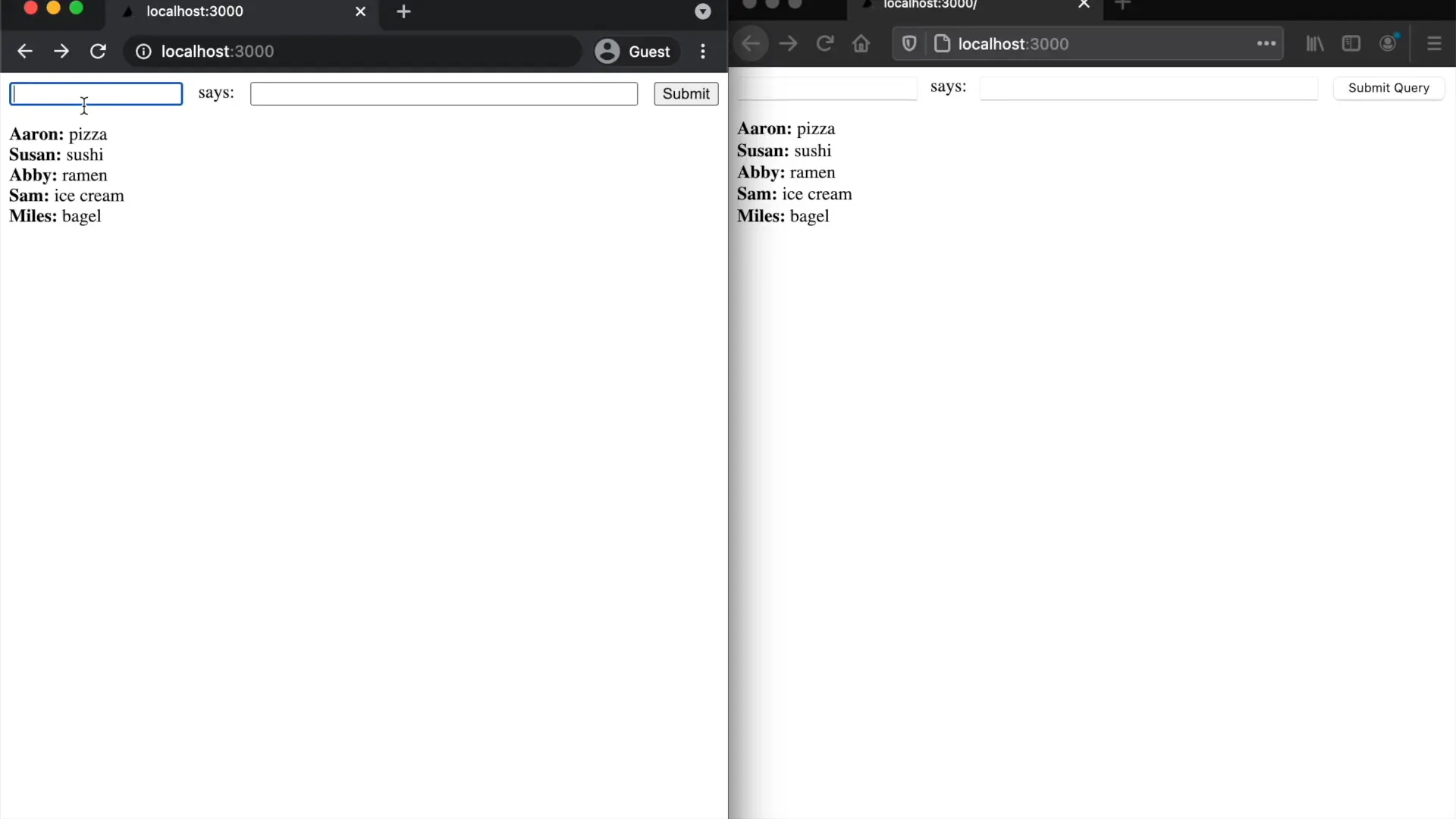 You can follow the steps exactly to end up with a simple chat app, or use them as guide to build your own Replicache-enabled app. ## Prerequisites You need Node.js, version 16.20.1 or higher to get started. You should also already understand How Replicache Works at a high level. ## Next Ready? Let's install Replicache and get started. --- ## Page: https://doc.replicache.dev/strategies/overview ## Backend Strategies Replicache defines abstract push and pull endpoints that servers must implement to sync. There are a number of possible strategies to implement these endpoints with different tradeoffs. The main difference between the strategies is how they calcuate the `patch` required by the pull endpoint. Different approaches require different state to be stored in the backend database, and different logic in the push and pull endpoints. Also some use-cases are only supported well with some strategies. Notably: * **Read Auth:** When not all data is accessible to all users. In an application like Google Docs, read authorization is required to implement the fact that a private doc must be shared with you before you can access it. * **Partial Sync:** When a user only syncs _some_ of the data they have access to. In an application like GitHub, each user has access to many GB of data, but only a small subset of that should be synced to the client at any point in time. Here are the strategies in increasing order of implementation difficulty: ## 🤪 Reset Strategy * **When to use:** For apps with very small amounts of data, or where the data changes infrequently. Also useful for learning Replicache. * **Implementation:** 👍🏼 Easy. * **Performance:** 👎🏼 Each pull computes and retransmits the entire client view. * **Read Auth:** 👍🏼 Easy. * **Partial sync:** 👍🏼 Easy. **Get started with the Reset Strategy →** ## 🌏 Global Version Strategy * **When to use:** Simple apps with low concurrency, and where all data is synced to all users. * **Performance:** 👎🏼 Limited to about 50 pushes/second across entire app. * **Implementation:** 👍🏼 Easy. * **Read Auth:** 👎🏼 Difficult. * **Partial sync:** 👎🏼 Difficult. **Get started with the Global Version Strategy →** ## 🛸 Per-Space Version Strategy * **When to use:** Apps where data can be naturally partitioned into _spaces_, where all users in a space sync that space in its entirety. For example, in an app like GitHub, each repository might be a space. * **Performance:** 🤷♂️ Limited to about 50 pushes/second/space. * **Implementation:** 👍🏼 Easy. * **Read Auth:** 🤷♂️ You can restrict access to a space to certain users, but all users within a space see everything in that space. * **Partial sync:** 🤷♂️ You can choose which spaces to sync to each client, but within a space all data is synced. **Get started with the Per-Space Version Strategy →** ## 🚣♀️ Row Version Strategy * **When to use:** Apps that need greater performance, fine-grained read authorization, or partial sync that can't be served by per-space versioning. This is the most flexible and powerful strategy, but also the hardest to implement. * **Performance:** 👍🏼 Close to traditional web app. * **Implementation:** 👎🏼 Most difficult. * **Read Auth:** 👍🏼 Fully supported. Each individual data item can be authorized based on arbitrary code. * **Partial sync:** 👍🏼 Fully supported. Sync any arbitrary subset of the database based on any logic you like. **Get started with the Row Version Strategy →** --- ## Page: https://doc.replicache.dev/concepts/how-it-works note If your goal is to start using Replicache immediately without having to understand all the details, just read The Big Picture section and return to the other sections as needed. ## The Big Picture Replicache enables instantaneous UI and realtime updates by taking the server round-trip off the application’s critical path, and instead syncing data continuously in the background. The Replicache model has several parts: **Replicache**: an in-browser persistent key-value store that is git-like under the hood. Your application reads and writes to Replicache at memory-fast speed and those changes are synchronized to the server in the background. Synchronization is bidirectional, so in the background Replicache also pulls down changes that have happened on the server from other users or processes. The git-like nature of Replicache enables changes flowing down from the server to be merged with local changes in a principled fashion. A detailed understanding of how this works is not required to get started; if you wish, you can read more about it in the Sync Details section. **Your application**: your application stores its state in Replicache. The app is implemented in terms of: * _Mutators_: JavaScript functions encapsulating change and conflict resolution logic. A mutator transactionally reads and writes keys and values in Replicache. You might have a mutator to create a TODO item, or to mark an item done. * _Subscriptions_: subscriptions are how your app is notified about changes to Replicache. A subscription is a standing query that fires a notification when its results change. Your application renders UI directly from the results of subscription notifications. You might for example have a subscription that queries a list of items so your app gets notified when items are added, changed, or deleted. **Your server**: Your server has a datastore containing the canonical application state. For example, in our Repliear sample this is a Postgres database running on Heroku, but many other backend stacks are supported. The server provides up- and downstream endpoints that users’ Replicaches use to sync. * _Push (upstream)_: Replicache pushes changes to the push endpoint. This endpoint has a corresponding mutator for each one your application defines. Whereas the client-side mutator writes to the local Replicache, the push endpoint mutator writes to the canonical server-side datastore. Mutator code can optionally be shared between client and server if both sides are JavaScript, but this is not required. As we will see, changes (mutator invocations aka mutations) that have run locally against Replicache are re-run on the server when pushed. * _Pull (downstream)_: Replicache periodically fetches the latest canonical state that the server has from the pull endpoint. The endpoint returns an update from the state that the local Replicache has to the latest state the server has, in the form of a diff over the key-value space they both store. * _Poke_: While Replicache will by default pull at regular intervals, it is a better user experience to reflect changes in realtime from one user to the others. Therefore when data changes on the server, the server can send a _poke_ to Replicache telling it to initiate a pull. A poke is a contentless hint delivered over pubsub to all relevant Replicaches that they should pull. Pokes can be sent over any pubsub-like channel like Web Sockets or Server-Sent Events. 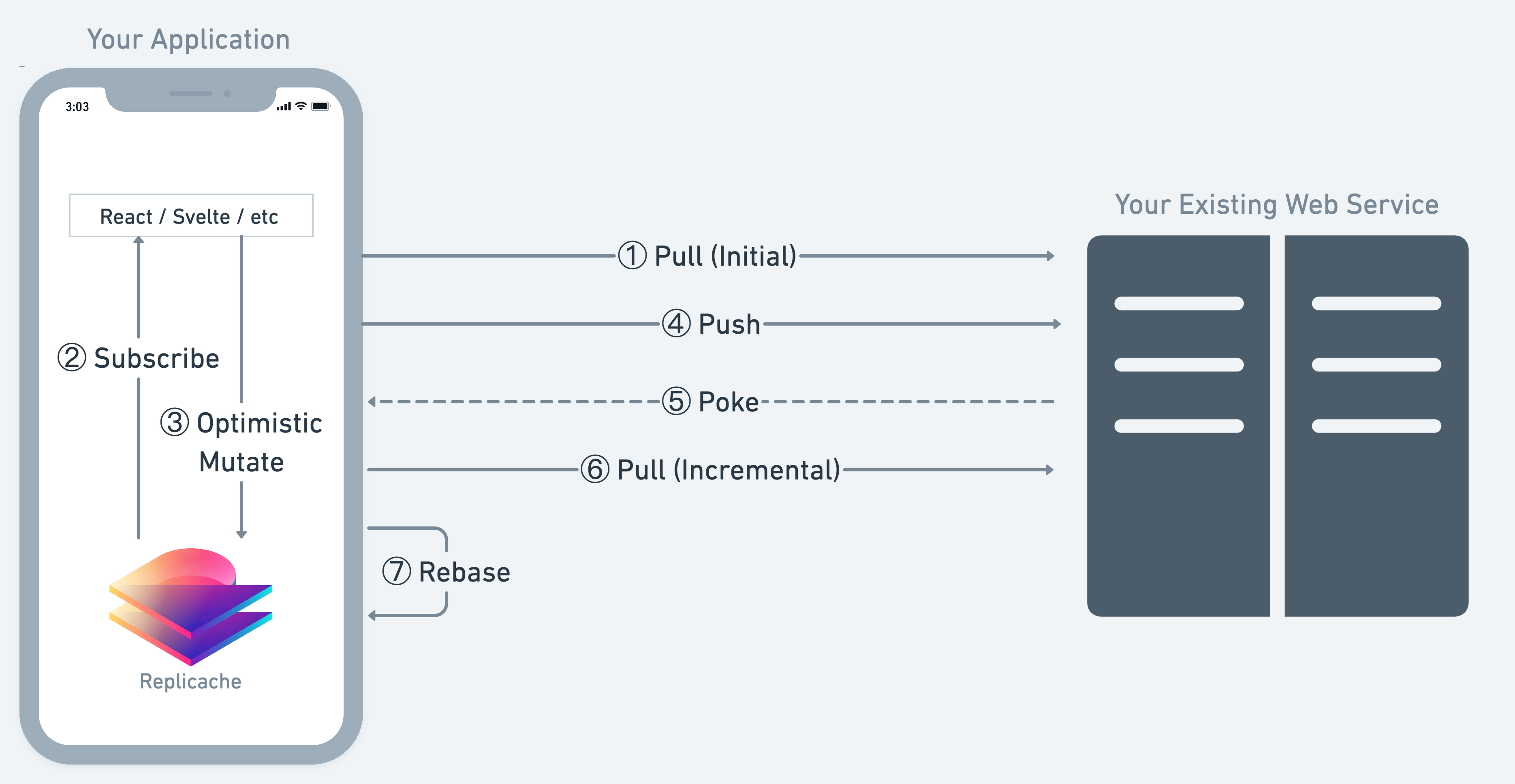 **Sync**: When a user takes an action in your app, the app invokes a mutator. The mutator modifies the local Replicache, and your subscriptions fire to update your UI. In the background, these changes are pushed to the server in batches, where they are run using the server-side mutators, updating the canonical datastore. When data changes on the server, the server pokes connected Replicaches. In response, Replicache pulls the new state from the server and reveals it to your app. Your subscriptions fire because the data have changed, which updates your app’s UI. 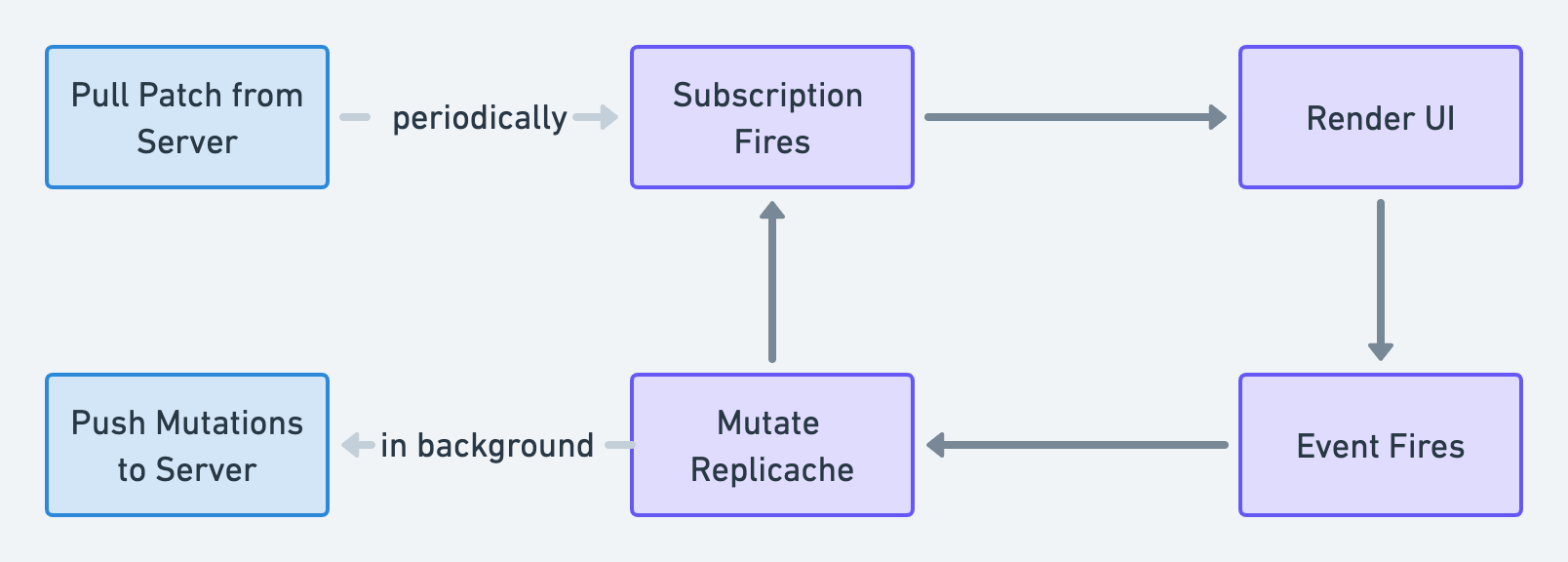 The sync process happens in a principled fashion such that: * local changes are guaranteed to get pushed to the server * changes pulled from the server are merged with local changes in a sensible and predictable way. For example if a user creates a TODO item, Replicache guarantees that all users including the author see it created exactly once, and with the same results. ## Clients, Client Groups, and Caches An instance of the Replicache class in memory is called a _client_. import {Replicache} from "replicache";const rep = new Replicache({ name: userID, ...});console.log(rep.clientID); A client is identified by a unique, randomly generated `clientID`. There is typically one client (instance of Replicache) per tab. A client is ephemeral, being instantiated for the lifetime of the application in the tab. The client provides fast access to and persistence for the keys and values used by the application. A _client group_ is a set of clients that share data locally. Changes made by one client are visible to other clients, even while offline. Client groups are identified by a unique, randomly generated `clientGroupID`. Under normal circumstances, all clients within the same browser profile are part of a single _client group_. For brief periods during schema migrations, two client groups can coexist in the same browser profile. The client group sits on top of an on-disk persistent _cache_ identified by the `name` parameter to the `Replicache` constructor. All clients in the group that have the same `name` share access to the same cache. caution It’s important that each user of your application uses a different Replicache `name`. That way, different users will have separate caches. This ensures that different users within the same browser profile never see or modify each others' data. ## The Client View Each client keeps an ordered map of key/value pairs called the _Client View_ that is persisted in the underlying cache. Client View keys are strings and the values are JSON-compatible values. The Client View is the application data that Replicache syncs with the server. We call it the "Client View" because different clients might have different views of the state of the server. For example, a user's Client View might contain per-user state that is only visible to them. The size of a Client View is limited primarily by browser policies. You can store hundreds of MB in a Replicache Client View without affecting performance significantly, though HTTP request limits to your endpoints might come into play. Access to the Client View is fast. Reads and writes generally have latency < 1ms and data can be scanned at over 500MB/s on most devices. You do not need to keep a separate copy of the client view in memory (e.g., `useState` in React). The intent is that you read data out of Replicache and directly render it. To make changes, you modify Replicache using mutators (see below). When mutators change keys or values in the Client View, Replicache fires subscriptions that cause the UI to re-read the relevant data and re-render the UI. ## Subscriptions UI is typically built using the `subscribe()` method (or `useSubscribe()` in React): const todos = useSubscribe(rep, async tx => { return await tx.scan({prefix: 'todo/'}).toArray();});return ( <ul> {todos.map(todo => ( <li key={todo.id}>{todo.text}</li> ))} </ul>); The subscribe method gets passed a function that receives a `ReadTransaction` parameter. You can do any number of reads from Replicache inside this function, and compute some result. Whenever the data in Replicache changes such that a subscription is potentially out of date — either because of a local/optimistic change or because of syncing with the server — the subscription function re-runs. If the result changes, the subscription fires and the UI re-renders. By using subscriptions to build your UI, you guarantee that the entire UI always correctly reflects the latest state, no matter why or how it changed. ## Mutations Mutations are the way that data changes in Replicache, and are at the core of how Replicache sync works. At startup, register one or more _mutators_ with Replicache. A mutator is a named JavaScript function that operates on Replicache. Both `createTodo` and `markTodoComplete` below are mutators. const rep = new Replicache({ ... mutators: { createTodo, markTodoComplete, },});async function createTodo(tx: WriteTransaction, todo: Todo) { await tx.set(`/todo/${todo.id}`, todo);}async function markTodoComplete(tx: WriteTransaction, {id, complete}: {id: string, complete: boolean}) { const key = `/todo/${id}`; const todo = await tx.get(key); if (!todo) { return; } todo.complete = complete; await tx.set(key, todo);} To change the Client View, call a mutator and pass it arguments: await rep.mutate.createTodo({id: nanoid(), text: "take out the trash"});...await rep.mutate.markTodoComplete({id: "t1", complete: true}); This applies the changes to the Client View, causing any relevant subscriptions to re-run and fire if necessary. In React, this will cause the dependent components to re-render automatically. Internally, calling a mutator also creates a _mutation_: a record of a mutator being called with specific arguments. For example, after the above code runs, Replicache will internally be tracking two mutations: [ {id: 1, name: "createTodo", args: {id: "t1", text: "take out the trash"}}, {id: 2, name: "markTodoComplete", args: {id: "t1", complete: true}},] Until the mutations above are pushed by Replicache to the server during sync they are _pending_ (optimistic). ## Sync Details The above sections describe how Replicache works on the client-side. This is all you need to know to get started using Replicache using the Todo starter app. That’s because the starter app includes a generic server that fully implements the sync protocol. However, to use Replicache well, it is important to understand how sync works conceptually. And you _need_ to know this if you plan to modify the server, use Replicache with your own existing backend, or swap out the datastore. note In the following discussion we use "state" as shorthand for "the state of the key-value space", the set of keys that exist and their values. We often say that some state is used as a "base" for a change, or that a change is applied "on top of" a state. By this we simply mean that the change is made with the base state as its starting input. ### The Replicache Sync Model The "sync problem" that Replicache solves is how to enable decoupled, concurrent changes to a key-value space across many clients and a server such that: 1. the key-value space kept by the server is the canonical source of truth to which all clients converge. 2. local changes to the space in a client are immediately (optimistically) visible to the app that is using that client. We call these changes _speculative_, as opposed to canonical. 3. local changes can be applied (in the background) on the server such that: * a change is applied exactly once on the server, with predicable results and * new changes that have been applied on the server can sensibly be merged with the local state of the key-value space The last item on the list above merits taking a moment to expand upon and internalize. In order to sensibly merge new state from the server with local changes, the client must account for any or all of the following cases: * A local change in the client has not yet been applied to the server. In this case, Replicache needs to ensure that this local change is not "lost" from the app's UI in the process of updating to the new server state. In fact, as we will see, Replicache effectively _re-runs_ such changes "on top of" the new state from the server before revealing the new state to the app. * A local change in the client _has already_ been applied to the server in the background. Yay. The effects of this local change are visible in the new state from the server, so Replicache does not need to re-run the change on the new state. In fact, it must not: if it did, the change would be applied twice, once on the server and then again by the client on top of the new state already containing its effects. * Some other client or process changed part of the key-value space that the client has. Since the server's state is canonical and the client's is speculative, any local changes not yet applied on the server must be re-applied on top of the new canonical state before it is revealed. This _could_ modify the effect of the local unsynchronized change, for example if some other user marked an issue "Complete" but locally we have an unsynchronized change that marks it "Will not fix". Some logic needs to run to resolve the merge conflict. (Spoiler: mutators contain this logic. More on this below.) How Replicache implements these steps is explained next. ### Local execution When a mutator is invoked, Replicache applies its changes to the local Client View. It also queues a corresponding pending mutation record to be pushed to the server, and this record is persisted in case the tab closes before it can be pushed. When created, a mutation is assigned a _mutation id_, a sequential integer uniquely identifying the mutation in this client. The mutation id also describes a causal order to mutations from this client, and that order is respected by the server. ### Push Pending mutations are sent in batches to the _push endpoint_ on your server (conventionally called `replicache-push`). Mutations carry exactly the information the server needs to execute the mutator that was invoked on the client. That is, the order in which the mutations were invoked (in order of mutation id), the clientID that the mutation was created on, the name of the mutator invoked, and its arguments. The push endpoint executes the pushed mutations in order by executing the named mutator with the given arguments, canonicalizing the mutations' effects in the server's state. It also updates the corresponding last mutation id for the client that is pushing. This is the high water mark of mutations seen from that client and is information used by the client during pull so that it knows which mutations need to be re-run on new server state (namely, those with mutation ids > the server's last mutation id for the client). #### Speculative Execution and Confirmation It is important to understand that the push endpoint is _not necessarily_ expected to compute the same result that the mutator on the client did. This is a feature. The server may have newer or different state than the client has. That’s fine —- the pending mutations applied on the client are _speculative_ until applied on the server. In Replicache, the server is authoritative. The client-side mutators create speculative results, then the mutations are pushed and executed by the server creating _confirmed_, canonical results. The confirmed results are later pulled by the client, with the server-calculated state taking precedence over the speculative result. This precedence happens because, once confirmed by the server, a speculative mutation is no longer re-run by the client on new server state. ### Pull Periodically, Replicache requests an update to the Client View by calling the _pull endpoint_ (conventionally, `replicache-pull`). The pull request contains a _cookie_ and a _clientGroupID_, and the response contains a new _cookie,_ a _patch,_ and a set of _lastMutationIDChanges_. The cookie is a value opaque to the client identifying the canonical server state that the client has. It is used by the server during pull to compute a patch that brings the client’s state up to date with the server’s. In its simplest implementation, the cookie encapsulates the entire state of all data in the client view. You can think of this as a global “version” of the data in the backend datastore. More fine-grained cookie versioning strategies are possible though. See \[/concepts/strategies/overview\](Backend Strategies) for more information. The lastMutationIDChanges returned in the response tells Replicache which mutations have been confirmed by the server for each client in the group. Those mutations have their effects, if any, represented in the patch. Replicache therefore discards any pending mutations it has for each client with id ≤ lastMutationID. Those mutations are no longer pending, they are confirmed. ### Rebase Once the client receives a pull response, it needs to apply the patch to the local state to bring the client's state up to date with that of the server. But it can’t apply the patch to the _current_ local state, because that state likely includes changes caused by pending mutations. It's not clear what a general strategy would be for applying the patch on top of local changes. So it doesn't. Instead, hidden from the application's view, it _rewinds_ the state of the Client View to the last version it got from the server, applies the patch to get to the state the server currently has, and then replays any pending mutations on top. It then atomically reveals this new state to the app, which triggers subscriptions and the UI to re-render. In order to support the capability to rewind the Client View and apply changes out of view of the app, Replicache is modeled under the hood like git. It maintains historical versions of the Client View and, like git branches, has the ability to work with a historical version of the Client View behind the scenes. So when the client pulls new state from the server, it forks from the previous Client View received from the server, applies the patch, _rebases_ (re-runs) pending mutations, and then reveals the new branch to the app. note It’s possible and common for mutations to calculate a different effect when they run during rebase. For example, a calendar invite may run during rebase and find that the booked room is no longer available. In this case, it may add an error message to the client view that the UI displays, or just book some different but similar room. ### Poke (optional) Replicache can call pull on a timer (see `pullInterval`) but this is really only used in development. It’s much more common for the server to **tell** potentially-affected clients when a good time to pull is. This is done by sending the client a hint that it should pull soon. This hint message is called a _poke_. The poke doesn’t contain any actual data. All the poke does is tell the client that it should pull again soon. There are many ways to send pokes. For example, the replicache-todo starter app does it using Server-Sent Events. However, you can also use Web Sockets, or a push service like Pusher. ### Conflict Resolution The potential for merge conflicts is unavoidable in a system like Replicache. Clients and the server operate on the key-value space independently, and all but the most trivial applications will feature concurrent changes by different clients to overlapping parts of the keyspace. During push and pull, these changes have to _merge_ in a way that is predictable to the developer and makes sense for the application. For example, a meeting room reservation app might resolve a room reservation conflict by allocating a room to the first party to land the reservation. One change wins, the other loses. However, the preferred merge strategy in a collaborative Todo app where two parties concurrently add items to a list might be to append both of the items. Both changes "win." The potential for merge conflicts arises in Replicache in two places. First, when a speculative mutation from a client is applied on the server. The state on the server that the mutation operates on could be different from the state it was originally applied on in the client. Second, when a speculative mutation is rebased in the client. The mutation could be re-applied on state that is different from the previous time it ran. Replicache embraces the application-specific nature of conflict resolution by enabling developers to express their conflict resolution intentions programmatically. Mutators are arbitrary JavaScript code, so they can programmatically express whatever conflict resolution policy makes the most sense for the application. To take the previous two examples: * a `reserveRoom` mutator when run locally for the first time might find a room in state `AVAILABLE`, and mark it as `RESERVED` for the user. Later, when run on the server, the mutator might find that the room status is already `RESERVED` for a different user. The server-executed mutator here takes a different branch than it did when run locally: it leaves the room reservation untouched and instead sets a bit in the user's state indicating that their attempt to book the room failed. When the user's client next pulls, that bit is included in the Client View. The app presumably has a subscription to watch for this bit being set, and the UI shows the room as unavailable and notifies the user that the reservation failed. * an `addItem` mutator for a Todo app might not require any conflict resolution whatsover. Its implementation can simply append the new item to the end of whatever it finds on the list! We believe the Replicache model for dealing with conflicts — to have defensively written, programmatic mutation logic that is replayed atop the latest state — leads to few real problems in practice. Our experience is that it preserves expressiveness of the data model and is far easier to reason about than other general models for avoiding or minimizing conflicts. --- ## Page: https://doc.replicache.dev/api/ ## Classes * IDBNotFoundError * PullError * PushError * Replicache * TransactionClosedError ## Interfaces * AsyncIterableIteratorToArray * KVRead * KVStore * KVWrite * LogSink * ReadTransaction * ReplicacheOptions * RequestOptions * ScanResult * SubscribeOptions * WriteTransaction ## Type Aliases ### ClientGroupID Ƭ **ClientGroupID**: `string` The ID describing a group of clients. All clients in the same group share a persistent storage (IDB). * * * ### ClientID Ƭ **ClientID**: `string` The ID describing a client. * * * ### ClientStateNotFoundResponse Ƭ **ClientStateNotFoundResponse**: `Object` In certain scenarios the server can signal that it does not know about the client. For example, the server might have lost all of its state (this might happen during the development of the server). #### Type declaration | Name | Type | | --- | --- | | `error` | `"ClientStateNotFound"` | * * * ### Cookie Ƭ **Cookie**: `null` | `string` | `number` | `ReadonlyJSONValue` & { `order`: `number` | `string` } A cookie is a value that is used to determine the order of snapshots. It needs to be comparable. This can be a `string`, `number` or if you want to use a more complex value, you can use an object with an `order` property. The value `null` is considered to be less than any other cookie and it is used for the first pull when no cookie has been set. The order is the natural order of numbers and strings. If one of the cookies is an object then the value of the `order` property is treated as the cookie when doing comparison. If one of the cookies is a string and the other is a number, the number is fist converted to a string (using `toString()`). * * * ### CreateIndexDefinition Ƭ **CreateIndexDefinition**: `IndexDefinition` & { `name`: `string` } * * * ### CreateKVStore Ƭ **CreateKVStore**: (`name`: `string`) => `KVStore` #### Type declaration ▸ (`name`): `KVStore` Factory function for creating KVStore instances. The name is used to identify the store. If the same name is used for multiple stores, they should share the same data. It is also desirable to have these stores share an RWLock. ##### Parameters | Name | Type | | --- | --- | | `name` | `string` | ##### Returns `KVStore` * * * ### DeepReadonly Ƭ **DeepReadonly**<`T`\>: `T` extends `null` | `boolean` | `string` | `number` | `undefined` ? `T` : `DeepReadonlyObject`<`T`\> Basic deep readonly type. It works for JSONValue. #### Type parameters | Name | | --- | | `T` | * * * ### DeepReadonlyObject Ƭ **DeepReadonlyObject**<`T`\>: { readonly \[K in keyof T\]: DeepReadonly<T\[K\]\> } #### Type parameters | Name | | --- | | `T` | * * * ### DropDatabaseOptions Ƭ **DropDatabaseOptions**: `Object` Options for `dropDatabase` and `dropAllDatabases`. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `kvStore?` | `"idb"` | `"mem"` | `KVStoreProvider` | Allows providing a custom implementation of the underlying storage layer. Default is `'idb'`. | | `logLevel?` | `LogLevel` | Determines how much logging to do. When this is set to `'debug'`, Replicache will also log `'info'` and `'error'` messages. When set to `'info'` we log `'info'` and `'error'` but not `'debug'`. When set to `'error'` we only log `'error'` messages. Default is `'info'`. | | `logSinks?` | `LogSink`\[\] | Enables custom handling of logs. By default logs are logged to the console. If you would like logs to be sent elsewhere (e.g. to a cloud logging service like DataDog) you can provide an array of LogSinks. Logs at or above logLevel are sent to each of these LogSinks. If you would still like logs to go to the console, include `consoleLogSink` in the array. `ts logSinks: [consoleLogSink, myCloudLogSink],` Default is `[consoleLogSink]`. | * * * ### DropKVStore Ƭ **DropKVStore**: (`name`: `string`) => `Promise`<`void`\> #### Type declaration ▸ (`name`): `Promise`<`void`\> Function for deleting KVStore instances. The name is used to identify the store. If the same name is used for multiple stores, they should share the same data. ##### Parameters | Name | Type | | --- | --- | | `name` | `string` | ##### Returns `Promise`<`void`\> * * * ### ExperimentalDiff Ƭ **ExperimentalDiff**: `ExperimentalIndexDiff` | `ExperimentalNoIndexDiff` Describes the changes that happened to Replicache after a WriteTransaction was committed. This type is experimental and may change in the future. * * * ### ExperimentalDiffOperation Ƭ **ExperimentalDiffOperation**<`Key`\>: `ExperimentalDiffOperationAdd`<`Key`\> | `ExperimentalDiffOperationDel`<`Key`\> | `ExperimentalDiffOperationChange`<`Key`\> The individual parts describing the changes that happened to the Replicache data. There are three different kinds of operations: * `add`: A new entry was added. * `del`: An entry was deleted. * `change`: An entry was changed. This type is experimental and may change in the future. #### Type parameters | Name | | --- | | `Key` | * * * ### ExperimentalDiffOperationAdd Ƭ **ExperimentalDiffOperationAdd**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `newValue` | `Value` | | `op` | `"add"` | * * * ### ExperimentalDiffOperationChange Ƭ **ExperimentalDiffOperationChange**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `newValue` | `Value` | | `oldValue` | `Value` | | `op` | `"change"` | * * * ### ExperimentalDiffOperationDel Ƭ **ExperimentalDiffOperationDel**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `oldValue` | `Value` | | `op` | `"del"` | * * * ### ExperimentalIndexDiff Ƭ **ExperimentalIndexDiff**: readonly `ExperimentalDiffOperation`<`IndexKey`\>\[\] This type is experimental and may change in the future. * * * ### ExperimentalNoIndexDiff Ƭ **ExperimentalNoIndexDiff**: readonly `ExperimentalDiffOperation`<`string`\>\[\] This type is experimental and may change in the future. * * * ### ExperimentalWatchCallbackForOptions Ƭ **ExperimentalWatchCallbackForOptions**<`Options`\>: `Options` extends `ExperimentalWatchIndexOptions` ? `ExperimentalWatchIndexCallback` : `ExperimentalWatchNoIndexCallback` #### Type parameters | Name | Type | | --- | --- | | `Options` | extends `ExperimentalWatchOptions` | * * * ### ExperimentalWatchIndexCallback Ƭ **ExperimentalWatchIndexCallback**: (`diff`: `ExperimentalIndexDiff`) => `void` #### Type declaration ▸ (`diff`): `void` Function that gets passed into experimentalWatch when doing a watch on a secondary index map and gets called when the data in Replicache changes. This type is experimental and may change in the future. ##### Parameters | Name | Type | | --- | --- | | `diff` | `ExperimentalIndexDiff` | ##### Returns `void` * * * ### ExperimentalWatchIndexOptions Ƭ **ExperimentalWatchIndexOptions**: `ExperimentalWatchNoIndexOptions` & { `indexName`: `string` } Options object passed to experimentalWatch. This is for an index watch. * * * ### ExperimentalWatchNoIndexCallback Ƭ **ExperimentalWatchNoIndexCallback**: (`diff`: `ExperimentalNoIndexDiff`) => `void` #### Type declaration ▸ (`diff`): `void` Function that gets passed into experimentalWatch and gets called when the data in Replicache changes. This type is experimental and may change in the future. ##### Parameters | Name | Type | | --- | --- | | `diff` | `ExperimentalNoIndexDiff` | ##### Returns `void` * * * ### ExperimentalWatchNoIndexOptions Ƭ **ExperimentalWatchNoIndexOptions**: `Object` Options object passed to experimentalWatch. This is for a non index watch. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `initialValuesInFirstDiff?` | `boolean` | When this is set to `true` (default is `false`), the `watch` callback will be called once asynchronously when watch is called. The arguments in that case is a diff where we consider all the existing values in Replicache as being added. | | `prefix?` | `string` | When provided, the `watch` is limited to changes where the `key` starts with `prefix`. | * * * ### ExperimentalWatchOptions Ƭ **ExperimentalWatchOptions**: `ExperimentalWatchIndexOptions` | `ExperimentalWatchNoIndexOptions` Options for experimentalWatch. This interface is experimental and may change in the future. * * * ### GetIndexScanIterator Ƭ **GetIndexScanIterator**: (`indexName`: `string`, `fromSecondaryKey`: `string`, `fromPrimaryKey`: `string` | `undefined`) => `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> #### Type declaration ▸ (`indexName`, `fromSecondaryKey`, `fromPrimaryKey`): `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> When using makeScanResult this is the type used for the function called when doing a scan with an `indexName`. ##### Parameters | Name | Type | Description | | --- | --- | --- | | `indexName` | `string` | The name of the index we are scanning over. | | `fromSecondaryKey` | `string` | The `fromSecondaryKey` is computed by `scan` and is the secondary key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanIndexOptions. | | `fromPrimaryKey` | `string` | `undefined` | The `fromPrimaryKey` is computed by `scan` and is the primary key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanIndexOptions. | ##### Returns `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> * * * ### GetScanIterator Ƭ **GetScanIterator**: (`fromKey`: `string`) => `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> #### Type declaration ▸ (`fromKey`): `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> This is called when doing a scan without an `indexName`. ##### Parameters | Name | Type | Description | | --- | --- | --- | | `fromKey` | `string` | The `fromKey` is computed by `scan` and is the key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanNoIndexOptions. | ##### Returns `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> * * * ### HTTPRequestInfo Ƭ **HTTPRequestInfo**: `Object` #### Type declaration | Name | Type | | --- | --- | | `errorMessage` | `string` | | `httpStatusCode` | `number` | * * * ### IndexDefinition Ƭ **IndexDefinition**: `Object` The definition of a single index. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `allowEmpty?` | `boolean` | If `true`, indexing empty values will not emit a warning. Defaults to `false`. | | `jsonPointer` | `string` | A JSON Pointer pointing at the sub value inside each value to index over. For example, one might index over users' ages like so: `{prefix: '/user/', jsonPointer: '/age'}` | | `prefix?` | `string` | The prefix, if any, to limit the index over. If not provided the values of all keys are indexed. | * * * ### IndexDefinitions Ƭ **IndexDefinitions**: `Object` An object as a map defining the indexes. The keys are the index names and the values are the index definitions. #### Index signature ▪ \[name: `string`\]: `IndexDefinition` * * * ### IndexKey Ƭ **IndexKey**: readonly \[secondary: string, primary: string\] When using indexes the key is a tuple of the secondary key and the primary key. * * * ### IterableUnion Ƭ **IterableUnion**<`T`\>: `AsyncIterable`<`T`\> | `Iterable`<`T`\> #### Type parameters | Name | | --- | | `T` | * * * ### JSONObject Ƭ **JSONObject**: `Object` A JSON object. This is a map from strings to JSON values or `undefined`. We allow `undefined` values as a convenience... but beware that the `undefined` values do not round trip to the server. For example: // Time t1await tx.set('a', {a: undefined});// time passes, in a new transactionconst v = await tx.get('a');console.log(v); // either {a: undefined} or {} #### Index signature ▪ \[key: `string`\]: `JSONValue` | `undefined` * * * ### JSONValue Ƭ **JSONValue**: `null` | `string` | `boolean` | `number` | `JSONValue`\[\] | `JSONObject` The values that can be represented in JSON * * * ### KVStoreProvider Ƭ **KVStoreProvider**: `Object` Provider for creating and deleting KVStore instances. #### Type declaration | Name | Type | | --- | --- | | `create` | `CreateKVStore` | | `drop` | `DropKVStore` | * * * ### KeyTypeForScanOptions Ƭ **KeyTypeForScanOptions**<`O`\>: `O` extends `ScanIndexOptions` ? `IndexKey` : `string` If the options contains an `indexName` then the key type is a tuple of secondary and primary. #### Type parameters | Name | Type | | --- | --- | | `O` | extends `ScanOptions` | * * * ### LogLevel Ƭ **LogLevel**: `"error"` | `"info"` | `"debug"` The different log levels. This is used to determine how much logging to do. `'error'` > `'info'` > `'debug'`... meaning `'error'` has highest priority and `'debug'` lowest. * * * ### MaybePromise Ƭ **MaybePromise**<`T`\>: `T` | `Promise`<`T`\> #### Type parameters | Name | | --- | | `T` | * * * ### MutationV0 Ƭ **MutationV0**: `Object` Mutation describes a single mutation done on the client. This is the legacy version (V0) and it is used when recovering mutations from old clients. #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `id` | `number` | | `name` | `string` | | `timestamp` | `number` | * * * ### MutationV1 Ƭ **MutationV1**: `Object` Mutation describes a single mutation done on the client. #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `clientID` | `ClientID` | | `id` | `number` | | `name` | `string` | | `timestamp` | `number` | * * * ### MutatorDefs Ƭ **MutatorDefs**: `Object` #### Index signature ▪ \[key: `string`\]: (`tx`: `WriteTransaction`, `args?`: `any`) => `MutatorReturn` * * * ### MutatorReturn Ƭ **MutatorReturn**<`T`\>: `MaybePromise`<`T` | `void`\> #### Type parameters | Name | Type | | --- | --- | | `T` | extends `ReadonlyJSONValue` = `ReadonlyJSONValue` | * * * ### PatchOperation Ƭ **PatchOperation**: { `key`: `string` ; `op`: `"put"` ; `value`: `ReadonlyJSONValue` } | { `key`: `string` ; `op`: `"del"` } | { `op`: `"clear"` } This type describes the patch field in a PullResponse and it is used to describe how to update the Replicache key-value store. * * * ### PendingMutation Ƭ **PendingMutation**: `Object` #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `clientID` | `ClientID` | | `id` | `number` | | `name` | `string` | * * * ### Poke Ƭ **Poke**: `Object` #### Type declaration | Name | Type | | --- | --- | | `baseCookie` | `ReadonlyJSONValue` | | `pullResponse` | `PullResponseV1` | * * * ### PullRequest Ƭ **PullRequest**: `PullRequestV1` | `PullRequestV0` The JSON value used as the body when doing a POST to the pull endpoint. * * * ### PullRequestV0 Ƭ **PullRequestV0**: `Object` The JSON value used as the body when doing a POST to the pull endpoint. This is the legacy version (V0) and it is still used when recovering mutations from old clients. #### Type declaration | Name | Type | | --- | --- | | `clientID` | `ClientID` | | `cookie` | `ReadonlyJSONValue` | | `lastMutationID` | `number` | | `profileID` | `string` | | `pullVersion` | `0` | | `schemaVersion` | `string` | * * * ### PullRequestV1 Ƭ **PullRequestV1**: `Object` The JSON value used as the body when doing a POST to the pull endpoint. #### Type declaration | Name | Type | | --- | --- | | `clientGroupID` | `ClientGroupID` | | `cookie` | `Cookie` | | `profileID` | `string` | | `pullVersion` | `1` | | `schemaVersion` | `string` | * * * ### PullResponse Ƭ **PullResponse**: `PullResponseV1` | `PullResponseV0` * * * ### PullResponseOKV0 Ƭ **PullResponseOKV0**: `Object` The shape of a pull response under normal circumstances. #### Type declaration | Name | Type | | --- | --- | | `cookie?` | `ReadonlyJSONValue` | | `lastMutationID` | `number` | | `patch` | `PatchOperation`\[\] | * * * ### PullResponseOKV1 Ƭ **PullResponseOKV1**: `Object` The shape of a pull response under normal circumstances. #### Type declaration | Name | Type | | --- | --- | | `cookie` | `Cookie` | | `lastMutationIDChanges` | `Record`<`ClientID`, `number`\> | | `patch` | `PatchOperation`\[\] | * * * ### PullResponseV0 Ƭ **PullResponseV0**: `PullResponseOKV0` | `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` PullResponse defines the shape and type of the response of a pull. This is the JSON you should return from your pull server endpoint. * * * ### PullResponseV1 Ƭ **PullResponseV1**: `PullResponseOKV1` | `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` PullResponse defines the shape and type of the response of a pull. This is the JSON you should return from your pull server endpoint. * * * ### Puller Ƭ **Puller**: (`requestBody`: `PullRequest`, `requestID`: `string`) => `Promise`<`PullerResult`\> #### Type declaration ▸ (`requestBody`, `requestID`): `Promise`<`PullerResult`\> Puller is the function type used to do the fetch part of a pull. Puller needs to support dealing with pull request of version 0 and 1. Version 0 is used when doing mutation recovery of old clients. If a PullRequestV1 is passed in the n a PullerResultV1 should be returned. We do a runtime assert to make this is the case. If you do not support old clients you can just throw if `pullVersion` is `0`, ##### Parameters | Name | Type | | --- | --- | | `requestBody` | `PullRequest` | | `requestID` | `string` | ##### Returns `Promise`<`PullerResult`\> * * * ### PullerResult Ƭ **PullerResult**: `PullerResultV1` | `PullerResultV0` * * * ### PullerResultV0 Ƭ **PullerResultV0**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PullResponseV0` | * * * ### PullerResultV1 Ƭ **PullerResultV1**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PullResponseV1` | * * * ### PushRequest Ƭ **PushRequest**: `PushRequestV0` | `PushRequestV1` * * * ### PushRequestV0 Ƭ **PushRequestV0**: `Object` The JSON value used as the body when doing a POST to the push endpoint. This is the legacy version (V0) and it is still used when recovering mutations from old clients. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `clientID` | `ClientID` | \- | | `mutations` | `MutationV0`\[\] | \- | | `profileID` | `string` | \- | | `pushVersion` | `0` | \- | | `schemaVersion` | `string` | `schemaVersion` can optionally be used to specify to the push endpoint version information about the mutators the app is using (e.g., format of mutator args). | * * * ### PushRequestV1 Ƭ **PushRequestV1**: `Object` The JSON value used as the body when doing a POST to the push endpoint. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `clientGroupID` | `ClientGroupID` | \- | | `mutations` | `MutationV1`\[\] | \- | | `profileID` | `string` | \- | | `pushVersion` | `1` | \- | | `schemaVersion` | `string` | `schemaVersion` can optionally be used to specify to the push endpoint version information about the mutators the app is using (e.g., format of mutator args). | * * * ### PushResponse Ƭ **PushResponse**: `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` The response from a push can contain information about error conditions. * * * ### Pusher Ƭ **Pusher**: (`requestBody`: `PushRequest`, `requestID`: `string`) => `Promise`<`PusherResult`\> #### Type declaration ▸ (`requestBody`, `requestID`): `Promise`<`PusherResult`\> Pusher is the function type used to do the fetch part of a push. The request is a POST request where the body is JSON with the type PushRequest. The return value should either be a HTTPRequestInfo or a PusherResult. The reason for the two different return types is that we didn't use to care about the response body of the push request. The default pusher implementation checks if the response body is JSON and if it matches the type PusherResponse. If it does, it is included in the return value. ##### Parameters | Name | Type | | --- | --- | | `requestBody` | `PushRequest` | | `requestID` | `string` | ##### Returns `Promise`<`PusherResult`\> * * * ### PusherResult Ƭ **PusherResult**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PushResponse` | * * * ### ReadonlyJSONObject Ƭ **ReadonlyJSONObject**: `Object` Like JSONObject but deeply readonly #### Index signature ▪ \[key: `string`\]: `ReadonlyJSONValue` | `undefined` * * * ### ReadonlyJSONValue Ƭ **ReadonlyJSONValue**: `null` | `string` | `boolean` | `number` | `ReadonlyArray`<`ReadonlyJSONValue`\> | `ReadonlyJSONObject` Like JSONValue but deeply readonly * * * ### ScanIndexOptions Ƭ **ScanIndexOptions**: `Object` Options for scan when scanning over an index. When scanning over and index you need to provide the `indexName` and the `start` `key` is now a tuple consisting of secondary and primary key #### Type declaration | Name | Type | Description | | --- | --- | --- | | `indexName` | `string` | Do a scan over a named index. The `indexName` is the name of an index defined when creating the Replicache instance using indexes. | | `limit?` | `number` | Only include up to `limit` results. | | `prefix?` | `string` | Only include results starting with the _secondary_ keys starting with `prefix`. | | `start?` | { `exclusive?`: `boolean` ; `key`: `ScanOptionIndexedStartKey` } | When provided the scan starts at this key. | | `start.exclusive?` | `boolean` | Whether the `key` is exclusive or inclusive. | | `start.key` | `ScanOptionIndexedStartKey` | \- | * * * ### ScanNoIndexOptions Ƭ **ScanNoIndexOptions**: `Object` Options for scan when scanning over the entire key space. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `limit?` | `number` | Only include up to `limit` results. | | `prefix?` | `string` | Only include keys starting with `prefix`. | | `start?` | { `exclusive?`: `boolean` ; `key`: `string` } | When provided the scan starts at this key. | | `start.exclusive?` | `boolean` | Whether the `key` is exclusive or inclusive. | | `start.key` | `string` | \- | * * * ### ScanOptionIndexedStartKey Ƭ **ScanOptionIndexedStartKey**: readonly \[secondary: string, primary?: string | undefined\] | `string` The key to start scanning at. If you are scanning the primary index (i.e., you did not specify `indexName`), then pass a single string for this field, which is the key in the primary index to scan at. If you are scanning a secondary index (i.e., you specified `indexName`), then use the tuple form. In that case, `secondary` is the secondary key to start scanning at, and `primary` (if any) is the primary key to start scanning at. * * * ### ScanOptions Ƭ **ScanOptions**: `ScanIndexOptions` | `ScanNoIndexOptions` Options for scan * * * ### TransactionEnvironment Ƭ **TransactionEnvironment**: `"client"` | `"server"` * * * ### TransactionLocation Ƭ **TransactionLocation**: `TransactionEnvironment` * * * ### TransactionReason Ƭ **TransactionReason**: `"initial"` | `"rebase"` | `"authoritative"` * * * ### UpdateNeededReason Ƭ **UpdateNeededReason**: { `type`: `"NewClientGroup"` } | { `type`: `"VersionNotSupported"` ; `versionType?`: `"push"` | `"pull"` | `"schema"` } * * * ### VersionNotSupportedResponse Ƭ **VersionNotSupportedResponse**: `Object` The server endpoint may respond with a `VersionNotSupported` error if it does not know how to handle the pullVersion, pushVersion or the schemaVersion. #### Type declaration | Name | Type | | --- | --- | | `error` | `"VersionNotSupported"` | | `versionType?` | `"pull"` | `"push"` | `"schema"` | ## Variables ### TEST\_LICENSE\_KEY • `Const` **TEST\_LICENSE\_KEY**: `"This key only good for automated testing"` * * * ### consoleLogSink • `Const` **consoleLogSink**: `LogSink` An implementation of \[\[LogSink\]\] that logs using `console.log` etc * * * ### version • `Const` **version**: `string` = `REPLICACHE_VERSION` The current version of Replicache. ## Functions ### deleteAllReplicacheData ▸ **deleteAllReplicacheData**(`opts?`): `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> Deletes all IndexedDB data associated with Replicache. Returns an object with the names of the successfully dropped databases and any errors encountered while dropping. #### Parameters | Name | Type | | --- | --- | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> **`Deprecated`** Use `dropAllDatabases` instead. * * * ### dropAllDatabases ▸ **dropAllDatabases**(`opts?`): `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> Deletes all IndexedDB data associated with Replicache. Returns an object with the names of the successfully dropped databases and any errors encountered while dropping. #### Parameters | Name | Type | | --- | --- | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> * * * ### dropDatabase ▸ **dropDatabase**(`dbName`, `opts?`): `Promise`<`void`\> Deletes a single Replicache database. #### Parameters | Name | Type | | --- | --- | | `dbName` | `string` | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<`void`\> * * * ### filterAsyncIterable ▸ **filterAsyncIterable**<`V`\>(`iter`, `predicate`): `AsyncIterable`<`V`\> Filters an async iterable. This utility function is provided because it is useful when using makeScanResult. It can be used to filter out tombstones (delete entries) for example. #### Type parameters | Name | | --- | | `V` | #### Parameters | Name | Type | | --- | --- | | `iter` | `IterableUnion`<`V`\> | | `predicate` | (`v`: `V`) => `boolean` | #### Returns `AsyncIterable`<`V`\> * * * ### getDefaultPuller ▸ **getDefaultPuller**(`rep`): `Puller` This creates a default puller which uses HTTP POST to send the pull request. #### Parameters | Name | Type | | --- | --- | | `rep` | `Object` | | `rep.auth` | `string` | | `rep.pullURL` | `string` | #### Returns `Puller` * * * ### isScanIndexOptions ▸ **isScanIndexOptions**(`options`): options is ScanIndexOptions Type narrowing of ScanOptions. #### Parameters | Name | Type | | --- | --- | | `options` | `ScanOptions` | #### Returns options is ScanIndexOptions * * * ### makeIDBName ▸ **makeIDBName**(`name`, `schemaVersion?`): `string` Returns the name of the IDB database that will be used for a particular Replicache instance. #### Parameters | Name | Type | Description | | --- | --- | --- | | `name` | `string` | The name of the Replicache instance (i.e., the `name` field of `ReplicacheOptions`). | | `schemaVersion?` | `string` | The schema version of the database (i.e., the `schemaVersion` field of `ReplicacheOptions`). | #### Returns `string` * * * ### makeScanResult ▸ **makeScanResult**<`Options`\>(`options`, `getScanIterator`): `ScanResult`<`KeyTypeForScanOptions`<`Options`\>, `ReadonlyJSONValue`\> A helper function that makes it easier to implement scan with a custom backend. If you are implementing a custom backend and have an in memory pending async iterable we provide two helper functions to make it easier to merge these together. mergeAsyncIterables and filterAsyncIterable. For example: const scanResult = makeScanResult( options, options.indexName ? () => { throw Error('not implemented'); } : fromKey => { const persisted: AsyncIterable<Entry<ReadonlyJSONValue>> = ...; const pending: AsyncIterable<Entry<ReadonlyJSONValue | undefined>> = ...; const iter = await mergeAsyncIterables(persisted, pending); const filteredIter = await filterAsyncIterable( iter, entry => entry[1] !== undefined, ); return filteredIter; },); #### Type parameters | Name | Type | | --- | --- | | `Options` | extends `ScanOptions` | #### Parameters | Name | Type | | --- | --- | | `options` | `Options` | | `getScanIterator` | `Options` extends `ScanIndexOptions` ? `GetIndexScanIterator` : `GetScanIterator` | #### Returns `ScanResult`<`KeyTypeForScanOptions`<`Options`\>, `ReadonlyJSONValue`\> * * * ### mergeAsyncIterables ▸ **mergeAsyncIterables**<`A`, `B`\>(`iterableBase`, `iterableOverlay`, `compare`): `AsyncIterable`<`A` | `B`\> Merges an iterable on to another iterable. The two iterables need to be ordered and the `compare` function is used to compare two different elements. If two elements are equal (`compare` returns `0`) then the element from the second iterable is picked. This utility function is provided because it is useful when using makeScanResult. It can be used to merge an in memory pending async iterable on to a persistent async iterable for example. #### Type parameters | Name | | --- | | `A` | | `B` | #### Parameters | Name | Type | | --- | --- | | `iterableBase` | `IterableUnion`<`A`\> | | `iterableOverlay` | `IterableUnion`<`B`\> | | `compare` | (`a`: `A`, `b`: `B`) => `number` | #### Returns `AsyncIterable`<`A` | `B`\> --- ## Page: https://doc.replicache.dev/howto/blobs Binary data is often referred to as "blobs". This recipe shows a few ways to use binary data in Replicache. The data model in Replicache is JSON. JSON does not have a way to represent binary data efficiently. Depending on your use case there are a few ways to handle binary data. ## Base64 The simplest way to handle binary data is to base64 encode it. The size overhead for base64 is roughly 4/3 (or 133%) of the size of the original data. You can reduce this by using a compression algorithm but that adds more complexity to the code. For example if you have a profile picture in your user data you can do something like: // npm install base64-arraybufferimport * as base64 from 'base64-arraybuffer';type User = { id: string; name: string; picture: Uint8Array;};type RepUser = { id: string; name: string; // Note how Replicache needs to use a string here! picture: string;};const rep = new Replicache({ name: 'user-id', licenseKey: '...', mutators: { async setUserData(tx: WriteTransaction, user: RepUser) { await tx.set(`user/${user.id}`, user); }, },});async function setUserData(rep: Replicache, user: User) { const {id, name, picture} = user; const repUser = { id, name, picture: base64.encode(picture.buffer), }; await rep.mutate.setUserData(repUser);}async function getUserData(rep: Replicache, id: string): Promise<User> { const repUser = await rep.query(tx => tx.get(`user/${id}`)); const {id, name, picture} = repUser; return { id, name, picture: new Uint8Array(base64.decode(picture)), };} ### Best practices when using base64 If your binary data is not small and does not change frequently it is probably better to keep it in its own key. This way we do not have to redownload the data when some unrelated data changes. If we continue with the above example, we can store the picture in its own key by doing something like. const rep = new Replicache({ name: 'user-id', mutators: { async setUserData(tx: WriteTransaction, user: RepUser) { const {id, name, picture} = user; await tx.set(`user/${id}`, {id, name}); await tx.set(`user/${id}/picture`, picture); }, },});async function getUserData(rep: Replicache, id: string): Promise<User> { const {name, picture} = await rep.query(async tx => { const {name} = await tx.get(`user/${id}`); const picture = await tx.get(`user/${id}/picture`); return {name, picture}; }); return { id, name, picture: new Uint8Array(base64.decode(picture)), };} Now, if the name changes we do not need to resync the picture data. ## Content Addressed Data If the data is immutable and large and is often shared between different parts of the system it might make sense to use content addressed data. When using content adressed data we compute a hash of the content and use that as the key. Modern browsers have excellent support for hashing so it is easy to have the client compute the hash. If we continue with the above example, we can use the hash of the picture as its ID. type RepUser = { id: string; name: string; picture: string; pictureHash: string;};async function computeHash(data: Uint8Array): Promise<string> { const buf = await crypto.subtle.digest('SHA-256', data); return Array.from(new Uint8Array(buf), b => b.toString(16).padStart(2, '0'), ).join('');}const rep = new Replicache({ name: 'user-id', licenseKey: '...', mutators: { async setUserData(tx: WriteTransaction, user: RepUser) { const {id, name, picture, pictureHash} = user; await tx.set(`user/${id}`, {id, name, pictureHash}); await tx.set(`blob/${pictureHash}`, picture); }, },});async function setUserData(rep: Replicache, user: User) { const {id, name, picture} = user; const pictureHash = await computeHash(picture); const repUser = { id, name, picture: base64.encode(picture.buffer), pictureHash, }; await rep.mutate.setUserData(repUser);}async function getUserData(rep: Replicache, id: string): Promise<User> { const {name, picture} = await rep.query(async tx => { const {name, pictureHash} = await tx.get(`user/${id}`); const picture = await tx.get(`blob/${pictureHash}`); return {name, picture}; }); return { id, name, picture: new Uint8Array(base64.decode(picture)), };} ## Storing binary data outside of Replicache It is also possible to store binary data outside of Replicache. This gets significantly more complicated and it is important to point out that since the data is no longer managed by Replicache there is no guarantee that the blobs stays consistend with the state of Replicache. User code needs to handle the case where a referenced blob isn't downloaded yet as well as manage the syncing of the blobs. The main reason to store binary data outside the client view (outside Replicache) is to exceed the size limits of the client view of Replicache itself as well as the size limit imposed by "serverless" servers. For example AWS Lambda limits the size of response/requst to 6MB. When using things like Amazon S3 for the actual storage you can upload and download directly to the S3 bucket which allows you to sidestep the request size limit of you server functions. Another benifit of this approach is that we do not need to read large blobs into memory and we can let the browser keep things on disk as needed. This might be important if your app is working with large media files for example. To make things a little bit simpler we are going to treat blobs as immutable and use content adressed data. We are going to walk through an example where we store the blobs locally in a CacheStorage. We will continue with the profile picture as an example. ### Setting up the server Since we need to sync the data between clients and the data is no longer managed by Replicache we need the server to cooperate. The server will need an endpoint to upload the data to and another endpoint to download the data from. #### Upload endpoint The upload endpoint will be a `PUT` handler at `/blob/<hash>`. The hash is the content address of the blob. #### Download endpoint This endpoint will be a `GET` handler at `/blob/<hash>`. The hash is the content address of the blob. ### Keep the blob hashes in the Client View To sync the blobs to the client we keep the hashes of the blobs in the client view. We subscribe to changes of a keyspace of the client view and whenever this changes we download the files as needed. const blobPrefx = 'blob/';rep.subscribe( (tx: ReadTransaction) => tx.scan({prefix: blobPrefix}).keys().toArray(), { async onData(keys: string[]) { for (const key of keys) { const hash = key.slice(blobPrefix.length); await downloadBlob(hash); } }, },);// This should be the same as the name used with Replicache.const cacheName = 'profile-pictures';const blobURL = hash => `/blob/${hash}`;const blobKey = hash => `blob/${hash}`;async function downloadBlob(hash: string) { // Check if we already have the blob. const cache = await caches.open(cacheName); const url = blobURL(hash); const resp = await cache.match(url); if (!resp) { // not in cache const r = await fetch(url); if (r.ok) { await cache.put(url, r); } else { // Try again next time. // TODO: handle error better } }} #### Uploading the blob We could just upload the blob and sync the data using a `pull`, which would in turn download the file. This is the simplest way to do it but the downside is that we have to redownload the file directly after we upload it. This is going to be slow, especially for large media files. One way to prevent this is to add the file to the cache and keep the uploaded state in the client view as well. async function uploadBlob(rep: Replicache, data: Uint8Array, hash: string) { // Since we already have the blob here, we might as well add it to // the cache instead of redownloading it. await addBlobToCache(hash, data); const resp = await fetch(blobURL(hash), { method: 'PUT', body: data, }); await rep.mutate.addBlob({hash, shouldUpload: !resp.ok});}async function addBlobToCache(hash: string, data: Uint8Array) { const cache = await caches.open(cacheName); const blob = new Blob([data]); await cache.put(blobURL(hash), new Response(blob));}const rep = new Replicache({ name: 'user-id', mutators: { async addBlob(tx, {hash, shouldUpload}) { await tx.set(blobKey(hash), {shouldUpload}); }, },}); The server side implementation of the `addBlob` mutator does not have to do much. It can just store the key and value as pushed. It is important that the client view includes the key-value pair for this blob or the client will lose track of the state of the blob. A better implementation would be to set `shouldUpload` depending on wether the blob has been uploaded or not. #### Syncing the blobs We didn't do a very good job dealing with errors above. Let's change the subscription to deal with both upload and download now that we are keeping track of the uploaded state. rep.subscribe(tx => tx.scan({prefix: blobPrefix}).entries().toArray(), { async onData(blobs: [string, {shouldUpload: boolean}][]) { const cache = await caches.open(cacheName); for (const [key, value] of blobs) { const hash = key.slice(blobPrefix.length); const {shouldUpload} = value; await syncBlob(rep, cache, hash, shouldUpload); } },});async function syncBlob(rep, cache, hash, shouldUpload) { const response = await cache.match(blobURL(hash)); if (response) { if (shouldUpload) { const buffer = await response.arrayBuffer(); await uploadBlob(rep, new Uint8Array(buffer), hash); } } else { const resp = await downloadBlob(hash); if (resp.ok) { await cache.put(blobURL(hash), resp); if (shouldUpload) { // Mark as uploaded, so we don't try to upload it again. await rep.mutate.addBlob({hash, shouldUpload: false}); } } }} Change download blob to do nothing but download... function downloadBlob(hash) { return fetch(blobURL(hash));} The above code should now work for both upload and download. When we add a blob we register the hash in Replicache and we store the blob in a CacheStorage cache. We subscribe to changes in Replicache keys starting with `'blob/'` and resync the file as needed when this changes. #### Failure to upload or download In any network app the network can go down. In case we failed to upload or download the files we need to handle the cases where upload or download failed and keep trying. We can run the sync code on an interval to keep trying. We can extract some of the above code and put it in an `setInterval`. const blobsTx = (tx: ReadTransaction) => tx.scan({prefix: blobPrefix}).entries().toArray();async function syncAllBlobs(blobs: [string, {shouldUpload: boolean}][]) { const cache = await caches.open(cacheName); for (const [key, value] of blobs) { const hash = key.slice(blobPrefix.length); const {shouldUpload} = value; await syncBlob(rep, cache, hash, shouldUpload); }}rep.subscribe(blobsTx, { onData: syncAllBlobs,});setInterval( async () => { const blobs = await rep.query(blobsTx); await syncAllBlobs(blobs); }, 5 * 60 * 1000,); This will run the sync code every 5 minutes. This is of course a bit too simplistic. We should ensure that there are no overlapping syncs and we can keep track of network failure to detect if we need to retry or not. #### Pull Response The above works well for blobs added by the current client. However, if we want to get blobs from other clients we need to ensure that the pull response includes the hashes of the blobs from them too. In this simple case we can check if a key starting with `user/` is included in the pull response and if so also add an op to set the blob key in that case as well. In a more mature system you probably want to design a more solid solution. --- ## Page: https://doc.replicache.dev/concepts/licensing The Replicache Terms of Service require that anyone using Replicache acquire and use their own license key. A license key is required for _any_ use of Replicache, commercial or non-commercial, including tire-kicking, evaluation, and just playing around. But don't worry: getting a key is fast, low commitment (no credit card), and there is no charge for many uses of Replicache (see Replicache Pricing). To get a key run: npx replicache@latest get-license It will ask you a few questions and then print your license key, eg: l123d3baa14984beca21bc42aee593064 Pass this key as a string to the Replicache constructor, e.g.: new Replicache({ licenseKey: "l123d3baa14984beca21bc42aee593064", ...}); ## Monthly Active Profiles We charge for Replicache by Monthly Active Profiles ("MAPs"). A MAP is a unique browser profile that used your application during a month. For example, if within one month, one of your users used your Replicache-enabled app on Firefox and Chrome on their Desktop computer and Safari on their phone, that would be 3 MAPs. The reason for counting this way is because as a client-side JavaScript library, Replicache is sandboxed within a browser profile. It can't tell the difference between two profiles on the same machine or two profiles on different machines. MAPs are typically a small fraction (like 50%) higher than MAUs because some users, but not all, use applications on multiple profiles/devices. ## Pricing Exemption We offer Replicache free of charge to non-commercial or pre-revenue/funding companies. See the Terms of Service for our definition of "commercial" and the Pricing page for details on the revenue/funding hurdle. After your two-month trial of Replicache, you will receive an invoice. If you believe you qualify for one of our exemptions, you can reply to the invoice with the details. ## License Pings We track usage by sending a ping to our servers containing your license key and a unique browser profile identifier when Replicache is instantiated, and every 24 hours that it is running. We check at instantiation time that your license key is valid. If your license key is invalid, Replicache disables itself. The license key check is asynchronous and doesn't block any other code from running. The check is also setup so that it "fails open". The only way Replicache disables itself is if it receives a specific message from our server. Network errors, HTTP errors, or server errors won't cause Replicache to disable. Disabling Replicache's pings other than via the `TEST_LICENSE_KEY` (see below) is against our Terms of Service. If the pings are a problem for your environment, please get in touch with us at hello@replicache.dev. ## Unit testing Replicache's license pings are almost certainly undesirable in automated tests for a variety of reasons (hermeticity, inflated Replicache usage charges, etc.). For automated tests, pass `TEST_LICENSE_KEY` instead of your key. For example: import {Replicache, TEST_LICENSE_KEY} from 'replicache';...test('my test', () => { const r = new Replicache({ licenseKey: TEST_LICENSE_KEY, ... }); ...}); Using the `TEST_LICENSE_KEY` skips the server ping, but a Replicache instance instantiated with it will shut itself down after a few minutes. ## Pricing Examples * Example 1: You are a non-profit organization with 4M MAPs. **Your price is zero**. * Example 2: You are using Replicache for a personal blog with 5k MAPs. **Your price is zero**. * Example 3: You are a startup using Replicache for a revolutionary productivity application. You have raised a seed of $150k and have $100k annual revenue. **Your price is zero**. * Example 4: You are using Replicache for a new version of your company's SaaS offering, but it's in internal testing and has only 50 MAPs (your dev team). You have been using Replicache for more than 2 months. Your company has raised $600k in total funding, but you are pre-revenue. **Your price is $500/mo**. * Example 5: You are using Replicache for a new product that is a free add-on to your company's SaaS offering. You have been using Replicache for more than 2 months and are generating 15k MAPs. Your company is bootstrapped and making $300k/yr. **Your price is $3000/mo**. --- ## Page: https://doc.replicache.dev/concepts/performance ## Performance Intuitions Your intuition should be that Replicache has "memory-fast" performance for common operations. Here are some rough rules of thumb that should serve you well. | Operation | Expectation | | --- | --- | | Read 1 value | < 1ms | | Read (scan) keys in order | \> 500 MB/s | | Write 1 value and commit tx | < 1ms | | Write 1KB values in bulk and commit tx | \> 90 MB/s | | Start from disk | First 100KB in < 150ms | ## Typical Workload Here are some axes along which you could measure the workload that Replicache is designed to work with. These are not hard constraints, they give ranges in which we would expect Replicache to work without caveats. If you want to operate outside of these ranges, it's probably a good idea to talk to us. | Axis | Expectation | | --- | --- | | Total data size | < 64MB per cache | | Typical key-value size | 100 bytes - 10KB | | Max key-value size | < 1MB (see also blobs) | | Average push-pull round trip latency | 100's of ms | | Number of indexes | < 5 | ## Specific Performance Metrics Below find some specific performance metrics that Replicache meets or exceeds. We track these metrics (and more) as part of our continuous integration strategy, measuring them on stock desktop hardware (4-core Xeon from 2018-ish, 16GB RAM) for every change to the codebase. Note that these are microbenchmarks with very specific payloads. Actual performance will vary. If you experience worse performance than suggested below we'd likely consider it a bug, so please contact us. ### Scan: 650MB/s * * * This is the rate at which key-values can be iterated in key order. ### Reactive Loop w/16MB cache: 3ms @p50, 7ms @p95 ### Reactive Loop w/64MB cache: 3.5ms @p50, 7ms @p95 * * * The reactive loop latency is the time it takes to write new data, notify all subscribers of the change, and for them to read the new data out. Assumptions: there are 100 open subscriptions 5 of which are dirty, and each of these 5 reads 10KB of data. ### Populate 1MB w/0 indexes: 90MB/s ### Populate 1MB w/1 indexes: 45MB/s ### Populate 1MB w/2 indexes: 30MB/s * * * This measures the rate at which callers can write 1MB's worth of 1KB key-values. ### Startup: 100KB in < 150ms @p95 * * * This measures the p95 time to read the first 100KB of data from disk at Replicache startup. --- ## Page: https://doc.replicache.dev/byob/poke By default, Replicache pulls new changes periodically. The frequency is controlled by the `pullInterval` parameter which defaults to 60 seconds. To get more responsive updates, you could reduce the pull interval, but that gets expensive quick. Most Replicache applications instead have the server send a special message called a _poke_ to the app, telling it when it should pull again. A Replicache poke caries no data – it's only a hint telling the client to pull soon. This enables developers to build their realtime apps in the standard stateless request/response style. You can even build Replicache-enabled apps serverlessly (as we are here with Next.js)! Because pokes are simple, you can implement them many ways. Any hosted WebSocket service like Pusher or PubNub works. You can also implement your own WebSocket server or use server-sent events. And some databases come with features that can be used for pokes. For several different examples to implementing pokes, see Todo, Three Ways. For this sample, we'll use Pusher. Go to pusher.com and setup a free "Channels" project with client type "React" and server type "Node.js". Store the settings from the project in the following environment variables: export REPLICHAT_PUSHER_APP_ID=<app id>export REPLICHAT_PUSHER_KEY=<key>export REPLICHAT_PUSHER_SECRET=<secret>export REPLICHAT_PUSHER_CLUSTER=<cluster>export VITE_PUBLIC_REPLICHAT_PUSHER_KEY=<key>export VITE_PUBLIC_REPLICHAT_PUSHER_CLUSTER=<cluster> Typically you'll establish one WebSocket _channel_ per-document or whatever the unit of collaboration is in your application. For this simple demo, we just create one channel, `"default"`. Replace the implementation of `sendPoke()` in `push.ts`: import Pusher from 'pusher';//...async function sendPoke() { if ( !process.env.REPLICHAT_PUSHER_APP_ID || !process.env.REPLICHAT_PUSHER_KEY || !process.env.REPLICHAT_PUSHER_SECRET || !process.env.REPLICHAT_PUSHER_CLUSTER ) { throw new Error('Missing Pusher environment variables'); } const pusher = new Pusher({ appId: process.env.REPLICHAT_PUSHER_APP_ID, key: process.env.REPLICHAT_PUSHER_KEY, secret: process.env.REPLICHAT_PUSHER_SECRET, cluster: process.env.REPLICHAT_PUSHER_CLUSTER, useTLS: true, }); const t0 = Date.now(); await pusher.trigger('default', 'poke', {}); console.log('Sent poke in', Date.now() - t0);} Then on the client, in `client/src/index.tsx`, replace the implementation of `listen()` to tell Replicache to `pull()` whenever a poke is received: function listen(rep: Replicache) { console.log('listening'); // Listen for pokes, and pull whenever we get one. Pusher.logToConsole = true; if ( !import.meta.env.VITE_PUBLIC_REPLICHAT_PUSHER_KEY || !import.meta.env.VITE_PUBLIC_REPLICHAT_PUSHER_CLUSTER ) { throw new Error('Missing PUSHER_KEY or PUSHER_CLUSTER in env'); } const pusher = new Pusher(import.meta.env.VITE_PUBLIC_REPLICHAT_PUSHER_KEY, { cluster: import.meta.env.VITE_PUBLIC_REPLICHAT_PUSHER_CLUSTER, }); const channel = pusher.subscribe('default'); channel.bind('poke', async () => { console.log('got poked'); await rep.pull(); });} Finally, ensure Pusher and Replicache disconnect at the same time in `client/src/index.tsx`, replace Replicache useEffect return with return () => { Pusher.instances.forEach(i => i.disconnect()); void r.close();}; Restart the app, and make a change, and you should see it propagate live between browsers:  ## Next And that's it! The next section wraps up. --- ## Page: https://doc.replicache.dev/examples/repliear A tiny Linear\-like issue tracker. Built with Replicache, Next.js, and Supabase. Running live at https://repliear.herokuapp.com. To see realtime changes in action, click the link, copy the resulting URL, open a second browser window to it, and watch changes you make in one window sync to the other. Source code at https://github.com/rocicorp/repliear.  --- ## Page: https://doc.replicache.dev/byob/setup Replicache is framework agnostic, and you can use most any libraries and frameworks you like. In this guide, we're going to use Express/Vite/React. To start, clone the BYOB starter repo: git clone git@github.com:rocicorp/byob-starter.gitcd byob-starternpm install This project is a monorepo web app with three workspaces: `client`, `server`, and `shared`. The `client` workspace contains the client-side UI, developed with Vite and React. The `server` workspace contains the server-side logic, implemented using Express. And the `shared` workspace contains types and classes that are shared between client and server. --- ## Page: https://doc.replicache.dev/byob/client-view An easy way to start a Replicache project is to design your Client View schema and start serving it. That's because the Client View is the interface between the client and server — the data that the UI renders, and that the server must provide. The Client View is a map from string keys to JSON-compatible values. Since we're trying to build a chat app, a simple list of messages is a decent starting point for our schema: { "messages/l2WXAsRlA2Rg47sfGMdAK": { "from": "Jane", "order": 1, "content": "Hey, what's up for lunch?" }, "messages/g0Y8yLKobt0BpXwUrVJCK": { "from": "Fred", "order": 2, "content": "Taaaacos" }} (A real app would likely separate out the user entities, but this is good enough for our purposes.) A quick word on IDs Unlike with classic client/server apps, Replicache apps can't rely on the server to assign unique IDs. That's because the client is going to be working with data long before it reaches the server, and the client and server need a consistent way to refer to items. Therefore, Replicache requires that clients assign IDs. Our sample apps typically use nanoid for this purpose, but any random ID will work. ## Serving the Client View Now that we know what our schema will look like, let's serve it. Initially, we'll just serve static data, but later we'll build it dynamically from data in the database. Create a file in the project at `server/src/pull.ts` with the following contents: import type {Request, Response, NextFunction} from 'express';export async function handlePull( _req: Request, res: Response, next: NextFunction,): Promise<void> { try { res.json({ // We will discuss these two fields in later steps. lastMutationIDChanges: {}, cookie: 42, patch: [ {op: 'clear'}, { op: 'put', key: 'message/qpdgkvpb9ao', value: { from: 'Jane', content: "Hey, what's for lunch?", order: 1, }, }, { op: 'put', key: 'message/5ahljadc408', value: { from: 'Fred', content: 'tacos?', order: 2, }, }, ], }); } catch (e) { next(e); }} Add the handler to Express modifying the file `server/src/main.ts` with the `app.post` route: import { handlePull } from './pull';//...app.use(express.urlencoded({extended: true}), express.json(), errorHandler);app.post('/api/replicache/pull', handlePull);if (process.env.NODE_ENV === 'production') {//... You'll notice the JSON we're serving is a little different than our idealized schema above. The response from `replicache/pull` is actually a _patch_ — a series of changes to be applied to the map the client currently has, as a result of changes that have happened on the server. Replicache applies the patch operations one-by-one, in-order, to its existing map. See Pull Endpoint for more details. Early in development, it's easiest to just return a patch that replaces the entire state with new values, which is what we've done here. Later in this tutorial we will improve this to return only what has changed. info Replicache forks and versions the cache internally, much like Git. You don't have to worry about changes made by the app to the client's map between pulls being clobbered by remote changes via patch. Replicache has a mechanism ensuring that local pending (unpushed) changes are always applied on top of server-provided changes (see Local Mutations). Also, Replicache is a _transactional_ key/value store. So although the changes are applied one-by-one, they are revealed to your app (and thus to the user) all at once because they're applied within a single transaction. Start your client and server with `cd client && npm run watch`, and curl the pull endpoint to ensure it's working: curl -X POST http://localhost:8080/api/replicache/pull ## Next Next, we'll render our UI from this static Client View. --- ## Page: https://doc.replicache.dev/byob/render-ui The next step is to use the data in the Client View to render your UI. First, let's define a few simple types. Replicache supports strongly-typed mutators – we'll use these types later to ensure our UI passes the correct data. Modify the `types.ts` at `shared/src/types.ts` Now we'll build the UI. The model is that the view is a pure function of the data in Replicache. Whenever the data in Replicache changes — either due to local mutations or syncing with the server — subscriptions will fire, and your UI components re-render. Easy. To create a subscription, use the `useSubscribe()` React hook. You can do multiple reads and compute a result. Your React component only re-renders when the returned result changes. Let's use a subscription to implement our chat UI. Replace `index.tsx` with the below code: /* eslint-disable @typescript-eslint/no-unused-vars */import React, {useEffect, useRef, useState} from 'react';import ReactDOM from 'react-dom/client';import {Replicache, TEST_LICENSE_KEY, WriteTransaction} from 'replicache';import {Message, MessageWithID} from 'shared';import {useSubscribe} from 'replicache-react';import Pusher from 'pusher-js';import {nanoid} from 'nanoid';async function init() { const licenseKey = import.meta.env.VITE_REPLICACHE_LICENSE_KEY || TEST_LICENSE_KEY; if (!licenseKey) { throw new Error('Missing VITE_REPLICACHE_LICENSE_KEY'); } function Root() { const [r, setR] = useState<Replicache<any> | null>(null); useEffect(() => { console.log('updating replicache'); const r = new Replicache({ name: 'chat-user-id', licenseKey, pushURL: `/api/replicache/push`, pullURL: `/api/replicache/pull`, logLevel: 'debug', }); setR(r); listen(r); return () => { void r.close(); }; }, []); const messages = useSubscribe( r, async tx => { const list = await tx .scan<Message>({prefix: 'message/'}) .entries() .toArray(); list.sort(([, {order: a}], [, {order: b}]) => a - b); return list; }, {default: []}, ); const usernameRef = useRef<HTMLInputElement>(null); const contentRef = useRef<HTMLInputElement>(null); const onSubmit = async (e: React.FormEvent<HTMLFormElement>) => { e.preventDefault(); // TODO: Create Message }; return ( <div> <form onSubmit={onSubmit}> <input ref={usernameRef} required /> says: <input ref={contentRef} required /> <input type="submit" /> </form> {messages.map(([k, v]) => ( <div key={k}> <b>{v.from}: </b> {v.content} </div> ))} </div> ); } ReactDOM.createRoot(document.getElementById('root') as HTMLElement).render( <React.StrictMode> <Root /> </React.StrictMode>, );}function listen(rep: Replicache) { // TODO: Listen for changes on server}await init(); Navigate to http://localhost:5173/. You should see that we're rendering data from Replicache! This might not seem that exciting yet, but notice that if you change `replicache/pull` temporarily to return 500 (or remove it, or cause any other error, or just make it really slow), the page still renders instantly. That's because we're rendering the data from the local cache on startup, not waiting for the server! Woo. Enough with static data. The next section adds local mutations, which is how we implement optimistic UI in Replicache. --- ## Page: https://doc.replicache.dev/byob/local-mutations With Replicache, you implement mutations once on the client-side (sometimes called _speculative_ or _optimistic_ mutations), and then again on the server (called _authoritative_ mutations). info The two implementations need not match exactly. Replicache replaces the result of a speculative change completely with the result of the corresponding authoritative change, once it's known. This is useful because it means the speculative implementation can frequently be pretty simple, not taking into account security, complex business logic edge cases, etc. First, let's register a _mutator_ that speculatively creates a message. In `index.tsx`, expand the options passed to the `Replicache` constructor with: //...const r = new Replicache({ name: 'chat-user-id', licenseKey, mutators: { async createMessage( tx: WriteTransaction, {id, from, content, order}: MessageWithID, ) { await tx.set(`message/${id}`, { from, content, order, }); }, }, pushURL: `/api/replicache/push`, pullURL: `/api/replicache/pull`, logLevel: 'debug',});//... When invoked, the implementation is run within a transaction (`tx`) and it `put`s the new message into the local map. Now let's invoke the mutator when the user types a message. Replace the content of `onSubmit` so that it invokes the mutator: const onSubmit = async (e: React.FormEvent<HTMLFormElement>) => { e.preventDefault(); let last: Message | null = null; if (messages.length) { const lastMessageTuple = messages[messages.length - 1]; last = lastMessageTuple[1]; } const order = (last?.order ?? 0) + 1; const username = usernameRef.current?.value ?? ''; const content = contentRef.current?.value ?? ''; await r?.mutate.createMessage({ id: nanoid(), from: username, content, order, }); if (contentRef.current) { contentRef.current.value = ''; } }; Previously we mentioned that Replicache has a mechanism that ensures that local, speculative changes are always applied on top of changes from the server. The way this works is that when Replicache pulls and applies changes from the server, any mutator invocations that have not yet been confirmed by the server are _replayed_ on top of the new server state. This is much like a git rebase, and the effects of the patch-and-replay are revealed atomically to your app. An important consequence of this is that unique IDs should often be passed into mutators as parameters, and not generated inside the mutator. This may be counter-intuitive at first, but it makes sense when you remember that Replicache is going to replay this transaction during sync, and we don't want the ID to change! info Careful readers may be wondering what happens with the order field during sync. Can multiple messages end up with the same order? Yes! But in this case, what the user likely wants is for their message to stay roughly at the same position in the stream, and using the client-specified order and sorting by that roughly achieves the desired result. If we wanted better control over this, we could use fractional indexing but that's not necessary in this case. Restart the server and you should now be able to make changes. Note that changes are already propagating between tabs, even though we haven't done anything on the server yet. And this works even if you kill the server. This is because Replicache stores data locally that is shared between all tabs in a browser profile. 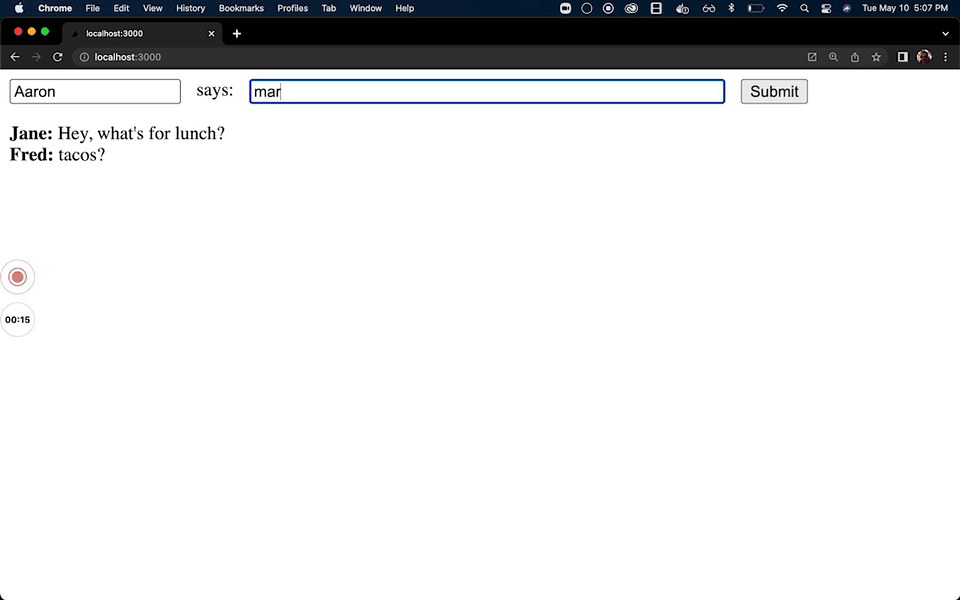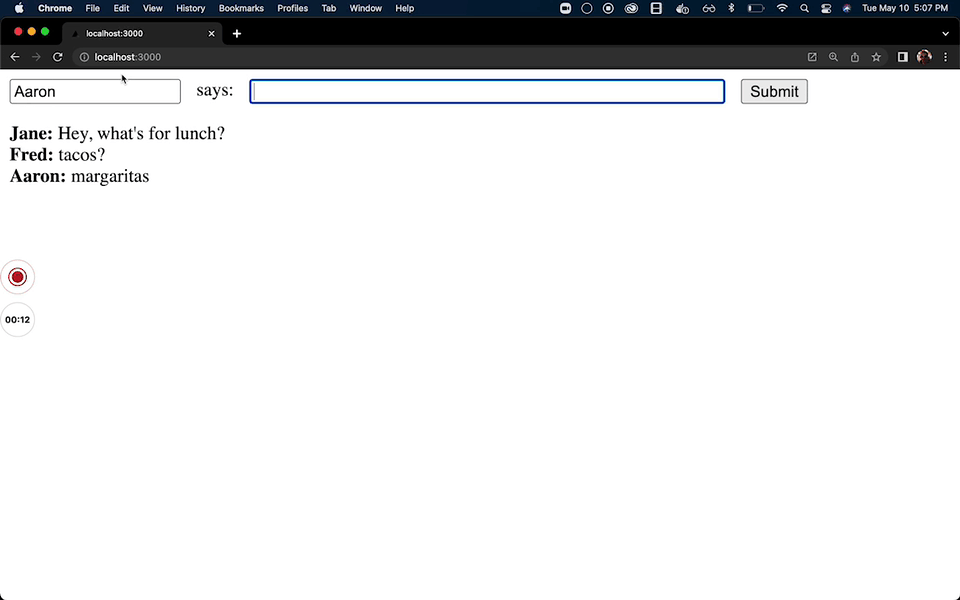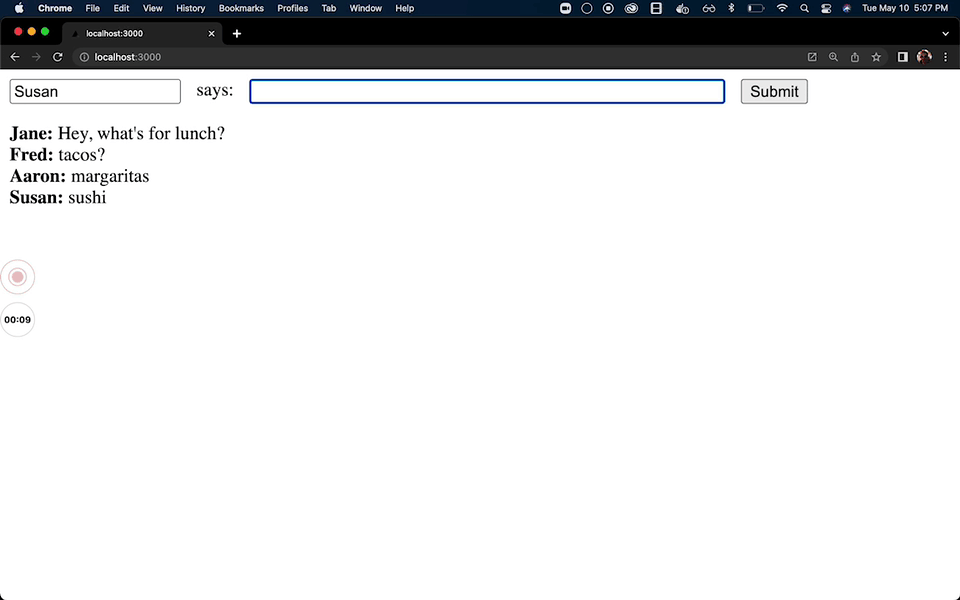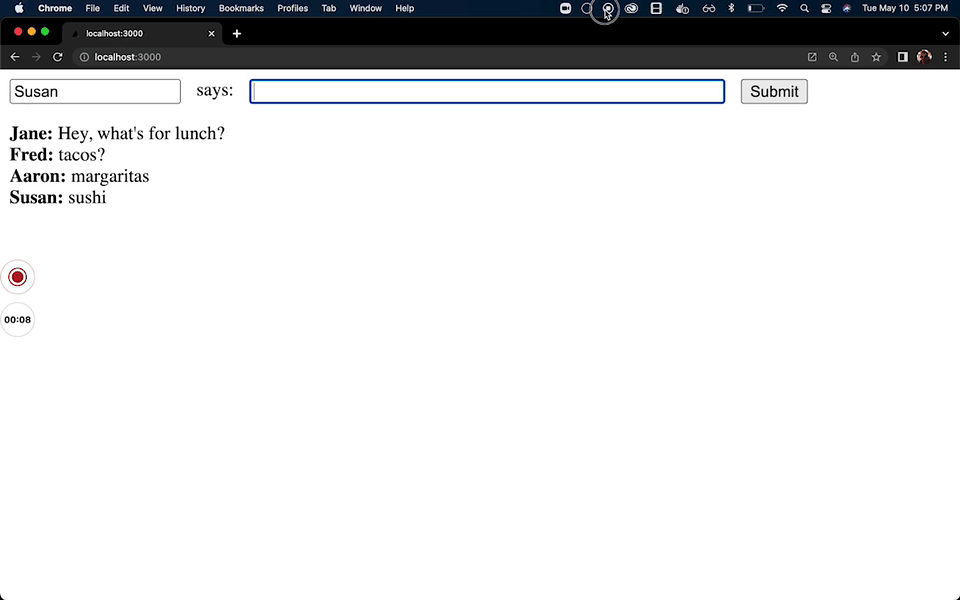 ## Next That's actually it for the client! Next, we'll start work on our server by setting up a remote database. --- ## Page: https://doc.replicache.dev/byob/remote-database Replicache is also backend-agnostic. You can use most backend languages and frameworks, and any backend datastore that supports at least Snapshot Isolation. Some examples of suitable datastores are: MySQL, Postgres, CockroachDB, CosmosDB, and Firebase Cloud Firestore. Some examples of non-suitable datastores are: DynamoDB and Firebase RealtimeDB. For this demo, we'll use pg-mem — an in-memory implementation of Postgres. This is a nice easy way to play locally, but you can easily adapt this sample to use a remote Postgres implementation like Render or Supabase. // eslint-disable-next-line @typescript-eslint/ban-ts-comment// @ts-nocheckimport {newDb} from 'pg-mem';import pgp, {IDatabase, ITask} from 'pg-promise';const {isolationLevel} = pgp.txMode;export const serverID = 1;async function initDB() { console.log('initializing database...'); const db = newDb().adapters.createPgPromise(); return db;}function getDB() { // Cache the database in the Node global so that it survives HMR. if (!global.__db) { global.__db = initDB(); } // eslint-disable-next-line @typescript-eslint/ban-types return global.__db as IDatabase<{}>;}// eslint-disable-next-line @typescript-eslint/ban-typesexport type Transaction = ITask<{}>;type TransactionCallback<R> = (t: Transaction) => Promise<R>;// In Postgres, snapshot isolation is known as "repeatable read".export async function tx<R>(f: TransactionCallback<R>, dbp = getDB()) { const db = await dbp; return await db.tx( { mode: new pgp.txMode.TransactionMode({ tiLevel: isolationLevel.repeatableRead, }), }, f, );} --- ## Page: https://doc.replicache.dev/byob/remote-schema There are a number of ways to implement Replicache backends. The Replicache client doesn't actually care _how_ your backend works internally — it only cares that you provide correctly implemented push and pull endpoints. This walkthrough implements the Global Version backend strategy, which is a simple strategy that we usually recommend users start with. See Backend Strategies for information on other commonly used strategies. Let's define our Postgres schema. As suggested in the Global Version Strategy doc, we'll track: async function initDB() { console.log('initializing database...'); const db = newDb().adapters.createPgPromise(); await tx(async t => { // A single global version number for the entire database. await t.none( `create table replicache_server (id integer primary key not null, version integer)`, ); await t.none( `insert into replicache_server (id, version) values ($1, 1)`, serverID, ); // Stores chat messages. await t.none(`create table message ( id text primary key not null, sender varchar(255) not null, content text not null, ord integer not null, deleted boolean not null, version integer not null)`); // Stores last mutationID processed for each Replicache client. await t.none(`create table replicache_client ( id varchar(36) primary key not null, client_group_id varchar(36) not null, last_mutation_id integer not null, version integer not null)`); // TODO: indexes }, db); return db;} The next section implements remote mutations, so that our optimistic changes can become persitent. --- ## Page: https://doc.replicache.dev/byob/remote-mutations Replicache will periodically invoke your push endpoint sending a list of mutations that need to be applied. The implementation of push will depend on the backend strategy you are using. For the Global Version strategy we're using, the basics steps are: At minimum, all of these changes **must** happen atomically in a single transaction for each mutation in a push. However, putting multiple mutations together in a single wider transaction is also acceptable. Create a file in the project at `server/src/push.ts` and copy the below code into it. This looks like a lot of code, but it's just implementing the description above. See the inline comments for additional details. import {serverID, tx, type Transaction} from './db';import type {MessageWithID} from 'shared';import type {MutationV1, PushRequestV1} from 'replicache';import type {Request, Response, NextFunction} from 'express';export async function handlePush( req: Request, res: Response, next: NextFunction,): Promise<void> { try { await push(req, res); } catch (e) { next(e); }}async function push(req: Request, res: Response) { const push: PushRequestV1 = req.body; console.log('Processing push', JSON.stringify(push)); const t0 = Date.now(); try { // Iterate each mutation in the push. for (const mutation of push.mutations) { const t1 = Date.now(); try { await tx(t => processMutation(t, push.clientGroupID, mutation)); } catch (e) { console.error('Caught error from mutation', mutation, e); // Handle errors inside mutations by skipping and moving on. This is // convenient in development but you may want to reconsider as your app // gets close to production: // https://doc.replicache.dev/reference/server-push#error-handling await tx(t => processMutation(t, push.clientGroupID, mutation, e as string), ); } console.log('Processed mutation in', Date.now() - t1); } res.send('{}'); await sendPoke(); } catch (e) { console.error(e); res.status(500).send(e); } finally { console.log('Processed push in', Date.now() - t0); }}async function processMutation( t: Transaction, clientGroupID: string, mutation: MutationV1, error?: string | undefined,) { const {clientID} = mutation; // Get the previous version and calculate the next one. const {version: prevVersion} = await t.one( 'select version from replicache_server where id = $1 for update', serverID, ); const nextVersion = prevVersion + 1; const lastMutationID = await getLastMutationID(t, clientID); const nextMutationID = lastMutationID + 1; console.log('nextVersion', nextVersion, 'nextMutationID', nextMutationID); // It's common due to connectivity issues for clients to send a // mutation which has already been processed. Skip these. if (mutation.id < nextMutationID) { console.log( `Mutation ${mutation.id} has already been processed - skipping`, ); return; } // If the Replicache client is working correctly, this can never // happen. If it does there is nothing to do but return an error to // client and report a bug to Replicache. if (mutation.id > nextMutationID) { throw new Error( `Mutation ${mutation.id} is from the future - aborting. This can happen in development if the server restarts. In that case, clear appliation data in browser and refresh.`, ); } if (error === undefined) { console.log('Processing mutation:', JSON.stringify(mutation)); // For each possible mutation, run the server-side logic to apply the // mutation. switch (mutation.name) { case 'createMessage': await createMessage(t, mutation.args as MessageWithID, nextVersion); break; default: throw new Error(`Unknown mutation: ${mutation.name}`); } } else { // TODO: You can store state here in the database to return to clients to // provide additional info about errors. console.log( 'Handling error from mutation', JSON.stringify(mutation), error, ); } console.log('setting', clientID, 'last_mutation_id to', nextMutationID); // Update lastMutationID for requesting client. await setLastMutationID( t, clientID, clientGroupID, nextMutationID, nextVersion, ); // Update global version. await t.none('update replicache_server set version = $1 where id = $2', [ nextVersion, serverID, ]);}export async function getLastMutationID(t: Transaction, clientID: string) { const clientRow = await t.oneOrNone( 'select last_mutation_id from replicache_client where id = $1', clientID, ); if (!clientRow) { return 0; } return parseInt(clientRow.last_mutation_id);}async function setLastMutationID( t: Transaction, clientID: string, clientGroupID: string, mutationID: number, version: number,) { const result = await t.result( `update replicache_client set client_group_id = $2, last_mutation_id = $3, version = $4 where id = $1`, [clientID, clientGroupID, mutationID, version], ); if (result.rowCount === 0) { await t.none( `insert into replicache_client ( id, client_group_id, last_mutation_id, version ) values ($1, $2, $3, $4)`, [clientID, clientGroupID, mutationID, version], ); }}async function createMessage( t: Transaction, {id, from, content, order}: MessageWithID, version: number,) { await t.none( `insert into message ( id, sender, content, ord, deleted, version) values ($1, $2, $3, $4, false, $5)`, [id, from, content, order, version], );}async function sendPoke() { // TODO} Add the handler to Express modifying the file `server/src/main.ts` with the `app.post` route: import { handlePush } from './push';//...app.use(express.urlencoded({extended: true}), express.json(), errorHandler);app.post('/api/replicache/pull', handlePull);app.post('/api/replicache/push', handlePush);if (process.env.NODE_ENV === 'production') {//... Restart the server, navigate to http://localhost:5173/ and make some changes. You should now see changes getting saved in the server console output. But if we check another browser, or an incognito window, the change isn't there. What gives? In the next section, we implement Dynamic Pull to propagate changes between users. --- ## Page: https://doc.replicache.dev/byob/dynamic-pull Even though in the previous step we're making persistent changes in the database, we still aren't _serving_ that data in the pull endpoint – it's still static 🤣. Let's fix that now. The implementation of pull will depend on the backend strategy you are using. For the Global Version strategy we're using, the basics steps are: * Open a transaction * Read the latest global version from the database * Build the response patch: * If the request cookie is null, this patch contains a \`put\` for each entity in the database that isn't deleted * Otherwise, this patch contains only entries that have been changed since the request cookie * Build a map of changes to client \`lastMutationID\` values: * If the request cookie is null, this map contains an entry for every client in the requesting \`clientGroup\` * Otherwise, it contains only entries for clients that have changed since the request cookie * Return the patch, the current global \`version\`, and the \`lastMutationID\` changes as a \`PullResponse\` struct ## Implement Pull Replace the contents of `server/src/pull.ts` with this code: import {serverID, tx, type Transaction} from './db';import type {PatchOperation, PullResponse} from 'replicache';import type {Request, Response, NextFunction} from 'express';export async function handlePull( req: Request, res: Response, next: NextFunction,): Promise<void> { try { const resp = await pull(req, res); res.json(resp); } catch (e) { next(e); }}async function pull(req: Request, res: Response) { const pull = req.body; console.log(`Processing pull`, JSON.stringify(pull)); const {clientGroupID} = pull; const fromVersion = pull.cookie ?? 0; const t0 = Date.now(); try { // Read all data in a single transaction so it's consistent. await tx(async t => { // Get current version. const {version: currentVersion} = await t.one<{version: number}>( 'select version from replicache_server where id = $1', serverID, ); if (fromVersion > currentVersion) { throw new Error( `fromVersion ${fromVersion} is from the future - aborting. This can happen in development if the server restarts. In that case, clear appliation data in browser and refresh.`, ); } // Get lmids for requesting client groups. const lastMutationIDChanges = await getLastMutationIDChanges( t, clientGroupID, fromVersion, ); // Get changed domain objects since requested version. const changed = await t.manyOrNone<{ id: string; sender: string; content: string; ord: number; version: number; deleted: boolean; }>( 'select id, sender, content, ord, version, deleted from message where version > $1', fromVersion, ); // Build and return response. const patch: PatchOperation[] = []; for (const row of changed) { const {id, sender, content, ord, version: rowVersion, deleted} = row; if (deleted) { if (rowVersion > fromVersion) { patch.push({ op: 'del', key: `message/${id}`, }); } } else { patch.push({ op: 'put', key: `message/${id}`, value: { from: sender, content, order: ord, }, }); } } const body: PullResponse = { lastMutationIDChanges: lastMutationIDChanges ?? {}, cookie: currentVersion, patch, }; res.json(body); res.end(); }); } catch (e) { console.error(e); res.status(500).send(e); } finally { console.log('Processed pull in', Date.now() - t0); }}async function getLastMutationIDChanges( t: Transaction, clientGroupID: string, fromVersion: number,) { // eslint-disable-next-line @typescript-eslint/naming-convention const rows = await t.manyOrNone<{id: string; last_mutation_id: number}>( `select id, last_mutation_id from replicache_client where client_group_id = $1 and version > $2`, [clientGroupID, fromVersion], ); return Object.fromEntries(rows.map(r => [r.id, r.last_mutation_id]));} Because the previous pull response was hard-coded and not really reading from the database, you'll now have to clear your browser's application data to see consistent results. On Chrome/OSX for example: **cmd+opt+j → Application tab -> Storage -> Clear site data**. Once you do that, you can make a change in one browser and then refresh a different browser and see them round-trip: Also notice that if we go offline for awhile, make some changes, then come back online, the mutations get sent when possible. We don't have any conflicts in this simple data model, but Replicache makes it easy to reason about most conflicts. See the How Replicache Works for more details. The only thing left is to make it live — we obviously don't want the user to have to manually refresh to get new data 🙄. ## Next The next section implements realtime updates. --- ## Page: https://doc.replicache.dev/byob/next We've setup a simple realtime offline-enabled chat application against a vanilla serverless/Postgres stack with the help of Replicache. It's a little bit more work than an all-in-one system like Firebase, but you can implement it directly against your own stack without reliance on a giant third-party system. This particular application is trivial, but the techniques generalize to much more complex systems. For example, see Repliear our realtime collaborative bug tracker. ## Next Steps * Learn about other backend strategies that have better performance or flexibility. * Learn how to share mutator code between client and server. * Check out Repliear, a much more fully-featured sample. --- ## Page: https://doc.replicache.dev/strategies/reset The Reset Strategy is the easiest possible strategy: it sends the entire client view on every pull response, so no patch calculation is necessary at all. Sending the entire client view on each pull this way is very inefficient, so this approach is not usually recommended. That said, we do have customers that use this strategy in production, and it works if your data changes infrequently or is very small. ## Schema In addition to your own normal domain data, your backend database will need to store two additional entities to support Replicache: // A group of related ReplicacheClients. Typically there is one per browser// profile.type ReplicacheClientGroup = { // Globally unique ID, generated by Replicache. id: string; // Optional, but required if the application is authenticated. The userID // that created this ReplicacheClientGroup. userID: any;};// An instance of the Replicache JS class that has ever synced with the server.type ReplicacheClient = { // Globally unique ID, generated by Replicache. id: string; // The ClientGroup this client is part of. clientGroupID: string; // Last mutation the server has processed from this client. lastMutationID: number;}; ### Push Replicache sends a `PushRequest` to the push endpoint. For each mutation described in the request body, the push endpoint should: 1. `let errorMode = false` 2. Begin transaction 3. Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to: { id: body.clientGroupID, userID} 4. Verify the requesting user owns the specified client group. 5. Read the `ReplicacheClient` for `mutation.clientID` or default to: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: 0,} 6. Verify the requesting client group owns the requested client. 7. `let nextMutationID = client.lastMutationID + 1` 8. Rollback transaction and skip this mutation if already processed (`mutation.id < nextMutationID`) 9. Rollback transaction and error if mutation from the future (`mutation.id > nextMutationID`) 10. If `errorMode != true` then: 1. Try to run business logic for mutation 2. If error: 1. Log error 2. `set errorMode = true` 3. Abort transaction 4. Repeat these steps at the beginning 11. Write `ReplicacheClientGroup`: { id: body.clientGroupID, userID,} 12. Write `ReplicacheClient`: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: nextMutationID,} 13. Commit transaction After the loop is complete, poke clients to cause them to pull. ## Pull Replicache sends a `PullRequest` to the pull endpoint. The endpoint should: 1. Begin transaction 2. Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to: { id: body.clientGroupID, userID} 3. Verify the requesting client group owns the requested client. 4. Read all rows from the database that should be in the client view. 5. Read all `ReplicacheClient` records for the requested client group. 6. Create a `PullResponse` with: 1. `cookie` set to the server's current timestamp as an integer. 2. `lastMutationIDChanges` set to the `lastMutationID` for every client in the client group. 3. `patch` set to `op:clear` followed by `op:put` for every row in the view. ## Example We do not currently have an example of this strategy. ## Variations Because of the fact that this returns a reset patch, read authorizaton works naturally. Just update the query used to build the patch in the pull response to obey whatever auth rules you like. ### Early Exit There is no need to process every mutation submitted to the push endpoint. You can exit early as long as `lastMutationID` is set to whatever the last processed mutation was. This can ocassionally be useful if clients can accumulate large amounts of mutations while offline and you want to keep the runtime of the push handler under some limit. ### Batching You don't need to process each mutation in its own transaction. The entire push can be run inside one transaction, or you can do smaller batches. --- ## Page: https://doc.replicache.dev/strategies/global-version A single global `version` is stored in the database and incremented on each push. Entities have a `lastModifiedVersion` field which is the global version the entity was last modified at. The global version is returned as the cookie to Replicache in each pull, and sent in the request of the next pull. Using this we can find all entities that have changed since the last pull and calculate the correct patch. While simple, the Global Version Strategy does have concurrency limits because all pushes server-wide are serialized, and it doesn't support advanced features like incremental sync and read authorization as easily as row versioning. ## Schema The schema builds on the schema for the Reset Strategy, and adds a few things to support the global version concept. // Tracks the current global version of the database. There is only one of// these system-wide.type ReplicacheSpace = { version: number;};type ReplicacheClientGroup = { // Same as Reset Strategy. id: string; userID: any;};type ReplicacheClient = { // Same as Reset Strategy. id: string; clientGroupID: string; lastMutationID: number; // The global version this client was last modified at. lastModifiedVersion: number;};// Each of your domain entities will have two extra fields.type Todo = { // ... fields needed for your application (id, title, complete, etc) // The global version this entity was last modified at. lastModifiedVersion: number; // "Soft delete" for marking whether this entity has been deleted. deleted: boolean;}; ## Push The push handler is the same as in the Reset Strategy, but with changes to mark domain entities with the version they were changed at. The changes from the Reset Strategy are marked below **in bold**. Replicache sends a `PushRequest` to the push endpoint. For each mutation described in the request body, the push endpoint should: 1. `let errorMode = false` 2. Begin transaction 3. Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to: { id: body.clientGroupID, userID} 4. Verify the requesting user owns the specified client group. 5. **Read the `ReplicacheClient` for `mutation.clientID` or default to:** { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: 0, lastModifiedVersion} 6. Verify the requesting client group owns the requested client. 7. `let nextMutationID = client.lastMutationID + 1` 8. **Read the global `ReplicacheSpace`.** 9. **`let nextVersion = replicacheSpace.version + 1`** 10. Rollback transaction and skip this mutation if already processed (`mutation.id < nextMutationID`) 11. Rollback transaction and error if mutation from the future (`mutation.id > nextMutationID`) 12. If `errorMode != true` then: 1. Try to run business logic for mutation 1. **Set `lastModifiedVersion` for any modified rows to `nextVersion`.** 2. **Set `deleted = true` for any deleted entities.** 2. If error: 1. Log error 2. `set errorMode = true` 3. Abort transaction 4. Repeat these steps at the beginning 13. **Write `ReplicacheSpace`:** { version: nextVersion,} 14. Write `ReplicacheClientGroup`: { id: body.clientGroupID, userID,} 15. **Write `ReplicacheClient`:** { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: nextMutationID, lastModifiedVersion: nextVersion,} 16. Commit transaction After the loop is complete, poke clients to cause them to pull. ## Pull The pull handler is the same as in the Reset Strategy, but with changes to read only entities that are newer than the last pull. The changes from the Reset Strategy are marked below **in bold**. Replicache sends a `PullRequest` to the pull endpoint. The endpoint should: 1. Begin transaction 2. **`let prevVersion = body.cookie ?? 0`** 3. Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to: { id: body.clientGroupID, userID} 4. Verify the requesting client group owns the requested client. 5. **Read the global `ReplicacheSpace` entity** 6. **Read all domain entities from the database that have `lastModifiedVersion > prevVersion`** 7. **Read all `ReplicacheClient` records for the requested client group that have `lastModifiedVersion > prevVersion`.** 8. Create a `PullResponse` with: 1. **`cookie` set to `space.version`** 2. **`lastMutationIDChanges` set to the `lastMutationID` for every client that has changed.** 3. `patch` set to: 1. **`op:del` for all domain entities that have changed and are deleted** 2. **`op:put` for all domain entities that have changed and aren't deleted** ## Example See todo-nextjs for an example of this strategy. Note that this sample also uses Shared Mutators and batches the mutations into a single transaction. So the logic is a little different than above, but equivalent. ## Why Not Use Last-Modified? When presented with the pull endpoint, most developers' first instinct will be to implement it using last-modified timestamps. This can't be done correctly, and we strongly advise against trying. Here's why: 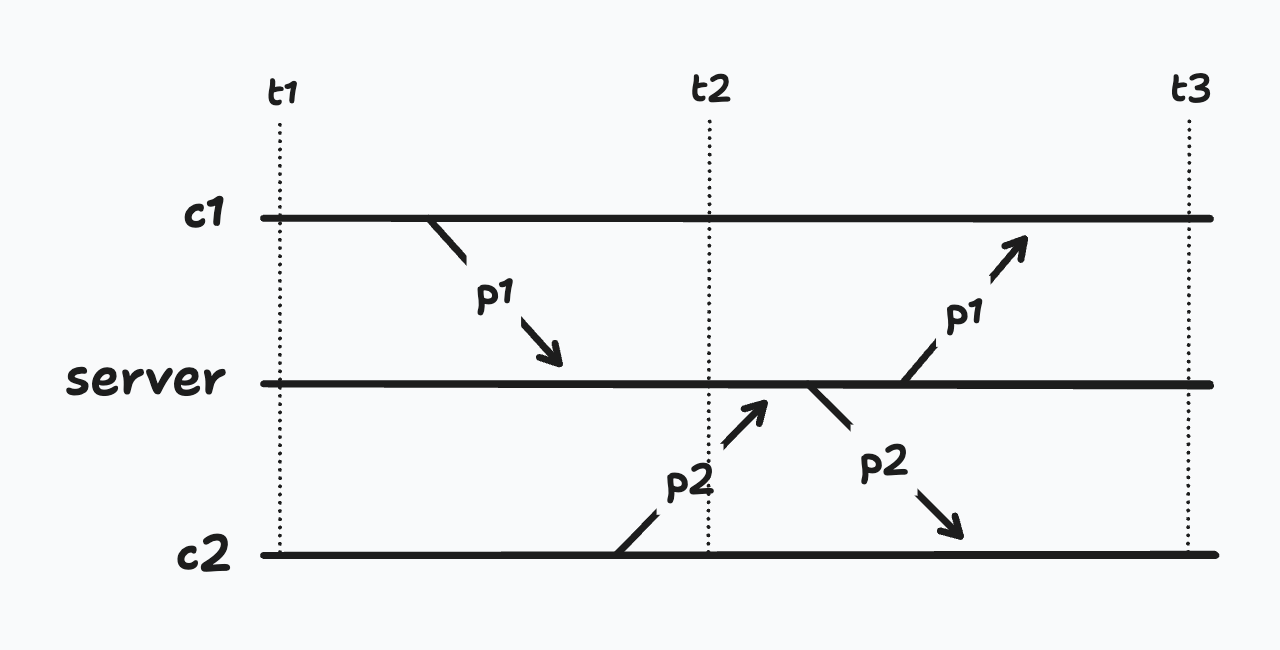 Imagine that a Replicache client `c1` sends a push `p1`. The server receives `p1` at time `t1` and begins processing the push, updating all changed records with `lastModified = t1`. While the push is being processed, some other client `c2` sends a pull `p2`. The server receives the pull at time `t2` and processes it, returning all changes necessary to bring `c2` up to `t2`. Finally, `p1` completes and commits, writing new records with timestamp `t1`. Now `c2` thinks it has changes up to `t2`, but is actually missing the ones from `p1`. This problem will never resolve. On the next pull, `c2` will send timestamp `t2`. The server won't send the missing changes since they have an earlier timestamp. Unlike in a traditional web app, a refresh won't solve this problem. On refresh, Replicache will just read the incorrectly cached data from the browser. In local-first systems it's important to ensure correct synchronization, since cached data is permanent. The problem with using last-modified timestamps is that the linear nature of timestamps assumes a linear series of modifications to the database. But databases don't work that way – they can (and often do) do things in parallel. The Global Version strategy resolves this problem by forcing the database to process pushes serially, making a single monotonic integer cookie sufficient to represent the state of the DB. The Row Version strategy resolves it by using a cookie that can correctly represent DB state, even with parallel execution. ## Challenges ### Performance `GlobalVersion` functions as a global lock. This limits possible concurrency of your backend: if each push takes 20ms then the maximum number of pushes per second for your server is 50. ### Soft Deletes Soft Deletes are annoying to maintain. All queries to the database need to be aware of the `deleted` column and filter appropriately. There are other ways to implement soft deletes (see below), but they are all at least a little annoying. In many applications, users only have access to a subset of the total data. If a user gains access to an entity they didn't previously have access to, pull should reflect that change. But that won't happen using just the logic described above, because the entity itself didn't change, and therefore its `lastModifiedVersion` field won't change. To correctly implement auth changes with this strategy, you also need to track those auth changes somehow — either by having those changes bump the `lastModifiedVersion` fields of affected docs, or else by tracking changes to the auth rules themselves with their own `lastModifiedVersion` fields. ## Variations ### Early Exit, Batch Size Just as in the Reset strategy, you can early exit the push handler or process mutations in batches. ### Alternative Soft Delete There are other ways to implement soft deletes. For example for each entity in your system you can have a separate collection of just deleted entities: type Monster = { // other fields ... // note: no `deleted` here // The version of the database this entity was last changed during. replicacheVersion: number;};type MonsterDeleted = { // The version of the db the monster was deleted at replicacheVersion: number;}; This makes read queries more natural (can just query Monsters collection as normal). But deletes are still weird (must upsert into the `MonstersDeleted` collection). --- ## Page: https://doc.replicache.dev/strategies/per-space-version The Per-Space Version Strategy is the same as the The Global Version Strategy except it has more than one space. This increases throughput of the server. Instead of approximately 50 pushes per second across your entire server, you can get 50 pushes per space. A common example of how people partition by space is along organizational boundaries in a SaaS application. Each customer org would be its own space and you'd thereby get 50 pushes per second per organization. The tradeoffs to keep in mind is that you lose consistency guarantees across spaces. Replicache mutations are atomic: you can move data within a space, rename, copy, etc., and you have a guarantee that the entire change happens or none of it does. But this guarantee does not apply across spaces. Example Imagine moving data from one space to another. Because there is no transactional guarantees across spaces, during the move, the user might see the data exist in both spaces, or neither. While this might just seem like a minor UI annoyance, keep in mind that it means that if you have IDs that refer to data across spaces, there is no guarantee that the data actually exists at the moment you render. You'll have to defensively guard against invalid pointers into other spaces. This is why partitioning makes most sense at very high-level boundaries, like organizations, so that it will be uncommon in your application to want to have data from two spaces interact. ## Schema The schema generalizes the schema from the Global Version Strategy: type ReplicacheSpace = { id: string; // Same as Global Version Strategy. version: number;};type ReplicacheClientGroup = { // Same as Global Version Strategy. id: string; userID: any; spaceID: string;};type ReplicacheClient = { // Same as Global Version Strategy. id: string; clientGroupID: string; lastMutationID: number; lastModifiedVersion: number;};// Each of your domain entities will have three additional fields.type Todo = { // ... fields needed for your application (id, title, complete, etc) // Same as Global Version Strategy. lastModifiedVersion: number; deleted: boolean; spaceID: string;}; ## Push The push handler should receive the `spaceID` being operated on as an HTTP parameter. The logic is otherwise almost identical to the Global Version Strategy, with minor changes to deal with spaces. The changes from the Global Version Strategy are marked below **in bold**. Replicache sends a `PushRequest` to the push endpoint. For each mutation described in the request body, the push endpoint should: 1. `let errorMode = false` 2. Begin transaction 3. **Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to:** { id: body.clientGroupID, spaceID, userID} 4. Verify the requesting user owns the specified client group. 5. **Verify the specified client group is part of the requesting space.** 6. Read the `ReplicacheClient` for `mutation.clientID` or default to: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: 0, lastModifiedVersion} 7. Verify the requesting client group owns the requested client. 8. `let nextMutationID = client.lastMutationID + 1` 9. **Read the `ReplicacheSpace` for `request.params.spaceID`** 10. `let nextVersion = replicacheSpace.version + 1` 11. Rollback transaction and skip this mutation if already processed (`mutation.id < nextMutationID`) 12. Rollback transaction and error if mutation from the future (`mutation.id > nextMutationID`) 13. If `errorMode != true` then: 1. Try to run business logic for mutation 1. Set `lastModifiedVersion` for any modified rows to `nextVersion`. 2. Set `deleted = true` for any deleted entities. 2. If error: 1. Log error 2. `set errorMode = true` 3. Abort transaction 4. Repeat these steps at the beginning 14. **Write `ReplicacheSpace`:** { id: body.clientGroupID, spaceID: request.params.spaceID, version: nextVersion,} 15. **Write `ReplicacheClientGroup`:** { id: body.clientGroupID, userID, spaceId,} 16. Write `ReplicacheClient`: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: nextMutationID, lastModifiedVersion: nextVersion,} 17. Commit transaction After the loop is complete, poke clients to cause them to pull. ## Pull The pull handler is the same as in the Global Version Strategy, but with mionr changes to support multiple spaces. Changes from the Global Version Strategy are **marked in bold**. Replicache sends a `PullRequest` to the pull endpoint. The pull handler should also receive the `spaceID` being operated on as an HTTP parameter. The endpoint should: 1. Begin transaction 2. `let prevVersion = body.cookie ?? 0` 3. Read the `ReplicacheClientGroup` for `body.clientGroupID` from the database, or default to: { id: body.clientGroupID, userID} 4. Verify the requesting client group owns the requested client. 5. Verify the client group is part of the requesed space. 6. **Read the `ReplicacheSpace` entity for `request.params.spaceID`** 7. **Read all domain entities from the database that have `spaceID == request.params.spaceID AND lastModifiedVersion > prevVersion`** 8. Read all `ReplicacheClient` records for the requested client group that have `lastModifiedVersion > prevVersion`. 9. Create a `PullResponse` with: 1. `cookie` set to `space.version` 2. `lastMutationIDChanges` set to the `lastMutationID` for every client that has changed. 3. `patch` set to: 1. `op:del` for all domain entities that have changed and are deleted 2. `op:put` for all domain entities that have changed and aren't deleted ## Example Todo-WC is a simple example of per-space versioning. Repliear is a more involved example. Note that both examples also uses Shared Mutators and batch the mutations into a single transaction. So the logic is a little different than described above, but equivalent. ## Challenges * Like the Global Version strategy, soft deletes can be annoying. * Also like the Global Version strategy, it is difficult to implement features like read authentication and partial sync. * It can be hard in some applications to find a way to partition spaces naturally. * 50 pushes per second per space can still be insufficient for some applications. ## Variations The same variations available to The Global Version Strategy apply here. --- ## Page: https://doc.replicache.dev/strategies/row-version This strategy has a few big advantages over the other strategies: * The Client View can be **computed** dynamically — it can be any arbitrary query over the database, including filters, joins, windows, auth, etc. This _pull query_ can even change per-user. If the user checks a box in the UI, the query might change from _“all active threads"_ to _"all active threads, or first 20 inactive threads ordered by modified-date”_. * It does not require global locks or the concept of spaces. * It does not require a soft deletes. Entities can be fully deleted. The disadvantage is that it pays for this flexibility in increased implementation complexity and read cost. Pulls become more expensive because they require a few queries, and they aren’t a simple index scan. However because there are no global locks, the database should be easier to scale. ## Client View Records A _Client View Record_ (CVR) is a minimal representation of a Client View snapshot. In other words, it captures what data a Client Group had at a particular moment in time. In TypeScript, it might look like: type CVR = { id: string; // Map of clientID->lastMutationID pairs, one for each client in the // client group. lastMutationIDs: Record<string, number>; // Map of key->version pairs, one for each entity in the client view. entities: Record<string, number>;}; One CVR is generated for each pull response and stored in some ephemeral storage. The storage doesn’t need to be durable — if the CVR is lost, the server can just send a reset patch. And the storage doesn’t need to be transactional with the database. Redis is fine. The CVRs are stored keyed under a random unique ID which becomes the cookie sent to Replicache. During pull, the server uses the cookie to lookup the CVR associated with the previous pull response. It then computes a new CVR for the latest server state and diffs the two CVRs to compute the delta to send to the client. ## Schema type ReplicacheClientGroup = { // Same as the Reset Strategy. id: string; userID: any; // Replicache requires that cookies are ordered within a client group. // To establish this order we simply keep a counter. cvrVersion: number;};type ReplicacheClient = { // Same as the Reset Strategy. id: string; clientGroupID: string; lastMutationID: number;};// Each of your domain entities will have one extra field.type Todo = { // ... fields needed for your application (id, title, complete, etc) // Incremented each time this row is updated. // In Postgres, there is no need to declare this as Postgres tracks its // own per-row version 'xmin' which we can use for this purpose: // https://www.postgresql.org/docs/current/ddl-system-columns.html version: number;}; ## Push The push handler is similar to the Reset Strategy, except for with some modifications to track changes to clients and domain entities. The changes from the Reset Strategy are marked **in bold**. Replicache sends a `PushRequest` to the push endpoint. For each mutation described in the request body, the push endpoint should: 1. `let errorMode = false` 2. Begin transaction 3. **`getClientGroup(body.clientGroupID)`, or default to:** { id: body.clientGroupID, userID cvrVersion: 0,} 4. Verify requesting user owns specified client group. 5. `getClient(mutation.clientID)` or default to: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: 0,} 6. Verify requesting client group owns requested client 7. `let nextMutationID = client.lastMutationID + 1` 8. Rollback transaction and skip mutation if already processed (`mutation.id < nextMutationID`) 9. Rollback transaction and error if mutation from future (`mutation.id > nextMutationID`) 10. If `errorMode != true` then: 1. Try business logic for mutation 1. **Increment `version` for modified rows** 2. Note: Soft-deletes _not_ required – you can delete rows normally as part of mutations 2. If error: 1. Log error 2. Abort transaction 3. Retry this transaction with `errorMode = true` 11. **`putClientGroup()`**: { id: body.clientGroupID, userID, cvrVersion: clientGroup.cvrVersion,} 12. `putClient()`: { id: mutation.clientID, clientGroupID: body.clientGroupID, lastMutationID: nextMutationID,} 13. Commit transaction After the loop is complete, poke clients to cause them to pull. ## Pull The pull logic is more involved than other strategies because of the need to manage the CVRs. Replicache sends a `PullRequest` to the pull endpoint. The endpoint should: 1. `let prevCVR = getCVR(body.cookie.cvrID)` 2. `let baseCVR = prevCVR` or default to: { "id": "", "entries": {}} 3. Begin transaction 4. `getClientGroup(body.clientGroupID)`, or default to: { id: body.clientGroupID, userID, cvrVersion: 0,} 5. Verify requesting client group owns requested client. 6. Read all id/version pairs from the database that should be in the client view. This query can be any arbitrary function of the DB, including read authorization, paging, etc. 7. Read all clients in the client group. 8. Build `nextCVR` from entities and clients. 9. Calculate the difference between `baseCVR` and `nextCVR` 10. If prevCVR was found and two CVRs are identical then exit this transaction and return a no-op PullResopnse to client: { cookie: prevCookie, lastMutationIDChanges: {}, patch: [],} 11. Fetch all entities from database that are new or changed between `baseCVR` and `nextCVR` 12. `let clientChanges = clients that are new or changed since baseCVR` 13. `let nextCVRVersion = Math.max(pull.cookie?.order ?? 0, clientGroup.cvrVersion) + 1` caution It's important to default to the incoming cookie's order because when Replicache creates a new ClientGroup, it can fork from an existing one, and we need the order to not go backward. 14. `putClientGroup()`: { id: clientGroup.id, userID: clientGroup.userID, cvrVersion: nextCVRVersion,} 15. Commit 16. `let nextCVRID = randomID()` 17. `putCVR(nextCVR)` 18. Create a `PullResponse` with: 1. A patch with: 1. `op:clear` if `prevCVR === undefined` 2. `op:put` for every created or changed entity 3. `op:del` for every deleted entity 2. `{order: nextCVRVersion, cvrID}` as the cookie. 3. `lastMutationIDChanges` with entries for every client that has changed. ## Example See todo-row-versioning for a complete example of this strategy, including sharing and dynamic authorization. ## Queries and Windowing The query that builds the client view can change at any time, and can even be per-user. However, slight care must be taken because of the way that Replicache data is shared between tabs. Changing the pull query in one tab changes it for other tabs that are sharing the same Replicache. Without coordination, this could result in two tabs “fighting” over the current query. The solution is to sync the current query with Replicache (🤯). That way it will be automatically synced to all tabs. * Add a new entity to the backend database to store the current query for a profile. Like other entities it should have a `version` field. Let’s say: `/control/<userid>/query`. * When computing the pull, first read this value. If not present, use the default query. Include this entity in the pull response as any other entity. * In the UI can use the query data in the client view to check and uncheck filter boxes, etc., just like other Replicache data! * Add mutations that modify this entity. ## Variations * The CVR can be passed into the database as an argument enabling the pull to be computed in a single DB round-trip. * The CVR can be **stored** in the primary database, allowing the patch to be computed with database joins and dramatically reducing amount of data read from DB. * The per-row version number can also be a hash over the row serialization, or even a random GUID. These approaches might perform better in some datastores since it eliminates a read of the existing row during write. --- ## Page: https://doc.replicache.dev/reference/server-push The Push Endpoint applies batches of mutations to the server. For more information, see How Replicache Works — Push. ## Configuration Specify the URL with the `pushURL` constructor option: const rep = new Replicache({ // ... pushURL: '/replicache-push',}); ## Method Replicache always fetches the push endpoint using HTTP POST: POST /replicache-push HTTP/2 Replicache sends the following HTTP request headers with push requests: Content-type: application/jsonAuthorization: <auth>X-Replicache-RequestID: <request-id> ### `Content-type` Always `application/json`. This is a string that should be used to authorize the user. It is prudent to also verify that the `clientID` passed in the `PushRequest` in fact belongs to that user. If not, and users' `clientID`s are somehow visible, a user could push mutations on behalf of another user. The auth token is set by defining `auth`. ### `X-Replicache-RequestID` The request ID is useful for debugging. It is of the form `<clientid>-<sessionid>-<request count>`. The request count enables one to find the request following or preceeding a given request. The sessionid scopes the request count, ensuring the request id is probabilistically unique across restarts (which is good enough). This header is useful when looking at logs to get a sense of how a client got to its current state. ## HTTP Request Body When pushing we `POST` an HTTP request with a JSON encoded body. type PushRequest = { pushVersion: 1; clientGroupID: string; mutations: Mutation[]; profileID: string; schemaVersion: string;};type Mutation = { clientID: string; id: number; name: string; args: ReadonlyJSONValue; timestamp: number;}; ### `pushVersion` Version of the type Replicache uses for the request body. The current version is `1`. ### `clientGroupID` The `clientGroupID` of the requesting Replicache client group. ### `mutations` An array of mutations to be applied to the server, each having: * `clientID`: The ID of the client within the group that created the mutation. * `id`: A sequential per-client unsigned integer. Each mutation will have an ID exactly one greater than the previous one in the list. * `name`: The name of the mutator that was invoked (e.g., from Replicache.mutate). * `args`: The arguments that were passed to the mutator. * `timestamp`: The `DOMHighResTimeStamp` from the source client when the mutation was initially run. This field is not currently used by the protocol. ### `profileID` The `profileID` of the requesting Replicache instance. All clients within a browser profile share the same `profileID`. ### `schemaVersion` This is something that you control and should identify the schema of your client view. This ensures that you are sending data of the correct type so that the client can correctly handle the data. The `schemaVersion` can be set in the `ReplicacheOptions` when creating your instance of `Replicache`. ## HTTP Response ### HTTP Response Status * `200` for success * `401` for auth error — Replicache will reauthenticate using `getAuth` if available * All other status codes are considered to be errors Replicache will exponentially back off sending pushes in the case of both network level and HTTP level errors. ### HTTP Response Body The response body to the push endpoint is ignored. ## Semantics ### Unknown Client IDs The first time a client pushes or pulls, it will have no client record on the server. These client records could be created in either the push or pull handlers (or both), but we recommend the push handler for a few reasons: * The pull handler can be read-only which enables useful optimizations and safety measures in many databases. * The push handler is called less frequently so it makes sense to put the write lock there. * Having all the writes in the push handler makes reasoning about the system easier. See Remote Mutations for an example implementation. ### Mutation Status The server marks indicates that mutation was applied by returning a `lastMutationID` in the `PullResponse` greater than or equal to its mutation id. Replicache will continue retrying a mutation until the server marks the mutation processed in this way. ### Mutations are Atomic and Ordered The effects of a mutation (its changes to the underlying datastore) and the corresponding update to the `lastMutationID` must be revealed atomically by the datastore. For example, in a SQL database both changes should be committed as part of the same transaction. If a mutation's effects are not revealed atomically with the update to the client's `lastMutationID`, then the sync protocol will have undefined and likely mysterious behavior. Said another way, if the `PullResponse` indicates that mutation `42` has been processed, then the effects of mutation `42` (and all prior mutations from this client) must be present in the `PullResponse`. Additionally the effects of mutation `43` (or any higher mutation from this client) must _not_ be present in the `PullResponse`. ### Applying Mutations in Batches The simplest way to process mutations is to run and commit each mutation and its `lastMutationID` update in its own transaction. However, for efficiency, you can apply a batch of mutations together and then update the database with their effects and the new `lastMutationID` in a single transaction. The todo-nextjs sample contains an example of this pattern in push.ts. ### Error Handling **If a mutation is invalid or cannot be handled, the server must still mark the mutation as processed** by updating the `lastMutationID`. Otherwise, the client will keep trying to send the mutation and be blocked forever. If the server knows that the mutation cannot be handled _now_, but will be able to be handled later (e.g., because some server-side resource is unavailable), the push endpoint can abort processing without updating the `lastMutationID`. Replicache will consider the server offline and try again later. For debugging/monitoring/understandability purposes, the server can _optionally_ return an appropriate HTTP error code instead of 200 e.g., HTTP 500 for internal error). However, this is for developer convenience only and has no effect on the sync protocol. caution Temporary errors block synchronization and thus should be used carefully. A server should only do this when it definitely will be able to process the mutation later. ## Push Launch Checklist * Ensure that the `lastMutationID` for a client is updated transactionally along with the pushed mutations' effects. * All mutations with `id`s less than or equal to the client's current `lastMutationID` must be ignored. * All mutations with `id`s greater than the client's current `lastMutationID+1` must be ignored. * Think carefully about your error handling policy. It is possible to deadlock a client if it pushes a mutation that _always_ causes an error that stops processing. No other mutations from that client can make progress in this case. A reasonable default starting point might be along these lines: * If a temporary error is encountered that might be resolved on retry, halt processing mutations and return. * If a permanent error is encountered such that the mutation will never be appliable, ignore that mutation and increment the `lastMutationID` as if it were applied. * Ignore all `PushRequest`s with an unexpected `pushVersion`. --- ## Page: https://doc.replicache.dev/reference/server-pull The Pull Endpoint serves the Client View for a particular Replicache client. For more information, see How Replicache Works — Pull. ## Configuration Specify the URL with the `pullURL` constructor option: const rep = new Replicache({ // ... pullURL: '/replicache-pull',}); ## Method Replicache always fetches the pull endpoint using HTTP POST: POST /replicache-pull HTTP/2 Replicache sends the following HTTP request headers with pull requests: Content-type: application/jsonAuthorization: <auth>X-Replicache-RequestID: <request-id> ### `Content-type` Always `application/json`. This is a string that should be used to authorize a user. It is prudent to also verify that the `clientID` passed in the `PushRequest` in fact belongs to that user. If not, and users' `clientID`s are somehow visible, a user could pull another user's Client View. The auth token is set by defining `auth`. ### `X-Replicache-RequestID` The request ID is useful for debugging. It is of the form `<clientid>-<sessionid>-<request count>`. The request count enables one to find the request following or preceeding a given request. The sessionid scopes the request count, ensuring the request id is probabilistically unique across restarts (which is good enough). This header is useful when looking at logs to get a sense of how a client got to its current state. ## HTTP Request Body When pulling we `POST` an HTTP request with a JSON encoded body. type PullRequest = { pullVersion: 1; clientGroupID: string; cookie: JSONValue; profileID: string; schemaVersion: string;}; ### `pullVersion` Version of the type Replicache uses for the response JSON. The current version is `1`. ### `clientGroupID` The `clientGroupID` of the requesting Replicache client group. ### `cookie` The cookie that was received last time a pull was done. `null` if this is the first pull from this client. ### `profileID` The `profileID` of the requesting Replicache instance. All clients within a browser profile share the same `profileID`. It can be used for windowing the Client View, which one typically wants to do per-browser-profile, not per-client. ### `schemaVersion` This is something that you control and should identify the schema of your client view. This ensures that you are sending data of the correct type so that the client can correctly handle the data. The `schemaVersion` can be set in the `ReplicacheOptions` when creating your instance of `Replicache`. ## HTTP Response ### HTTP Response Status * `200` for success * `401` for auth error — Replicache will reauthenticate using `getAuth` if available * All other status codes considered errors Replicache will exponentially back off sending pushes in the case of both network level and HTTP level errors. ### HTTP Response Body The response body is a JSON object of the `PullResponse` type: export type PullResponse = | PullResponseOK | ClientStateNotFoundResponse | VersionNotSupportedResponse;export type PullResponseOK = { cookie: Cookie; lastMutationIDChanges: Record<ClientID, number>; patch: PatchOperation[];};export type Cookie = | null | string | number | (ReadonlyJSONValue & {readonly order: number | string});/** * In certain scenarios the server can signal that it does not know about the * client. For example, the server might have lost all of its state (this might * happen during the development of the server). */export type ClientStateNotFoundResponse = { error: 'ClientStateNotFound';};/** * The server endpoint may respond with a `VersionNotSupported` error if it does * not know how to handle the {@link pullVersion}, {@link pushVersion} or the * {@link schemaVersion}. */export type VersionNotSupportedResponse = { error: 'VersionNotSupported'; versionType?: 'pull' | 'push' | 'schema' | undefined;}; ### `cookie` The `cookie` is an opaque-to-the-client value set by the server that is returned by the client in the next `PullRequest`. The server uses it to create the patch that will bring the client's Client View up to date with the server's. The cookie must be orderable (string or number) or an object with a special `order` field with the same constraints. For more information on how to use the cookie see Computing Changes for Pull. ### `lastMutationIDChanges` A map of clients whose `lastMutationID` have changed since the last pull. ### `patch` The patch the client should apply to bring its state up to date with the server. Basically this should be the delta between the last pull (as identified by the request cookie) and now. The `patch` supports 3 operations: type PatchOperation = | { op: 'put'; key: string; value: JSONValue; } | {op: 'del'; key: string} | {op: 'clear'}; #### `put` Puts a key value into the data store. The `key` is a `string` and the `value` is any `JSONValue`. #### `del` Removes a key from the data store. The `key` is a `string`. #### `clear` Removes all the data from the client view. Basically replacing the client view with an empty map. This is useful in case the request cookie is invalid or not known to the server, or in any other case where the server cannot compute a diff. In those cases, the server can use `clear` followed by a set of `put`s that completely rebuild the Client View from scratch. ## Computing Changes for Pull See Diff Strategies for information on different approaches to implementing pull. ## Handling Unknown Clients Replicache does not currently support deleting client records from the server. As such there is only one valid way a requesting clientID could be unknown to the server: the client is new and the record hasn't been created yet. For these new clients, our recommendation is: 1. Validate the requesting client is in fact new (`lastMutationID === 0`). If the client isn't new, then data must have been deleted from the server which is not allowed. The server should abort and return a 500. 2. Compute a patch and cookie as normal, and return `lastMutationID: 0`. The push handler should create the client record on first push. See Dynamic Pull for an example implementation. ## Pull Launch Checklist * Check the Launch to Production HOWTO for the checklist that is common for both push and pull. * Ensure that the `lastMutationID` returned in the response is read in the same transaction as the client view data (ie, is consistent with it). * If there is a problem with the `cookie` (e.g., it is unusable) return all data. This is done by first sending a `clear` op followed by multiple `put` ops. * Make sure that the client view is not a function of the client ID. When starting up Replicache, Replicache will fork the state of an existing client (client view and cookie) and create a new client (client view, client ID and cookie). * Ignore all pull requests with an unexpected `pullVersion`. * Do not use the `clientID` to look up what information was last sent to a client when computing the `PullResponse`. Since a `clientID` represents a unique running instance of `Replicache`, that design would result in each new tab pulling down a fresh snapshot. Instead, use the `cookie` feature of `PullResponse` to uniquely identify the data returned by pull. Replicache internally forks the cache when creating a new client and will reuse these cookie values across clients, resulting in new clients being able to startup from previous clients' state with minimal download at startup. --- ## Page: https://doc.replicache.dev/concepts/offline Replicache features robust support for offline operation. Specifically: 1. A tab can go offline and continue to operate for hours to days, then sync up smoothly when it reconnects. 2. Replicache's offline support is "local-first": Replicache reads and writes to local state before the network, meaning that it smoothly transmits online, offline, or slow/flaky networks. 3. Changes sync across tabs in the same browser profile, even while offline. 4. If your application has a way to start while offline (ie Service Worker, or Electron shell), you can start it and see changes made in a previous session. Note that the potential for serious conflicts grows the longer users are disconnected from each other. While Replicache will converge all clients to the same state, it won't always produce a resolution users would be happy with. If you intend for your application to be used for long periods of intensive offline use, we recommend implementing a concept of history so that users can undo merges that had unexpected results. Contact Us if you would like help thinking through how to do this. --- ## Page: https://doc.replicache.dev/concepts/consistency The Consistency Model of a distributed system like Replicache describes the guarantees the system makes about how operations are applied within the system. Replicache was designed in consultation with indepedent distributed systems expert Kyle Kingsbury of Jepsen. When properly integrated with your backend, Replicache provides Causal+ Consistency — one of the strongest consistency models possible in a synchronizing system. Causal+ Consistency essentially guarantees that the system is: * **Causal**: causally-related operations (mutations) always appear in their same causal order on all clients * **Convergent**: clients always converge on the same ordering of operations * **Progressive**: clients see progressively newer states of the world, and never see operations out of order Below find Jepsen's summary. ## Jepsen on Replicache Jepsen has evaluated Replicache's preliminary, internal design documents, but has not evaluated Replicache's actual code or behavior. As of October 25, 2019, Replicache's documentation describes a set of client libraries and an HTTP server for writing stateful, offline-first mobile applications against typical web services. Replicache uses arbitrary JavaScript transactions over a versioned document store on the client, and expects the web service to provide corresponding server-side transaction implementations. Like Bayou and Eventually Serializable Data Services, Replicache works towards a totally ordered prefix of _final_ transactions, while _tentative_ transactions, which have not yet been totally ordered, go through a shifting series of causally consistent orders after the locally-known final prefix of the total order. Replicache's state is always the product of _some_ order of atomically executed transactions, which simplifies proving some invariants. Tentative transactions execute speculatively, with causal consistency, but may be reordered, and re-executed arbitrarily many times, before their final order is known. This means their safety properties must hold under any (causally consistent) ordering of concurrent and future transactions. Tentative transactions can be thought of as an implementation of Statebox, but with causally consistent transaction ordering. Likewise, any CRDT can be implemented in Replicache tentative transactions alone, making them equivalent to CRDTs. However, Replicache's eventually serializable transaction order provides the ability to _upgrade_ selected transactions to strict serializability, at the cost of having to block for server acknowledgement. This could allow users to write hybrid commutative & non-commutative systems. Replicache's API does not expose an API for serializable transactions yet, but the listener API could, we suspect, make this possible. Casual+ is one of the strongest consistency models offline clients can ensure, and Jepsen is pleased to see additional interest in the consistency challenges of distributed mobile computing. --- ## Page: https://doc.replicache.dev/concepts/db-isolation-level **You should use Snapshot Isolation or better in your push and pull endpoints.** tip In PostgreSQL, this isolation level is confusingly called "REPEATABLE READ". This is often surprising to developers. Why does Replicache require such high level of consistency? The Replicache push and pull endpoints each do several reads and writes and these operations need to get values that represent a consistent snapshot of the database. For example, in the pull endpoint, we read the `lastMutationID` for one or more clients and also entity rows that have changed since the last pull. These values are returned to the client. It's important that if the server says mutation `42` was processed, that the `patch` returned by the pull response must include the changes from mutation `42`. If it doesn't, then the user will see their data disappear: Replicache will remove the optimistic version of mutation `42` and its effects, but no authoritative version of the data from that mutation is present yet. The reverse can also happen and in that case, the user might temporarily see a mutation run twice. Variations of this problem show up in the push endpoint too: we read the `lastMutationID` to know whether to process an individual mutation. But if we don't have a stable snapshot of the database inside the transaction, then we might read the value `42` for `lastMutationID` and decide to run mutation `43`, but the effects of mutation `43` are actually already in the database. We end up running the mutation twice. ## Do I really need to do this? It is technically possible – in some cases and with great care – to implement a correct push and pull endpoint with lower isolation levels. It requires a great deal of thought and we don't recommend it. If you still really want to do this please contact us. ## Why don't classic web apps have this problem? Classic web apps often _do_ have consistency problems due to low database isolation levels. But you don't notice it as much because they are usually just requesting tiny slices of data as you move around the app. You might see an inconsistency, but you move elsewhere in the app or refresh and it goes away. What we're trying to do with synchronizing systems like Replicache is to **stop** sending so many requests to the server, and especially to not have to wait on them. We want to send data to the client once, and just let it just read its own copy. In order to do that, the data the client has needs to be correct. We can't rely on reload to fix things, because reloads go to local storage, not the server! ## Rollbacks Snapshot isolation can cause transaction rollback when two transactions try to write the same row. In this case, all you need to do is retry the transaction. Replicache will retry pushes and pulls automatically, but in this case it's better to do it on the server. All our samples have code to do this. See, for example, `shouldRetryTransaction`. ## Performance Considerations The main consideration is that they can reduce write throughput if there are often transactions writing to the same value. Our strategies documentation notes the write throughput of each strategy, assuming snapshot isolation. --- ## Page: https://doc.replicache.dev/howto/share-mutators If your Replicache backend is written in JavaScript, it is possible to share mutator functions between client and server. This prevents you from having to write them twice. This does require that your backend datamodel is key/value oriented like Replicache, so that the same code can run against both storage systems with minimal branching. For example, our samples use PostgreSQL with a single `entry` table having `text` `key` and `JSON` `value` columns. Another option would be to use a document database, like Google Cloud Firestore. info Although using a relational database as a document store is somewhat unconventional, Postgres has excellent JSON support and does support this usage. This can be a very convenient way to get a Replicache project up and running quickly. ## `replicache-transaction` Helper Package We provide the `replicache-transaction` package to make this usage easier. It adapts Replicache's `WriteTransaction` interface to some backend key/value storage that you provide. See `PostgresTransaction` in `replicache-express` for an example. ## Other Backend Datastores If you want to use Replicache with some non-key/value backend datastore, such as a normalized SQL database, it typically makes more sense to implement the mutators twice. See Replicache on Rails for a JS helper library that can automate much of the client-side. --- ## Page: https://doc.replicache.dev/api/classes/IDBNotFoundError This Error is thrown when we detect that the IndexedDB has been removed. This does not normally happen but can happen during development if the user has DevTools open and deletes the IndexedDB from there. ## Hierarchy * `Error` ↳ **`IDBNotFoundError`** ## Constructors ### constructor • **new IDBNotFoundError**(`message?`) #### Parameters | Name | Type | | --- | --- | | `message?` | `string` | #### Inherited from Error.constructor • **new IDBNotFoundError**(`message?`, `options?`) #### Parameters | Name | Type | | --- | --- | | `message?` | `string` | | `options?` | `ErrorOptions` | #### Inherited from Error.constructor ## Properties ### cause • `Optional` **cause**: `unknown` #### Inherited from Error.cause * * * ### message • **message**: `string` #### Inherited from Error.message * * * ### name • **name**: `string` = `'IDBNotFoundError'` #### Overrides Error.name * * * ### stack • `Optional` **stack**: `string` #### Inherited from Error.stack --- ## Page: https://doc.replicache.dev/api/interfaces/AsyncIterableIteratorToArray An interface that adds a toArray method to `AsyncIterableIterator`. Usage: const keys: string[] = await rep.scan().keys().toArray(); ## Type parameters | Name | | --- | | `V` | ## Hierarchy * `AsyncIterableIterator`<`V`\> ↳ **`AsyncIterableIteratorToArray`** ## Methods ### \[asyncIterator\] ▸ **\[asyncIterator\]**(): `AsyncIterableIterator`<`V`\> #### Returns `AsyncIterableIterator`<`V`\> #### Inherited from AsyncIterableIterator.\[asyncIterator\] * * * ### next ▸ **next**(`...args`): `Promise`<`IteratorResult`<`V`, `any`\>\> #### Parameters | Name | Type | | --- | --- | | `...args` | \[\] | \[`undefined`\] | #### Returns `Promise`<`IteratorResult`<`V`, `any`\>\> #### Inherited from AsyncIterableIterator.next * * * ### return ▸ `Optional` **return**(`value?`): `Promise`<`IteratorResult`<`V`, `any`\>\> #### Parameters | Name | Type | | --- | --- | | `value?` | `any` | #### Returns `Promise`<`IteratorResult`<`V`, `any`\>\> #### Inherited from AsyncIterableIterator.return * * * ### throw ▸ `Optional` **throw**(`e?`): `Promise`<`IteratorResult`<`V`, `any`\>\> #### Parameters | Name | Type | | --- | --- | | `e?` | `any` | #### Returns `Promise`<`IteratorResult`<`V`, `any`\>\> #### Inherited from AsyncIterableIterator.throw * * * ### toArray ▸ **toArray**(): `Promise`<`V`\[\]\> #### Returns `Promise`<`V`\[\]\> --- ## Page: https://doc.replicache.dev/api/classes/PullError * * Reference * JavaScript Reference * Classes * PullError This error is thrown when the puller fails for any reason. ## Hierarchy * `Error` ↳ **`PullError`** ## Constructors ### constructor • **new PullError**(`causedBy?`) #### Parameters | Name | Type | | --- | --- | | `causedBy?` | `Error` | #### Overrides Error.constructor ## Properties ### cause • `Optional` **cause**: `unknown` #### Inherited from Error.cause * * * ### causedBy • `Optional` **causedBy**: `Error` * * * ### message • **message**: `string` #### Inherited from Error.message * * * ### name • **name**: `string` = `'PullError'` #### Overrides Error.name * * * ### stack • `Optional` **stack**: `string` #### Inherited from Error.stack Previous IDBNotFoundError Next PushError --- ## Page: https://doc.replicache.dev/api/classes/PushError * * Reference * JavaScript Reference * Classes * PushError This error is thrown when the pusher fails for any reason. ## Hierarchy * `Error` ↳ **`PushError`** ## Constructors ### constructor • **new PushError**(`causedBy?`) #### Parameters | Name | Type | | --- | --- | | `causedBy?` | `Error` | #### Overrides Error.constructor ## Properties ### cause • `Optional` **cause**: `unknown` #### Inherited from Error.cause * * * ### causedBy • `Optional` **causedBy**: `Error` * * * ### message • **message**: `string` #### Inherited from Error.message * * * ### name • **name**: `string` = `'PushError'` #### Overrides Error.name * * * ### stack • `Optional` **stack**: `string` #### Inherited from Error.stack Previous PullError Next Replicache --- ## Page: https://doc.replicache.dev/api/classes/Replicache ## Type parameters | Name | Type | | --- | --- | | `MD` | extends `MutatorDefs` = {} | ## Constructors ### constructor • **new Replicache**<`MD`\>(`options`) #### Type parameters | Name | Type | | --- | --- | | `MD` | extends `MutatorDefs` = {} | #### Parameters | Name | Type | | --- | --- | | `options` | `ReplicacheOptions`<`MD`\> | ## Accessors ### auth • `get` **auth**(): `string` The authorization token used when doing a push request. #### Returns `string` • `set` **auth**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `string` | #### Returns `void` * * * ### clientGroupID • `get` **clientGroupID**(): `Promise`<`string`\> The client group ID for this instance of Replicache. Instances of Replicache will have the same client group ID if and only if they have the same name, mutators, indexes, schema version, format version, and browser profile. #### Returns `Promise`<`string`\> * * * ### clientID • `get` **clientID**(): `string` The client ID for this instance of Replicache. Each instance of Replicache gets a unique client ID. #### Returns `string` * * * ### closed • `get` **closed**(): `boolean` Whether the Replicache database has been closed. Once Replicache has been closed it no longer syncs and you can no longer read or write data out of it. After it has been closed it is pretty much useless and should not be used any more. #### Returns `boolean` * * * ### getAuth • `get` **getAuth**(): `undefined` | `null` | () => `MaybePromise`<`undefined` | `null` | `string`\> This gets called when we get an HTTP unauthorized (401) response from the push or pull endpoint. Set this to a function that will ask your user to reauthenticate. #### Returns `undefined` | `null` | () => `MaybePromise`<`undefined` | `null` | `string`\> • `set` **getAuth**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `undefined` | `null` | () => `MaybePromise`<`undefined` | `null` | `string`\> | #### Returns `void` * * * ### idbName • `get` **idbName**(): `string` This is the name Replicache uses for the IndexedDB database where data is stored. #### Returns `string` * * * ### mutate • `get` **mutate**(): `MakeMutators`<`MD`\> The mutators that was registered in the constructor. #### Returns `MakeMutators`<`MD`\> * * * ### name • `get` **name**(): `string` The name of the Replicache database. Populated by name. #### Returns `string` * * * ### onClientStateNotFound • `get` **onClientStateNotFound**(): `null` | () => `void` `onClientStateNotFound` is called when the persistent client has been garbage collected. This can happen if the client has no pending mutations and has not been used for a while. The default behavior is to reload the page (using `location.reload()`). Set this to `null` or provide your own function to prevent the page from reloading automatically. #### Returns `null` | () => `void` • `set` **onClientStateNotFound**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `null` | () => `void` | #### Returns `void` * * * ### onOnlineChange • `get` **onOnlineChange**(): `null` | (`online`: `boolean`) => `void` `onOnlineChange` is called when the online property changes. See online for more details. #### Returns `null` | (`online`: `boolean`) => `void` • `set` **onOnlineChange**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `null` | (`online`: `boolean`) => `void` | #### Returns `void` * * * ### onSync • `get` **onSync**(): `null` | (`syncing`: `boolean`) => `void` `onSync(true)` is called when Replicache transitions from no push or pull happening to at least one happening. `onSync(false)` is called in the opposite case: when Replicache transitions from at least one push or pull happening to none happening. This can be used in a React like app by doing something like the following: const [syncing, setSyncing] = useState(false);useEffect(() => { rep.onSync = setSyncing;}, [rep]); #### Returns `null` | (`syncing`: `boolean`) => `void` • `set` **onSync**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `null` | (`syncing`: `boolean`) => `void` | #### Returns `void` * * * ### onUpdateNeeded • `get` **onUpdateNeeded**(): `null` | (`reason`: `UpdateNeededReason`) => `void` `onUpdateNeeded` is called when a code update is needed. A code update can be needed because: * the server no longer supports the pushVersion, pullVersion or schemaVersion of the current code. * a new Replicache client has created a new client group, because its code has different mutators, indexes, schema version and/or format version from this Replicache client. This is likely due to the new client having newer code. A code update is needed to be able to locally sync with this new Replicache client (i.e. to sync while offline, the clients can can still sync with each other via the server). The default behavior is to reload the page (using `location.reload()`). Set this to `null` or provide your own function to prevent the page from reloading automatically. You may want to provide your own function to display a toast to inform the end user there is a new version of your app available and prompting them to refresh. #### Returns `null` | (`reason`: `UpdateNeededReason`) => `void` • `set` **onUpdateNeeded**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `null` | (`reason`: `UpdateNeededReason`) => `void` | #### Returns `void` * * * ### online • `get` **online**(): `boolean` A rough heuristic for whether the client is currently online. Note that there is no way to know for certain whether a client is online - the next request can always fail. This property returns true if the last sync attempt succeeded, and false otherwise. #### Returns `boolean` * * * ### profileID • `get` **profileID**(): `Promise`<`string`\> The browser profile ID for this browser profile. Every instance of Replicache browser-profile-wide shares the same profile ID. #### Returns `Promise`<`string`\> * * * ### pullInterval • `get` **pullInterval**(): `null` | `number` The duration between each periodic pull. Setting this to `null` disables periodic pull completely. Pull will still happen if you call pull manually. #### Returns `null` | `number` • `set` **pullInterval**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `null` | `number` | #### Returns `void` * * * ### pullURL • `get` **pullURL**(): `string` The URL to use when doing a pull request. #### Returns `string` • `set` **pullURL**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `string` | #### Returns `void` * * * ### puller • `get` **puller**(): `Puller` The function to use to pull data from the server. #### Returns `Puller` • `set` **puller**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `Puller` | #### Returns `void` * * * ### pushDelay • `get` **pushDelay**(): `number` The delay between when a change is made to Replicache and when Replicache attempts to push that change. #### Returns `number` • `set` **pushDelay**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `number` | #### Returns `void` * * * ### pushURL • `get` **pushURL**(): `string` The URL to use when doing a push request. #### Returns `string` • `set` **pushURL**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `string` | #### Returns `void` * * * ### pusher • `get` **pusher**(): `Pusher` The function to use to push data to the server. #### Returns `Pusher` • `set` **pusher**(`value`): `void` #### Parameters | Name | Type | | --- | --- | | `value` | `Pusher` | #### Returns `void` * * * ### requestOptions • `get` **requestOptions**(): `Required`<`RequestOptions`\> The options used to control the pull and push request behavior. This object is live so changes to it will affect the next pull or push call. #### Returns `Required`<`RequestOptions`\> * * * ### schemaVersion • `get` **schemaVersion**(): `string` The schema version of the data understood by this application. #### Returns `string` ## Methods ### close ▸ **close**(): `Promise`<`void`\> Closes this Replicache instance. When closed all subscriptions end and no more read or writes are allowed. #### Returns `Promise`<`void`\> * * * ### experimentalPendingMutations ▸ **experimentalPendingMutations**(): `Promise`<readonly `PendingMutation`\[\]\> List of pending mutations. The order of this is from oldest to newest. Gives a list of local mutations that have `mutationID` > `syncHead.mutationID` that exists on the main client group. This method is experimental and may change in the future. #### Returns `Promise`<readonly `PendingMutation`\[\]\> * * * ### experimentalWatch ▸ **experimentalWatch**(`callback`): () => `void` Watches Replicache for changes. The `callback` gets called whenever the underlying data changes and the `key` changes matches the `prefix` of ExperimentalWatchIndexOptions or ExperimentalWatchNoIndexOptions if present. If a change occurs to the data but the change does not impact the key space the callback is not called. In other words, the callback is never called with an empty diff. This gets called after commit (a mutation or a rebase). This method is under development and its semantics will change. #### Parameters | Name | Type | | --- | --- | | `callback` | `ExperimentalWatchNoIndexCallback` | #### Returns `fn` ▸ (): `void` Watches Replicache for changes. The `callback` gets called whenever the underlying data changes and the `key` changes matches the `prefix` of ExperimentalWatchIndexOptions or ExperimentalWatchNoIndexOptions if present. If a change occurs to the data but the change does not impact the key space the callback is not called. In other words, the callback is never called with an empty diff. This gets called after commit (a mutation or a rebase). This method is under development and its semantics will change. ##### Returns `void` ▸ **experimentalWatch**<`Options`\>(`callback`, `options?`): () => `void` #### Type parameters | Name | Type | | --- | --- | | `Options` | extends `ExperimentalWatchOptions` | #### Parameters | Name | Type | | --- | --- | | `callback` | `ExperimentalWatchCallbackForOptions`<`Options`\> | | `options?` | `Options` | #### Returns `fn` ▸ (): `void` ##### Returns `void` * * * ### poke ▸ **poke**(`poke`): `Promise`<`void`\> Applies an update from the server to Replicache. Throws an error if cookie does not match. In that case the server thinks this client has a different cookie than it does; the caller should disconnect from the server and re-register, which transmits the cookie the client actually has. This method is under development and its semantics will change. #### Parameters | Name | Type | | --- | --- | | `poke` | `Poke` | #### Returns `Promise`<`void`\> * * * ### pull ▸ **pull**(`now?`): `Promise`<`void`\> Pull pulls changes from the pullURL. If there are any changes local changes will get replayed on top of the new server state. If the server endpoint fails pull will be continuously retried with an exponential backoff. #### Parameters | Name | Type | Description | | --- | --- | --- | | `now?` | `Object` | If true, pull will happen immediately and ignore minDelayMs as well as the exponential backoff in case of errors. | | `now.now` | `undefined` | `boolean` | \- | #### Returns `Promise`<`void`\> A promise that resolves when the next pull completes. In case of errors the first error will reject the returned promise. Subsequent errors will not be reflected in the promise. * * * ### push ▸ **push**(`now?`): `Promise`<`void`\> Push pushes pending changes to the pushURLXXX. You do not usually need to manually call push. If pushDelay is non-zero (which it is by default) pushes happen automatically shortly after mutations. If the server endpoint fails push will be continuously retried with an exponential backoff. #### Parameters | Name | Type | Description | | --- | --- | --- | | `now?` | `Object` | If true, push will happen immediately and ignore pushDelay, minDelayMs as well as the exponential backoff in case of errors. | | `now.now` | `undefined` | `boolean` | \- | #### Returns `Promise`<`void`\> A promise that resolves when the next push completes. In case of errors the first error will reject the returned promise. Subsequent errors will not be reflected in the promise. * * * ### query ▸ **query**<`R`\>(`body`): `Promise`<`R`\> Query is used for read transactions. It is recommended to use transactions to ensure you get a consistent view across multiple calls to `get`, `has` and `scan`. #### Type parameters | Name | | --- | | `R` | #### Parameters | Name | Type | | --- | --- | | `body` | (`tx`: `ReadTransaction`) => `R` | `Promise`<`R`\> | #### Returns `Promise`<`R`\> * * * ### subscribe ▸ **subscribe**<`R`\>(`body`, `options`): () => `void` Subscribe to the result of a query. The `body` function is evaluated once and its results are returned via `onData`. Thereafter, each time the the result of `body` changes, `onData` is fired again with the new result. `subscribe()` goes to significant effort to avoid extraneous work re-evaluating subscriptions: 1. subscribe tracks the keys that `body` accesses each time it runs. `body` is only re-evaluated when those keys change. 2. subscribe only re-fires `onData` in the case that a result changes by way of the `isEqual` option which defaults to doing a deep JSON value equality check. Because of (1), `body` must be a pure function of the data in Replicache. `body` must not access anything other than the `tx` parameter passed to it. Although subscribe is as efficient as it can be, it is somewhat constrained by the goal of returning an arbitrary computation of the cache. For even better performance (but worse dx), see experimentalWatch. If an error occurs in the `body` the `onError` function is called if present. Otherwise, the error is logged at log level 'error'. To cancel the subscription, call the returned function. #### Type parameters | Name | | --- | | `R` | #### Parameters | Name | Type | Description | | --- | --- | --- | | `body` | (`tx`: `ReadTransaction`) => `Promise`<`R`\> | The function to evaluate to get the value to pass into `onData`. | | `options` | `SubscribeOptions`<`R`\> | (`result`: `R`) => `void` | Options is either a function or an object. If it is a function it is equivalent to passing it as the `onData` property of an object. | #### Returns `fn` ▸ (): `void` Subscribe to the result of a query. The `body` function is evaluated once and its results are returned via `onData`. Thereafter, each time the the result of `body` changes, `onData` is fired again with the new result. `subscribe()` goes to significant effort to avoid extraneous work re-evaluating subscriptions: 1. subscribe tracks the keys that `body` accesses each time it runs. `body` is only re-evaluated when those keys change. 2. subscribe only re-fires `onData` in the case that a result changes by way of the `isEqual` option which defaults to doing a deep JSON value equality check. Because of (1), `body` must be a pure function of the data in Replicache. `body` must not access anything other than the `tx` parameter passed to it. Although subscribe is as efficient as it can be, it is somewhat constrained by the goal of returning an arbitrary computation of the cache. For even better performance (but worse dx), see experimentalWatch. If an error occurs in the `body` the `onError` function is called if present. Otherwise, the error is logged at log level 'error'. To cancel the subscription, call the returned function. ##### Returns `void` --- ## Page: https://doc.replicache.dev/api/classes/TransactionClosedError This error is thrown when you try to call methods on a closed transaction. ## Hierarchy * `Error` ↳ **`TransactionClosedError`** ## Constructors ### constructor • **new TransactionClosedError**() #### Overrides Error.constructor ## Properties ### cause • `Optional` **cause**: `unknown` #### Inherited from Error.cause * * * ### message • **message**: `string` #### Inherited from Error.message * * * ### name • **name**: `string` #### Inherited from Error.name * * * ### stack • `Optional` **stack**: `string` #### Inherited from Error.stack --- ## Page: https://doc.replicache.dev/api/interfaces/KVRead This interface is experimental and might be removed or changed in the future without following semver versioning. Please be cautious. ## Hierarchy * `Release` ↳ **`KVRead`** ↳↳ `KVWrite` ## Properties ### closed • **closed**: `boolean` ## Methods ### get ▸ **get**(`key`): `Promise`<`undefined` | `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `ReadonlyJSONValue`\> * * * ### has ▸ **has**(`key`): `Promise`<`boolean`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`boolean`\> * * * ### release ▸ **release**(): `void` #### Returns `void` #### Inherited from Release.release --- ## Page: https://doc.replicache.dev/api/interfaces/KVStore Store defines a transactional key/value store that Replicache stores all data within. For correct operation of Replicache, implementations of this interface must provide strict serializable transactions. Informally, read and write transactions must behave like a ReadWrite Lock - multiple read transactions are allowed in parallel, or one write. Additionally writes from a transaction must appear all at one, atomically. ## Properties ### closed • **closed**: `boolean` ## Methods ### close ▸ **close**(): `Promise`<`void`\> #### Returns `Promise`<`void`\> * * * ### read ▸ **read**(): `Promise`<`KVRead`\> #### Returns `Promise`<`KVRead`\> * * * ### write ▸ **write**(): `Promise`<`KVWrite`\> #### Returns `Promise`<`KVWrite`\> --- ## Page: https://doc.replicache.dev/api/interfaces/KVWrite This interface is experimental and might be removed or changed in the future without following semver versioning. Please be cautious. ## Hierarchy * `KVRead` ↳ **`KVWrite`** ## Properties ### closed • **closed**: `boolean` #### Inherited from KVRead.closed ## Methods ### commit ▸ **commit**(): `Promise`<`void`\> #### Returns `Promise`<`void`\> * * * ### del ▸ **del**(`key`): `Promise`<`void`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`void`\> * * * ### get ▸ **get**(`key`): `Promise`<`undefined` | `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `ReadonlyJSONValue`\> #### Inherited from KVRead.get * * * ### has ▸ **has**(`key`): `Promise`<`boolean`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`boolean`\> #### Inherited from KVRead.has * * * ### put ▸ **put**(`key`, `value`): `Promise`<`void`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | | `value` | `ReadonlyJSONValue` | #### Returns `Promise`<`void`\> * * * ### release ▸ **release**(): `void` #### Returns `void` #### Inherited from KVRead.release --- ## Page: https://doc.replicache.dev/api/interfaces/LogSink ## Methods ### flush ▸ `Optional` **flush**(): `Promise`<`void`\> #### Returns `Promise`<`void`\> * * * ### log ▸ **log**(`level`, `context`, `...args`): `void` #### Parameters | Name | Type | | --- | --- | | `level` | `LogLevel` | | `context` | `undefined` | `Context` | | `...args` | `unknown`\[\] | #### Returns `void` --- ## Page: https://doc.replicache.dev/api/interfaces/ReadTransaction ReadTransactions are used with query and subscribe and allows read operations on the database. ## Hierarchy * **`ReadTransaction`** ↳ `WriteTransaction` ## Properties ### clientID • `Readonly` **clientID**: `string` * * * ### environment • `Readonly` **environment**: `TransactionEnvironment` **`Deprecated`** Use location instead. * * * ### location • `Readonly` **location**: `TransactionEnvironment` ## Methods ### get ▸ **get**(`key`): `Promise`<`undefined` | `ReadonlyJSONValue`\> Get a single value from the database. If the `key` is not present this returns `undefined`. Important: The returned JSON is readonly and should not be modified. This is only enforced statically by TypeScript and there are no runtime checks for performance reasons. If you mutate the return value you will get undefined behavior. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `ReadonlyJSONValue`\> ▸ **get**<`T`\>(`key`): `Promise`<`undefined` | `DeepReadonly`<`T`\>\> #### Type parameters | Name | Type | | --- | --- | | `T` | extends `JSONValue` | #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `DeepReadonly`<`T`\>\> * * * ### has ▸ **has**(`key`): `Promise`<`boolean`\> Determines if a single `key` is present in the database. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`boolean`\> * * * ### isEmpty ▸ **isEmpty**(): `Promise`<`boolean`\> Whether the database is empty. #### Returns `Promise`<`boolean`\> * * * ### scan ▸ **scan**(`options`): `ScanResult`<`IndexKey`, `ReadonlyJSONValue`\> Gets many values from the database. This returns a ScanResult which implements `AsyncIterable`. It also has methods to iterate over the keys and entries. If `options` has an `indexName`, then this does a scan over an index with that name. A scan over an index uses a tuple for the key consisting of `[secondary: string, primary: string]`. If the ScanResult is used after the `ReadTransaction` has been closed it will throw a TransactionClosedError. Important: The returned JSON is readonly and should not be modified. This is only enforced statically by TypeScript and there are no runtime checks for performance reasons. If you mutate the return value you will get undefined behavior. #### Parameters | Name | Type | | --- | --- | | `options` | `ScanIndexOptions` | #### Returns `ScanResult`<`IndexKey`, `ReadonlyJSONValue`\> ▸ **scan**(`options?`): `ScanResult`<`string`, `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanNoIndexOptions` | #### Returns `ScanResult`<`string`, `ReadonlyJSONValue`\> ▸ **scan**(`options?`): `ScanResult`<`string` | `IndexKey`, `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanOptions` | #### Returns `ScanResult`<`string` | `IndexKey`, `ReadonlyJSONValue`\> ▸ **scan**<`V`\>(`options`): `ScanResult`<`IndexKey`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options` | `ScanIndexOptions` | #### Returns `ScanResult`<`IndexKey`, `DeepReadonly`<`V`\>\> ▸ **scan**<`V`\>(`options?`): `ScanResult`<`string`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanNoIndexOptions` | #### Returns `ScanResult`<`string`, `DeepReadonly`<`V`\>\> ▸ **scan**<`V`\>(`options?`): `ScanResult`<`string` | `IndexKey`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanOptions` | #### Returns `ScanResult`<`string` | `IndexKey`, `DeepReadonly`<`V`\>\> --- ## Page: https://doc.replicache.dev/api/interfaces/ReplicacheOptions The options passed to Replicache. ## Type parameters | Name | Type | | --- | --- | | `MD` | extends `MutatorDefs` | ## Properties ### auth • `Optional` **auth**: `string` This is the authorization token used when doing a pull and push. * * * ### indexes • `Optional` `Readonly` **indexes**: `IndexDefinitions` Defines the indexes, if any, to use on the data. * * * ### kvStore • `Optional` **kvStore**: `KVStoreProvider` | `"mem"` | `"idb"` Allows providing a custom implementation of the underlying storage layer. * * * ### licenseKey • **licenseKey**: `string` The license key for Replicache. This parameter is required for Replicache to function. See https://replicache.dev for how to acquire a license key. YOU SHOULD PASS TEST\_LICENSE\_KEY IN AUTOMATED TESTS. It disables license checks for several minutes. If you pass a normal license key in tests, each test that instantiates Replicache will attempt to perform a license check against Replicache's licensing server, potentially increasing your monthly active browser profile count, slowing the test down, and spamming Replicache's servers. * * * ### logLevel • `Optional` **logLevel**: `LogLevel` Determines how much logging to do. When this is set to `'debug'`, Replicache will also log `'info'` and `'error'` messages. When set to `'info'` we log `'info'` and `'error'` but not `'debug'`. When set to `'error'` we only log `'error'` messages. Default is `'info'`. * * * ### logSinks • `Optional` **logSinks**: `LogSink`\[\] Enables custom handling of logs. By default logs are logged to the console. If you would like logs to be sent elsewhere (e.g. to a cloud logging service like DataDog) you can provide an array of LogSinks. Logs at or above logLevel are sent to each of these LogSinks. If you would still like logs to go to the console, include `consoleLogSink` in the array. logSinks: [consoleLogSink, myCloudLogSink], * * * ### mutators • `Optional` **mutators**: `MD` An object used as a map to define the _mutators_. These gets registered at startup of Replicache. _Mutators_ are used to make changes to the data. #### Example The registered _mutations_ are reflected on the mutate property of the Replicache instance. const rep = new Replicache({ name: 'user-id', mutators: { async createTodo(tx: WriteTransaction, args: JSONValue) { const key = `/todo/${args.id}`; if (await tx.has(key)) { throw new Error('Todo already exists'); } await tx.set(key, args); }, async deleteTodo(tx: WriteTransaction, id: number) { ... }, },}); This will create the function to later use: await rep.mutate.createTodo({ id: 1234, title: 'Make things work offline', complete: true,}); #### Replays _Mutators_ run once when they are initially invoked, but they might also be _replayed_ multiple times during sync. As such _mutators_ should not modify application state directly. Also, it is important that the set of registered mutator names only grows over time. If Replicache syncs and needed _mutator_ is not registered, it will substitute a no-op mutator, but this might be a poor user experience. #### Server application During push, a description of each mutation is sent to the server's push endpoint where it is applied. Once the _mutation_ has been applied successfully, as indicated by the client view's `lastMutationId` field, the local version of the _mutation_ is removed. See the design doc for additional details on the sync protocol. #### Transactionality _Mutators_ are atomic: all their changes are applied together, or none are. Throwing an exception aborts the transaction. Otherwise, it is committed. As with query and subscribe all reads will see a consistent view of the cache while they run. * * * ### name • **name**: `string` The name of the Replicache database. It is important to use user specific names so that if there are multiple tabs open for different distinct users their data is kept separate. For efficiency and performance, a new Replicache instance will initialize its state from the persisted state of an existing Replicache instance with the same `name`, domain and browser profile. Mutations from one Replicache instance may be pushed using the auth, pushURL, pullURL, pusher, and puller of another Replicache instance with the same `name`, domain and browser profile. You can use multiple Replicache instances for the same user as long as the names are unique. e.g. `name:` $userID:$roomID\` * * * ### pullInterval • `Optional` **pullInterval**: `null` | `number` The duration between each pull in milliseconds. Set this to `null` to prevent pulling in the background. Defaults to 60 seconds. * * * ### pullURL • `Optional` **pullURL**: `string` This is the URL to the server endpoint dealing with pull. See Pull Endpoint Reference for more details. If not provided, pull requests will not be made unless a custom puller is provided. * * * ### puller • `Optional` **puller**: `Puller` Allows passing in a custom implementation of a Puller function. This function is called when doing a pull and it is responsible for communicating with the server. Normally, this is just a POST to a URL with a JSON body but you can provide your own function if you need to do things differently. * * * ### pushDelay • `Optional` **pushDelay**: `number` The delay between when a change is made to Replicache and when Replicache attempts to push that change. * * * ### pushURL • `Optional` **pushURL**: `string` This is the URL to the server endpoint dealing with the push updates. See Push Endpoint Reference for more details. If not provided, push requests will not be made unless a custom pusher is provided. * * * ### pusher • `Optional` **pusher**: `Pusher` Allows passing in a custom implementation of a Pusher function. This function is called when doing a push and it is responsible for communicating with the server. Normally, this is just a POST to a URL with a JSON body but you can provide your own function if you need to do things differently. * * * ### requestOptions • `Optional` **requestOptions**: `RequestOptions` Options to use when doing pull and push requests. * * * ### schemaVersion • `Optional` **schemaVersion**: `string` The schema version of the data understood by this application. This enables versioning of mutators (in the push direction) and the client view (in the pull direction). --- ## Page: https://doc.replicache.dev/api/interfaces/RequestOptions * * Reference * JavaScript Reference * Interfaces * RequestOptions ## Properties ### maxDelayMs • `Optional` **maxDelayMs**: `number` When there are pending pull or push requests this is the _maximum_ amount of time to wait until we try another pull/push. * * * ### minDelayMs • `Optional` **minDelayMs**: `number` When there are pending pull or push requests this is the _minimum_ amount of time to wait until we try another pull/push. Previous ReplicacheOptions Next ScanResult --- ## Page: https://doc.replicache.dev/api/interfaces/ScanResult ## Type parameters | Name | Type | | --- | --- | | `K` | extends `ScanKey` | | `V` | `V` | ## Hierarchy * `AsyncIterable`<`V`\> ↳ **`ScanResult`** ## Methods ### \[asyncIterator\] ▸ **\[asyncIterator\]**(): `AsyncIterableIteratorToArray`<`V`\> The default AsyncIterable. This is the same as values. #### Returns `AsyncIterableIteratorToArray`<`V`\> #### Overrides AsyncIterable.\[asyncIterator\] * * * ### entries ▸ **entries**(): `AsyncIterableIteratorToArray`<readonly \[`K`, `V`\]\> Async iterator over the entries of the scan call. An entry is a tuple of key values. If the scan is over an index the key is a tuple of `[secondaryKey: string, primaryKey]` #### Returns `AsyncIterableIteratorToArray`<readonly \[`K`, `V`\]\> * * * ### keys ▸ **keys**(): `AsyncIterableIteratorToArray`<`K`\> Async iterator over the keys of the scan call. If the scan is over an index the key is a tuple of `[secondaryKey: string, primaryKey]` #### Returns `AsyncIterableIteratorToArray`<`K`\> * * * ### toArray ▸ **toArray**(): `Promise`<`V`\[\]\> Returns all the values as an array. Same as `values().toArray()` #### Returns `Promise`<`V`\[\]\> * * * ### values ▸ **values**(): `AsyncIterableIteratorToArray`<`V`\> Async iterator over the values of the scan call. #### Returns `AsyncIterableIteratorToArray`<`V`\> --- ## Page: https://doc.replicache.dev/api/interfaces/SubscribeOptions The options passed to subscribe. ## Type parameters | Name | | --- | | `R` | ## Properties ### isEqual • `Optional` **isEqual**: (`a`: `R`, `b`: `R`) => `boolean` #### Type declaration ▸ (`a`, `b`): `boolean` If present this function is used to determine if the value returned by the body function has changed. If not provided a JSON deep equality check is used. ##### Parameters | Name | Type | | --- | --- | | `a` | `R` | | `b` | `R` | ##### Returns `boolean` * * * ### onData • **onData**: (`result`: `R`) => `void` #### Type declaration ▸ (`result`): `void` Called when the return value of the body function changes. ##### Parameters | Name | Type | | --- | --- | | `result` | `R` | ##### Returns `void` * * * ### onDone • `Optional` **onDone**: () => `void` #### Type declaration ▸ (): `void` If present, called when the subscription is removed/done. ##### Returns `void` * * * ### onError • `Optional` **onError**: (`error`: `unknown`) => `void` #### Type declaration ▸ (`error`): `void` If present, called when an error occurs. ##### Parameters | Name | Type | | --- | --- | | `error` | `unknown` | ##### Returns `void` --- ## Page: https://doc.replicache.dev/api/interfaces/WriteTransaction WriteTransactions are used with _mutators_ which are registered using mutators and allows read and write operations on the database. ## Hierarchy * `ReadTransaction` ↳ **`WriteTransaction`** ## Properties ### clientID • `Readonly` **clientID**: `string` #### Inherited from ReadTransaction.clientID * * * ### environment • `Readonly` **environment**: `TransactionEnvironment` **`Deprecated`** Use location instead. #### Inherited from ReadTransaction.environment * * * ### location • `Readonly` **location**: `TransactionEnvironment` #### Inherited from ReadTransaction.location * * * ### mutationID • `Readonly` **mutationID**: `number` The ID of the mutation that is being applied. * * * ### reason • `Readonly` **reason**: `TransactionReason` The reason for the transaction. This can be `initial`, `rebase` or `authoriative`. ## Methods ### del ▸ **del**(`key`): `Promise`<`boolean`\> Removes a `key` and its value from the database. Returns `true` if there was a `key` to remove. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`boolean`\> * * * ### get ▸ **get**(`key`): `Promise`<`undefined` | `ReadonlyJSONValue`\> Get a single value from the database. If the `key` is not present this returns `undefined`. Important: The returned JSON is readonly and should not be modified. This is only enforced statically by TypeScript and there are no runtime checks for performance reasons. If you mutate the return value you will get undefined behavior. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `ReadonlyJSONValue`\> #### Inherited from ReadTransaction.get ▸ **get**<`T`\>(`key`): `Promise`<`undefined` | `DeepReadonly`<`T`\>\> #### Type parameters | Name | Type | | --- | --- | | `T` | extends `JSONValue` | #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`undefined` | `DeepReadonly`<`T`\>\> #### Inherited from ReadTransaction.get * * * ### has ▸ **has**(`key`): `Promise`<`boolean`\> Determines if a single `key` is present in the database. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | #### Returns `Promise`<`boolean`\> #### Inherited from ReadTransaction.has * * * ### isEmpty ▸ **isEmpty**(): `Promise`<`boolean`\> Whether the database is empty. #### Returns `Promise`<`boolean`\> #### Inherited from ReadTransaction.isEmpty * * * ### put ▸ **put**(`key`, `value`): `Promise`<`void`\> #### Parameters | Name | Type | | --- | --- | | `key` | `string` | | `value` | `ReadonlyJSONValue` | #### Returns `Promise`<`void`\> **`Deprecated`** Use set instead. * * * ### scan ▸ **scan**(`options`): `ScanResult`<`IndexKey`, `ReadonlyJSONValue`\> Gets many values from the database. This returns a ScanResult which implements `AsyncIterable`. It also has methods to iterate over the keys and entries. If `options` has an `indexName`, then this does a scan over an index with that name. A scan over an index uses a tuple for the key consisting of `[secondary: string, primary: string]`. If the ScanResult is used after the `ReadTransaction` has been closed it will throw a TransactionClosedError. Important: The returned JSON is readonly and should not be modified. This is only enforced statically by TypeScript and there are no runtime checks for performance reasons. If you mutate the return value you will get undefined behavior. #### Parameters | Name | Type | | --- | --- | | `options` | `ScanIndexOptions` | #### Returns `ScanResult`<`IndexKey`, `ReadonlyJSONValue`\> #### Inherited from ReadTransaction.scan ▸ **scan**(`options?`): `ScanResult`<`string`, `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanNoIndexOptions` | #### Returns `ScanResult`<`string`, `ReadonlyJSONValue`\> #### Inherited from ReadTransaction.scan ▸ **scan**(`options?`): `ScanResult`<`string` | `IndexKey`, `ReadonlyJSONValue`\> #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanOptions` | #### Returns `ScanResult`<`string` | `IndexKey`, `ReadonlyJSONValue`\> #### Inherited from ReadTransaction.scan ▸ **scan**<`V`\>(`options`): `ScanResult`<`IndexKey`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options` | `ScanIndexOptions` | #### Returns `ScanResult`<`IndexKey`, `DeepReadonly`<`V`\>\> #### Inherited from ReadTransaction.scan ▸ **scan**<`V`\>(`options?`): `ScanResult`<`string`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanNoIndexOptions` | #### Returns `ScanResult`<`string`, `DeepReadonly`<`V`\>\> #### Inherited from ReadTransaction.scan ▸ **scan**<`V`\>(`options?`): `ScanResult`<`string` | `IndexKey`, `DeepReadonly`<`V`\>\> #### Type parameters | Name | Type | | --- | --- | | `V` | extends `ReadonlyJSONValue` | #### Parameters | Name | Type | | --- | --- | | `options?` | `ScanOptions` | #### Returns `ScanResult`<`string` | `IndexKey`, `DeepReadonly`<`V`\>\> #### Inherited from ReadTransaction.scan * * * ### set ▸ **set**(`key`, `value`): `Promise`<`void`\> Sets a single `value` in the database. The value will be frozen (using `Object.freeze`) in debug mode. #### Parameters | Name | Type | | --- | --- | | `key` | `string` | | `value` | `ReadonlyJSONValue` | #### Returns `Promise`<`void`\> --- ## Page: https://doc.replicache.dev/howto/launch Before you launch with Replicache in your product, it's a good idea to double-check that you have correctly covered all the small details of integration. This list can help you determine if you might have missed a detail, or deferred and then forgotten about one. ## JS SDK * Ensure that you are passing in your own Replicache license key * If you wish to change the signature of a mutator (eg, the number or type of its arguments) you must choose a new name; Replicache does not handle mutator versioning. * At some point you will almost certainly wish to change the schema of mutations included in the `PushRequest` and the client view returned in the `PullResponse`. The `ReplicacheOptions.schemaVersion` exists to facilitate this; it can be set by your app and is passed in both the `PushRequest` and `PullRequest`. Consider setting the `schemaVersion` from the start so that you don't later have to special case the "no schemaVersion" case. * If a user's auth token can expire during a session, causing your endpoints to return a 401, be sure that re-auth is handled for **Push** and **Pull** via `getAuth`. * Ensure your use of `clientID` is correct. A `clientID` represents a unique running instance of the `Replicache` class. Typically in applications, each tab _load_ gets a unique `clientID`. Do not use the `clientID` as a stable identifier for a user, machine, or browser profile. **Note:** In multiplayer applications, a common and correct application of the `clientID` is to represent a running session (e.g., a mouse cursor), because in most multiplayer applications the design goal is that two tabs from the same user should show up as two separate cursors to other users. * The `name` property of `ReplicacheOptions` is required to differentiate Replicache instances for different users. This is important for the following reasons: * For efficiency and performance, a new `Replicache` instance will initialize its state from the persisted state of an existing `Replicache` instance with the same `name`, domain and browser profile. * Mutations from one `Replicache` instance may be pushed using the `ReplicacheOptions.auth`, `ReplicacheOptions.pushURL`, `ReplicacheOptions.pullURL`, `ReplicacheOptions.pusher`, and `ReplicacheOptions.puller` of another Replicache instance with the same `name`, domain and browser profile. ## All endpoints * Ensure that you are authenticating the auth tokens configured via `ReplicacheOptions`, which are passed in the **Authentication** HTTP header. * Your endpoints should return HTTP 401 to indicate that the user's authentication token is invalid (e.g., non-existent or expired), and that the app should re-authenticate them. * **Ensure that the `clientID` passed in does in fact belong to the authenticated user.** Client IDs are random and cryptographically strong, but it is best to be safe. Note that the Replicache sample apps do not have a notion of a _user_, so they are missing the prudent step of associating the `clientID` with a user on the server and ensuring that the authenticated user is associated with the `clientID` that is passed in to the `Push` endpoint. If the `clientID` from one user is visible to others then you _must_ do this authentication, else one user could push mutations on behalf of another user. * It is extremely important to ensure that your datastore and/or the way you use it guarantees the consistency and isolation properties required for Replicache to work as designed. These properties are: * the effects of a transaction are revealed atomically * within a transaction, reads are consistent, ie, reading the same item twice always results in the same value, unless changed within the transaction * a transaction sees the effects of all previously committed transactions For example, MySQL's **SERIALIZABLE** isolation level provides these guarantees. If would like some advice on how to set up your particular datastore correctly, or if you have any questions, please contact us. * The keys in Replicache are conceptually strings encoded using UTF-8. The ordering of the keys when doing `scan` is a bytewise compare of UTF-8 encoded strings. If you are implement `ReadTransaction` (or `WriteTransaction`) in your own backend make sure you are treating these strings as UTF-8. We provide and npm package called compare-utf8 which can be used to compare JS strings using UTF-8 bytewise comparison. ## Push endpoint See Push Launch Checklist. ## Pull endpoint See Pull Launch Checklist. --- ## Page: https://doc.replicache.dev/howto/source-access We maintain a private npm package at @rocicorp/replicache with an unminified source build. Each release of Replicache has a corresponding source build with the same version. The source package is available to commercial users of Replicache. Please contact us to get access. Use of the Replicache source code is governed by our terms. --- ## Page: https://doc.replicache.dev/howto/text You can implement collaborative text elements within a Replicache applications by sending Yjs documents over push and pull. This works fairly well. It's easy to send just deltas upstream via Replicache mutations. For downstream, sending just deltas is more difficult. Current users we are aware of just send the whole document which is fine for all but the largest documents. See `replicache-yjs` for a small example of this. Many applications can also get by without a full collaborative editing solution if their text is highly structured (e.g., like Notion). We do plan to offer first-class collaborative text in the future. --- ## Page: https://doc.replicache.dev/howto/unit-test You can unit test your application directly against Replicache, without having to mock out Replicache's interface. To do so, there are a few considerations: * You'll need to run your tests in a web environment like `web-test-runner`, because Replicache has DOM dependencies. * You should use `TEST_LICENSE_KEY` for your license during automated tests to prevent inflated usage. * You'll want to disable sync. You can do this with any of: * Set `pullURL` and `pushURL` to `undefined`. These are read/write so clearing them prevents next push/pull. * Set a large delay: setting a large `pushDelay` will prevent automatically pushing after a mutation. Setting `pullInterval` will increase the time to the next pull. * You could implement a custom `puller`/`pusher`. * You may want to run Replicache in-memory. This can be done by setting the kvStore parameter to `mem`. * Alternately, you can keep using the persistent storage and pick a randomly-generated `name` for your Replicache instance each time you create it. --- ## Page: https://doc.replicache.dev/api#pushrequest ## Classes * IDBNotFoundError * PullError * PushError * Replicache * TransactionClosedError ## Interfaces * AsyncIterableIteratorToArray * KVRead * KVStore * KVWrite * LogSink * ReadTransaction * ReplicacheOptions * RequestOptions * ScanResult * SubscribeOptions * WriteTransaction ## Type Aliases ### ClientGroupID Ƭ **ClientGroupID**: `string` The ID describing a group of clients. All clients in the same group share a persistent storage (IDB). * * * ### ClientID Ƭ **ClientID**: `string` The ID describing a client. * * * ### ClientStateNotFoundResponse Ƭ **ClientStateNotFoundResponse**: `Object` In certain scenarios the server can signal that it does not know about the client. For example, the server might have lost all of its state (this might happen during the development of the server). #### Type declaration | Name | Type | | --- | --- | | `error` | `"ClientStateNotFound"` | * * * ### Cookie Ƭ **Cookie**: `null` | `string` | `number` | `ReadonlyJSONValue` & { `order`: `number` | `string` } A cookie is a value that is used to determine the order of snapshots. It needs to be comparable. This can be a `string`, `number` or if you want to use a more complex value, you can use an object with an `order` property. The value `null` is considered to be less than any other cookie and it is used for the first pull when no cookie has been set. The order is the natural order of numbers and strings. If one of the cookies is an object then the value of the `order` property is treated as the cookie when doing comparison. If one of the cookies is a string and the other is a number, the number is fist converted to a string (using `toString()`). * * * ### CreateIndexDefinition Ƭ **CreateIndexDefinition**: `IndexDefinition` & { `name`: `string` } * * * ### CreateKVStore Ƭ **CreateKVStore**: (`name`: `string`) => `KVStore` #### Type declaration ▸ (`name`): `KVStore` Factory function for creating KVStore instances. The name is used to identify the store. If the same name is used for multiple stores, they should share the same data. It is also desirable to have these stores share an RWLock. ##### Parameters | Name | Type | | --- | --- | | `name` | `string` | ##### Returns `KVStore` * * * ### DeepReadonly Ƭ **DeepReadonly**<`T`\>: `T` extends `null` | `boolean` | `string` | `number` | `undefined` ? `T` : `DeepReadonlyObject`<`T`\> Basic deep readonly type. It works for JSONValue. #### Type parameters | Name | | --- | | `T` | * * * ### DeepReadonlyObject Ƭ **DeepReadonlyObject**<`T`\>: { readonly \[K in keyof T\]: DeepReadonly<T\[K\]\> } #### Type parameters | Name | | --- | | `T` | * * * ### DropDatabaseOptions Ƭ **DropDatabaseOptions**: `Object` Options for `dropDatabase` and `dropAllDatabases`. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `kvStore?` | `"idb"` | `"mem"` | `KVStoreProvider` | Allows providing a custom implementation of the underlying storage layer. Default is `'idb'`. | | `logLevel?` | `LogLevel` | Determines how much logging to do. When this is set to `'debug'`, Replicache will also log `'info'` and `'error'` messages. When set to `'info'` we log `'info'` and `'error'` but not `'debug'`. When set to `'error'` we only log `'error'` messages. Default is `'info'`. | | `logSinks?` | `LogSink`\[\] | Enables custom handling of logs. By default logs are logged to the console. If you would like logs to be sent elsewhere (e.g. to a cloud logging service like DataDog) you can provide an array of LogSinks. Logs at or above logLevel are sent to each of these LogSinks. If you would still like logs to go to the console, include `consoleLogSink` in the array. `ts logSinks: [consoleLogSink, myCloudLogSink],` Default is `[consoleLogSink]`. | * * * ### DropKVStore Ƭ **DropKVStore**: (`name`: `string`) => `Promise`<`void`\> #### Type declaration ▸ (`name`): `Promise`<`void`\> Function for deleting KVStore instances. The name is used to identify the store. If the same name is used for multiple stores, they should share the same data. ##### Parameters | Name | Type | | --- | --- | | `name` | `string` | ##### Returns `Promise`<`void`\> * * * ### ExperimentalDiff Ƭ **ExperimentalDiff**: `ExperimentalIndexDiff` | `ExperimentalNoIndexDiff` Describes the changes that happened to Replicache after a WriteTransaction was committed. This type is experimental and may change in the future. * * * ### ExperimentalDiffOperation Ƭ **ExperimentalDiffOperation**<`Key`\>: `ExperimentalDiffOperationAdd`<`Key`\> | `ExperimentalDiffOperationDel`<`Key`\> | `ExperimentalDiffOperationChange`<`Key`\> The individual parts describing the changes that happened to the Replicache data. There are three different kinds of operations: * `add`: A new entry was added. * `del`: An entry was deleted. * `change`: An entry was changed. This type is experimental and may change in the future. #### Type parameters | Name | | --- | | `Key` | * * * ### ExperimentalDiffOperationAdd Ƭ **ExperimentalDiffOperationAdd**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `newValue` | `Value` | | `op` | `"add"` | * * * ### ExperimentalDiffOperationChange Ƭ **ExperimentalDiffOperationChange**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `newValue` | `Value` | | `oldValue` | `Value` | | `op` | `"change"` | * * * ### ExperimentalDiffOperationDel Ƭ **ExperimentalDiffOperationDel**<`Key`, `Value`\>: `Object` #### Type parameters | Name | Type | | --- | --- | | `Key` | `Key` | | `Value` | `ReadonlyJSONValue` | #### Type declaration | Name | Type | | --- | --- | | `key` | `Key` | | `oldValue` | `Value` | | `op` | `"del"` | * * * ### ExperimentalIndexDiff Ƭ **ExperimentalIndexDiff**: readonly `ExperimentalDiffOperation`<`IndexKey`\>\[\] This type is experimental and may change in the future. * * * ### ExperimentalNoIndexDiff Ƭ **ExperimentalNoIndexDiff**: readonly `ExperimentalDiffOperation`<`string`\>\[\] This type is experimental and may change in the future. * * * ### ExperimentalWatchCallbackForOptions Ƭ **ExperimentalWatchCallbackForOptions**<`Options`\>: `Options` extends `ExperimentalWatchIndexOptions` ? `ExperimentalWatchIndexCallback` : `ExperimentalWatchNoIndexCallback` #### Type parameters | Name | Type | | --- | --- | | `Options` | extends `ExperimentalWatchOptions` | * * * ### ExperimentalWatchIndexCallback Ƭ **ExperimentalWatchIndexCallback**: (`diff`: `ExperimentalIndexDiff`) => `void` #### Type declaration ▸ (`diff`): `void` Function that gets passed into experimentalWatch when doing a watch on a secondary index map and gets called when the data in Replicache changes. This type is experimental and may change in the future. ##### Parameters | Name | Type | | --- | --- | | `diff` | `ExperimentalIndexDiff` | ##### Returns `void` * * * ### ExperimentalWatchIndexOptions Ƭ **ExperimentalWatchIndexOptions**: `ExperimentalWatchNoIndexOptions` & { `indexName`: `string` } Options object passed to experimentalWatch. This is for an index watch. * * * ### ExperimentalWatchNoIndexCallback Ƭ **ExperimentalWatchNoIndexCallback**: (`diff`: `ExperimentalNoIndexDiff`) => `void` #### Type declaration ▸ (`diff`): `void` Function that gets passed into experimentalWatch and gets called when the data in Replicache changes. This type is experimental and may change in the future. ##### Parameters | Name | Type | | --- | --- | | `diff` | `ExperimentalNoIndexDiff` | ##### Returns `void` * * * ### ExperimentalWatchNoIndexOptions Ƭ **ExperimentalWatchNoIndexOptions**: `Object` Options object passed to experimentalWatch. This is for a non index watch. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `initialValuesInFirstDiff?` | `boolean` | When this is set to `true` (default is `false`), the `watch` callback will be called once asynchronously when watch is called. The arguments in that case is a diff where we consider all the existing values in Replicache as being added. | | `prefix?` | `string` | When provided, the `watch` is limited to changes where the `key` starts with `prefix`. | * * * ### ExperimentalWatchOptions Ƭ **ExperimentalWatchOptions**: `ExperimentalWatchIndexOptions` | `ExperimentalWatchNoIndexOptions` Options for experimentalWatch. This interface is experimental and may change in the future. * * * ### GetIndexScanIterator Ƭ **GetIndexScanIterator**: (`indexName`: `string`, `fromSecondaryKey`: `string`, `fromPrimaryKey`: `string` | `undefined`) => `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> #### Type declaration ▸ (`indexName`, `fromSecondaryKey`, `fromPrimaryKey`): `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> When using makeScanResult this is the type used for the function called when doing a scan with an `indexName`. ##### Parameters | Name | Type | Description | | --- | --- | --- | | `indexName` | `string` | The name of the index we are scanning over. | | `fromSecondaryKey` | `string` | The `fromSecondaryKey` is computed by `scan` and is the secondary key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanIndexOptions. | | `fromPrimaryKey` | `string` | `undefined` | The `fromPrimaryKey` is computed by `scan` and is the primary key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanIndexOptions. | ##### Returns `IterableUnion`<readonly \[key: IndexKey, value: ReadonlyJSONValue\]\> * * * ### GetScanIterator Ƭ **GetScanIterator**: (`fromKey`: `string`) => `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> #### Type declaration ▸ (`fromKey`): `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> This is called when doing a scan without an `indexName`. ##### Parameters | Name | Type | Description | | --- | --- | --- | | `fromKey` | `string` | The `fromKey` is computed by `scan` and is the key of the first entry to return in the iterator. It is based on `prefix` and `start.key` of the ScanNoIndexOptions. | ##### Returns `IterableUnion`<`Entry`<`ReadonlyJSONValue`\>\> * * * ### HTTPRequestInfo Ƭ **HTTPRequestInfo**: `Object` #### Type declaration | Name | Type | | --- | --- | | `errorMessage` | `string` | | `httpStatusCode` | `number` | * * * ### IndexDefinition Ƭ **IndexDefinition**: `Object` The definition of a single index. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `allowEmpty?` | `boolean` | If `true`, indexing empty values will not emit a warning. Defaults to `false`. | | `jsonPointer` | `string` | A JSON Pointer pointing at the sub value inside each value to index over. For example, one might index over users' ages like so: `{prefix: '/user/', jsonPointer: '/age'}` | | `prefix?` | `string` | The prefix, if any, to limit the index over. If not provided the values of all keys are indexed. | * * * ### IndexDefinitions Ƭ **IndexDefinitions**: `Object` An object as a map defining the indexes. The keys are the index names and the values are the index definitions. #### Index signature ▪ \[name: `string`\]: `IndexDefinition` * * * ### IndexKey Ƭ **IndexKey**: readonly \[secondary: string, primary: string\] When using indexes the key is a tuple of the secondary key and the primary key. * * * ### IterableUnion Ƭ **IterableUnion**<`T`\>: `AsyncIterable`<`T`\> | `Iterable`<`T`\> #### Type parameters | Name | | --- | | `T` | * * * ### JSONObject Ƭ **JSONObject**: `Object` A JSON object. This is a map from strings to JSON values or `undefined`. We allow `undefined` values as a convenience... but beware that the `undefined` values do not round trip to the server. For example: // Time t1await tx.set('a', {a: undefined});// time passes, in a new transactionconst v = await tx.get('a');console.log(v); // either {a: undefined} or {} #### Index signature ▪ \[key: `string`\]: `JSONValue` | `undefined` * * * ### JSONValue Ƭ **JSONValue**: `null` | `string` | `boolean` | `number` | `JSONValue`\[\] | `JSONObject` The values that can be represented in JSON * * * ### KVStoreProvider Ƭ **KVStoreProvider**: `Object` Provider for creating and deleting KVStore instances. #### Type declaration | Name | Type | | --- | --- | | `create` | `CreateKVStore` | | `drop` | `DropKVStore` | * * * ### KeyTypeForScanOptions Ƭ **KeyTypeForScanOptions**<`O`\>: `O` extends `ScanIndexOptions` ? `IndexKey` : `string` If the options contains an `indexName` then the key type is a tuple of secondary and primary. #### Type parameters | Name | Type | | --- | --- | | `O` | extends `ScanOptions` | * * * ### LogLevel Ƭ **LogLevel**: `"error"` | `"info"` | `"debug"` The different log levels. This is used to determine how much logging to do. `'error'` > `'info'` > `'debug'`... meaning `'error'` has highest priority and `'debug'` lowest. * * * ### MaybePromise Ƭ **MaybePromise**<`T`\>: `T` | `Promise`<`T`\> #### Type parameters | Name | | --- | | `T` | * * * ### MutationV0 Ƭ **MutationV0**: `Object` Mutation describes a single mutation done on the client. This is the legacy version (V0) and it is used when recovering mutations from old clients. #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `id` | `number` | | `name` | `string` | | `timestamp` | `number` | * * * ### MutationV1 Ƭ **MutationV1**: `Object` Mutation describes a single mutation done on the client. #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `clientID` | `ClientID` | | `id` | `number` | | `name` | `string` | | `timestamp` | `number` | * * * ### MutatorDefs Ƭ **MutatorDefs**: `Object` #### Index signature ▪ \[key: `string`\]: (`tx`: `WriteTransaction`, `args?`: `any`) => `MutatorReturn` * * * ### MutatorReturn Ƭ **MutatorReturn**<`T`\>: `MaybePromise`<`T` | `void`\> #### Type parameters | Name | Type | | --- | --- | | `T` | extends `ReadonlyJSONValue` = `ReadonlyJSONValue` | * * * ### PatchOperation Ƭ **PatchOperation**: { `key`: `string` ; `op`: `"put"` ; `value`: `ReadonlyJSONValue` } | { `key`: `string` ; `op`: `"del"` } | { `op`: `"clear"` } This type describes the patch field in a PullResponse and it is used to describe how to update the Replicache key-value store. * * * ### PendingMutation Ƭ **PendingMutation**: `Object` #### Type declaration | Name | Type | | --- | --- | | `args` | `ReadonlyJSONValue` | | `clientID` | `ClientID` | | `id` | `number` | | `name` | `string` | * * * ### Poke Ƭ **Poke**: `Object` #### Type declaration | Name | Type | | --- | --- | | `baseCookie` | `ReadonlyJSONValue` | | `pullResponse` | `PullResponseV1` | * * * ### PullRequest Ƭ **PullRequest**: `PullRequestV1` | `PullRequestV0` The JSON value used as the body when doing a POST to the pull endpoint. * * * ### PullRequestV0 Ƭ **PullRequestV0**: `Object` The JSON value used as the body when doing a POST to the pull endpoint. This is the legacy version (V0) and it is still used when recovering mutations from old clients. #### Type declaration | Name | Type | | --- | --- | | `clientID` | `ClientID` | | `cookie` | `ReadonlyJSONValue` | | `lastMutationID` | `number` | | `profileID` | `string` | | `pullVersion` | `0` | | `schemaVersion` | `string` | * * * ### PullRequestV1 Ƭ **PullRequestV1**: `Object` The JSON value used as the body when doing a POST to the pull endpoint. #### Type declaration | Name | Type | | --- | --- | | `clientGroupID` | `ClientGroupID` | | `cookie` | `Cookie` | | `profileID` | `string` | | `pullVersion` | `1` | | `schemaVersion` | `string` | * * * ### PullResponse Ƭ **PullResponse**: `PullResponseV1` | `PullResponseV0` * * * ### PullResponseOKV0 Ƭ **PullResponseOKV0**: `Object` The shape of a pull response under normal circumstances. #### Type declaration | Name | Type | | --- | --- | | `cookie?` | `ReadonlyJSONValue` | | `lastMutationID` | `number` | | `patch` | `PatchOperation`\[\] | * * * ### PullResponseOKV1 Ƭ **PullResponseOKV1**: `Object` The shape of a pull response under normal circumstances. #### Type declaration | Name | Type | | --- | --- | | `cookie` | `Cookie` | | `lastMutationIDChanges` | `Record`<`ClientID`, `number`\> | | `patch` | `PatchOperation`\[\] | * * * ### PullResponseV0 Ƭ **PullResponseV0**: `PullResponseOKV0` | `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` PullResponse defines the shape and type of the response of a pull. This is the JSON you should return from your pull server endpoint. * * * ### PullResponseV1 Ƭ **PullResponseV1**: `PullResponseOKV1` | `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` PullResponse defines the shape and type of the response of a pull. This is the JSON you should return from your pull server endpoint. * * * ### Puller Ƭ **Puller**: (`requestBody`: `PullRequest`, `requestID`: `string`) => `Promise`<`PullerResult`\> #### Type declaration ▸ (`requestBody`, `requestID`): `Promise`<`PullerResult`\> Puller is the function type used to do the fetch part of a pull. Puller needs to support dealing with pull request of version 0 and 1. Version 0 is used when doing mutation recovery of old clients. If a PullRequestV1 is passed in the n a PullerResultV1 should be returned. We do a runtime assert to make this is the case. If you do not support old clients you can just throw if `pullVersion` is `0`, ##### Parameters | Name | Type | | --- | --- | | `requestBody` | `PullRequest` | | `requestID` | `string` | ##### Returns `Promise`<`PullerResult`\> * * * ### PullerResult Ƭ **PullerResult**: `PullerResultV1` | `PullerResultV0` * * * ### PullerResultV0 Ƭ **PullerResultV0**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PullResponseV0` | * * * ### PullerResultV1 Ƭ **PullerResultV1**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PullResponseV1` | * * * ### PushRequest Ƭ **PushRequest**: `PushRequestV0` | `PushRequestV1` * * * ### PushRequestV0 Ƭ **PushRequestV0**: `Object` The JSON value used as the body when doing a POST to the push endpoint. This is the legacy version (V0) and it is still used when recovering mutations from old clients. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `clientID` | `ClientID` | \- | | `mutations` | `MutationV0`\[\] | \- | | `profileID` | `string` | \- | | `pushVersion` | `0` | \- | | `schemaVersion` | `string` | `schemaVersion` can optionally be used to specify to the push endpoint version information about the mutators the app is using (e.g., format of mutator args). | * * * ### PushRequestV1 Ƭ **PushRequestV1**: `Object` The JSON value used as the body when doing a POST to the push endpoint. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `clientGroupID` | `ClientGroupID` | \- | | `mutations` | `MutationV1`\[\] | \- | | `profileID` | `string` | \- | | `pushVersion` | `1` | \- | | `schemaVersion` | `string` | `schemaVersion` can optionally be used to specify to the push endpoint version information about the mutators the app is using (e.g., format of mutator args). | * * * ### PushResponse Ƭ **PushResponse**: `ClientStateNotFoundResponse` | `VersionNotSupportedResponse` The response from a push can contain information about error conditions. * * * ### Pusher Ƭ **Pusher**: (`requestBody`: `PushRequest`, `requestID`: `string`) => `Promise`<`PusherResult`\> #### Type declaration ▸ (`requestBody`, `requestID`): `Promise`<`PusherResult`\> Pusher is the function type used to do the fetch part of a push. The request is a POST request where the body is JSON with the type PushRequest. The return value should either be a HTTPRequestInfo or a PusherResult. The reason for the two different return types is that we didn't use to care about the response body of the push request. The default pusher implementation checks if the response body is JSON and if it matches the type PusherResponse. If it does, it is included in the return value. ##### Parameters | Name | Type | | --- | --- | | `requestBody` | `PushRequest` | | `requestID` | `string` | ##### Returns `Promise`<`PusherResult`\> * * * ### PusherResult Ƭ **PusherResult**: `Object` #### Type declaration | Name | Type | | --- | --- | | `httpRequestInfo` | `HTTPRequestInfo` | | `response?` | `PushResponse` | * * * ### ReadonlyJSONObject Ƭ **ReadonlyJSONObject**: `Object` Like JSONObject but deeply readonly #### Index signature ▪ \[key: `string`\]: `ReadonlyJSONValue` | `undefined` * * * ### ReadonlyJSONValue Ƭ **ReadonlyJSONValue**: `null` | `string` | `boolean` | `number` | `ReadonlyArray`<`ReadonlyJSONValue`\> | `ReadonlyJSONObject` Like JSONValue but deeply readonly * * * ### ScanIndexOptions Ƭ **ScanIndexOptions**: `Object` Options for scan when scanning over an index. When scanning over and index you need to provide the `indexName` and the `start` `key` is now a tuple consisting of secondary and primary key #### Type declaration | Name | Type | Description | | --- | --- | --- | | `indexName` | `string` | Do a scan over a named index. The `indexName` is the name of an index defined when creating the Replicache instance using indexes. | | `limit?` | `number` | Only include up to `limit` results. | | `prefix?` | `string` | Only include results starting with the _secondary_ keys starting with `prefix`. | | `start?` | { `exclusive?`: `boolean` ; `key`: `ScanOptionIndexedStartKey` } | When provided the scan starts at this key. | | `start.exclusive?` | `boolean` | Whether the `key` is exclusive or inclusive. | | `start.key` | `ScanOptionIndexedStartKey` | \- | * * * ### ScanNoIndexOptions Ƭ **ScanNoIndexOptions**: `Object` Options for scan when scanning over the entire key space. #### Type declaration | Name | Type | Description | | --- | --- | --- | | `limit?` | `number` | Only include up to `limit` results. | | `prefix?` | `string` | Only include keys starting with `prefix`. | | `start?` | { `exclusive?`: `boolean` ; `key`: `string` } | When provided the scan starts at this key. | | `start.exclusive?` | `boolean` | Whether the `key` is exclusive or inclusive. | | `start.key` | `string` | \- | * * * ### ScanOptionIndexedStartKey Ƭ **ScanOptionIndexedStartKey**: readonly \[secondary: string, primary?: string | undefined\] | `string` The key to start scanning at. If you are scanning the primary index (i.e., you did not specify `indexName`), then pass a single string for this field, which is the key in the primary index to scan at. If you are scanning a secondary index (i.e., you specified `indexName`), then use the tuple form. In that case, `secondary` is the secondary key to start scanning at, and `primary` (if any) is the primary key to start scanning at. * * * ### ScanOptions Ƭ **ScanOptions**: `ScanIndexOptions` | `ScanNoIndexOptions` Options for scan * * * ### TransactionEnvironment Ƭ **TransactionEnvironment**: `"client"` | `"server"` * * * ### TransactionLocation Ƭ **TransactionLocation**: `TransactionEnvironment` * * * ### TransactionReason Ƭ **TransactionReason**: `"initial"` | `"rebase"` | `"authoritative"` * * * ### UpdateNeededReason Ƭ **UpdateNeededReason**: { `type`: `"NewClientGroup"` } | { `type`: `"VersionNotSupported"` ; `versionType?`: `"push"` | `"pull"` | `"schema"` } * * * ### VersionNotSupportedResponse Ƭ **VersionNotSupportedResponse**: `Object` The server endpoint may respond with a `VersionNotSupported` error if it does not know how to handle the pullVersion, pushVersion or the schemaVersion. #### Type declaration | Name | Type | | --- | --- | | `error` | `"VersionNotSupported"` | | `versionType?` | `"pull"` | `"push"` | `"schema"` | ## Variables ### TEST\_LICENSE\_KEY • `Const` **TEST\_LICENSE\_KEY**: `"This key only good for automated testing"` * * * ### consoleLogSink • `Const` **consoleLogSink**: `LogSink` An implementation of \[\[LogSink\]\] that logs using `console.log` etc * * * ### version • `Const` **version**: `string` = `REPLICACHE_VERSION` The current version of Replicache. ## Functions ### deleteAllReplicacheData ▸ **deleteAllReplicacheData**(`opts?`): `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> Deletes all IndexedDB data associated with Replicache. Returns an object with the names of the successfully dropped databases and any errors encountered while dropping. #### Parameters | Name | Type | | --- | --- | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> **`Deprecated`** Use `dropAllDatabases` instead. * * * ### dropAllDatabases ▸ **dropAllDatabases**(`opts?`): `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> Deletes all IndexedDB data associated with Replicache. Returns an object with the names of the successfully dropped databases and any errors encountered while dropping. #### Parameters | Name | Type | | --- | --- | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<{ `dropped`: `string`\[\] ; `errors`: `unknown`\[\] }\> * * * ### dropDatabase ▸ **dropDatabase**(`dbName`, `opts?`): `Promise`<`void`\> Deletes a single Replicache database. #### Parameters | Name | Type | | --- | --- | | `dbName` | `string` | | `opts?` | `DropDatabaseOptions` | #### Returns `Promise`<`void`\> * * * ### filterAsyncIterable ▸ **filterAsyncIterable**<`V`\>(`iter`, `predicate`): `AsyncIterable`<`V`\> Filters an async iterable. This utility function is provided because it is useful when using makeScanResult. It can be used to filter out tombstones (delete entries) for example. #### Type parameters | Name | | --- | | `V` | #### Parameters | Name | Type | | --- | --- | | `iter` | `IterableUnion`<`V`\> | | `predicate` | (`v`: `V`) => `boolean` | #### Returns `AsyncIterable`<`V`\> * * * ### getDefaultPuller ▸ **getDefaultPuller**(`rep`): `Puller` This creates a default puller which uses HTTP POST to send the pull request. #### Parameters | Name | Type | | --- | --- | | `rep` | `Object` | | `rep.auth` | `string` | | `rep.pullURL` | `string` | #### Returns `Puller` * * * ### isScanIndexOptions ▸ **isScanIndexOptions**(`options`): options is ScanIndexOptions Type narrowing of ScanOptions. #### Parameters | Name | Type | | --- | --- | | `options` | `ScanOptions` | #### Returns options is ScanIndexOptions * * * ### makeIDBName ▸ **makeIDBName**(`name`, `schemaVersion?`): `string` Returns the name of the IDB database that will be used for a particular Replicache instance. #### Parameters | Name | Type | Description | | --- | --- | --- | | `name` | `string` | The name of the Replicache instance (i.e., the `name` field of `ReplicacheOptions`). | | `schemaVersion?` | `string` | The schema version of the database (i.e., the `schemaVersion` field of `ReplicacheOptions`). | #### Returns `string` * * * ### makeScanResult ▸ **makeScanResult**<`Options`\>(`options`, `getScanIterator`): `ScanResult`<`KeyTypeForScanOptions`<`Options`\>, `ReadonlyJSONValue`\> A helper function that makes it easier to implement scan with a custom backend. If you are implementing a custom backend and have an in memory pending async iterable we provide two helper functions to make it easier to merge these together. mergeAsyncIterables and filterAsyncIterable. For example: const scanResult = makeScanResult( options, options.indexName ? () => { throw Error('not implemented'); } : fromKey => { const persisted: AsyncIterable<Entry<ReadonlyJSONValue>> = ...; const pending: AsyncIterable<Entry<ReadonlyJSONValue | undefined>> = ...; const iter = await mergeAsyncIterables(persisted, pending); const filteredIter = await filterAsyncIterable( iter, entry => entry[1] !== undefined, ); return filteredIter; },); #### Type parameters | Name | Type | | --- | --- | | `Options` | extends `ScanOptions` | #### Parameters | Name | Type | | --- | --- | | `options` | `Options` | | `getScanIterator` | `Options` extends `ScanIndexOptions` ? `GetIndexScanIterator` : `GetScanIterator` | #### Returns `ScanResult`<`KeyTypeForScanOptions`<`Options`\>, `ReadonlyJSONValue`\> * * * ### mergeAsyncIterables ▸ **mergeAsyncIterables**<`A`, `B`\>(`iterableBase`, `iterableOverlay`, `compare`): `AsyncIterable`<`A` | `B`\> Merges an iterable on to another iterable. The two iterables need to be ordered and the `compare` function is used to compare two different elements. If two elements are equal (`compare` returns `0`) then the element from the second iterable is picked. This utility function is provided because it is useful when using makeScanResult. It can be used to merge an in memory pending async iterable on to a persistent async iterable for example. #### Type parameters | Name | | --- | | `A` | | `B` | #### Parameters | Name | Type | | --- | --- | | `iterableBase` | `IterableUnion`<`A`\> | | `iterableOverlay` | `IterableUnion`<`B`\> | | `compare` | (`a`: `A`, `b`: `B`) => `number` | #### Returns `AsyncIterable`<`A` | `B`\>