W↓
All docs
🔑
Sign Up/Sign In
electric-sql.com/docs/guides
Public Link
Apr 8, 2025, 9:37:57 AM - complete - 99.6 kB
Created by:
****ad@vlad.studio
Starting URLs:
https://electric-sql.com/docs/guides/auth
Crawl Prefixes:
https://electric-sql.com/docs/guides
## Page: https://electric-sql.com/docs/guides/auth  How to do authentication and authorization with Electric. Including examples for proxy and gatekeeper auth. How to do auth with Electric. Including examples for proxy and gatekeeper auth. ## It's all HTTP The golden rule with Electric is that it's all just HTTP. So when it comes to auth, you can use existing primitives, such as your API, middleware and external authorization services. ### Shapes are resources With Electric, you sync data using Shapes and shapes are just resources. You access them by making a request to `GET /v1/shape`, with the shape definition in the query string (`?table=items`, etc.). You can authorise access to them exactly the same way you would any other web resource. ### Requests can be proxied When you make a request to Electric, you can route it through an HTTP proxy or middleware stack. This allows you to authorise the request before it reaches Electric. 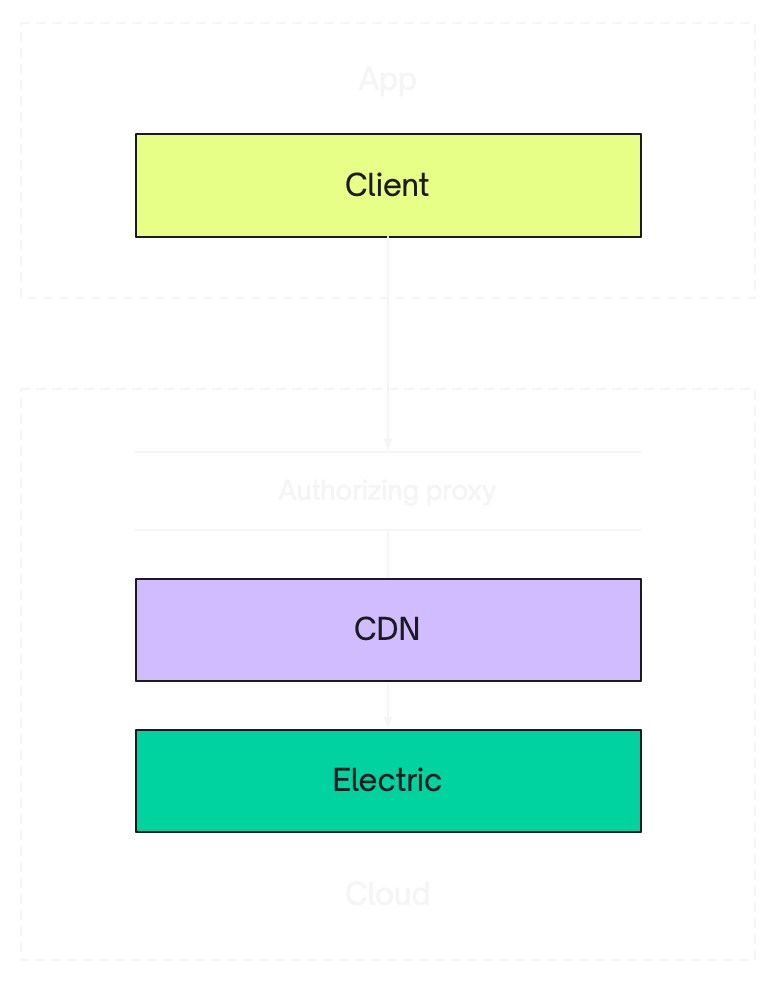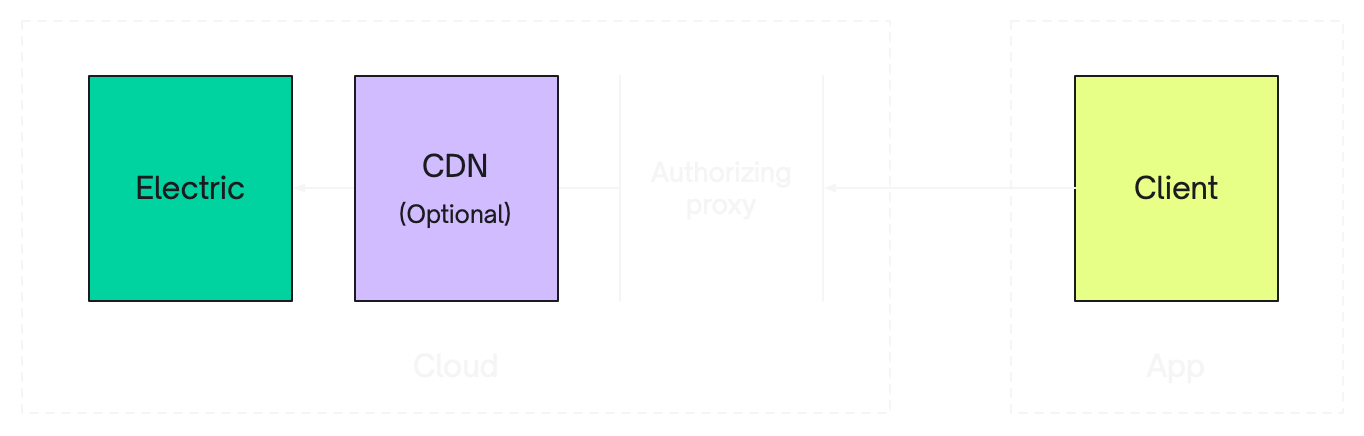 You can proxy the request in your cloud, or at the edge, in-front of a CDN. Your auth logic can query your database, or call an external service. It's all completely up-to-you. ### Rules are optional You _don't_ have to codify your auth logic into a database rule system. There's no need to use database rules to secure data access when your sync engine runs over standard HTTP. ## Patterns The two patterns we recommend and describe below, with code and examples, are: * proxy auth — authorising Shape requests using a proxy * gatekeeper auth — using your API to generate shape-scoped access tokens ### Proxy auth GitHub example See the proxy-auth example on GitHub for an example that implements this pattern. The simplest pattern is to authorise Shape requests using a reverse-proxy. The proxy can be your API, or a seperate proxy service or edge-function. When you make a request to sync a shape, route it via your API/proxy, validate the user credentials and shape parameters, and then only proxy the data through if authorized. For example: 1. add an `Authorization` header to your `GET /v1/shape` request 2. use the header to check that the client exists and has access to the shape 3. if not, return a `401` or `403` status to tell the client it doesn't have access 4. if the client does have access, proxy the request to Electric and stream the response back to the client #### Example When using the Typescript client, you can pass in a `headers` option to add an `Authorization` header. tsx const usersShape = (): ShapeStreamOptions => { const user = loadCurrentUser() return { url: new URL(`/api/shapes/users`, window.location.origin).href, headers: { authorization: `Bearer ${user.token}` } } } export default function ExampleComponent () { const { data: users } = useShape(usersShape()) } Then for the `/api/shapes/users` route: tsx export async function GET( request: Request, ) { const url = new URL(request.url) // Construct the upstream URL const originUrl = new URL(`http://localhost:3000/v1/shape`) // Copy over the relevant query params that the Electric client adds // so that we return the right part of the Shape log. url.searchParams.forEach((value, key) => { if ([`live`, `table`, `handle`, `offset`, `cursor`].includes(key)) { originUrl.searchParams.set(key, value) } }) // // Authentication and authorization // const user = await loadUser(request.headers.get(`authorization`)) // If the user isn't set, return 401 if (!user) { return new Response(`user not found`, { status: 401 }) } // Only query data the user has access to unless they're an admin. if (!user.roles.includes(`admin`)) { originUrl.searchParams.set(`where`, `"org_id" = ${user.org_id}`) } // When proxying long-polling requests, content-encoding & // content-length are added erroneously (saying the body is // gzipped when it's not) so we'll just remove them to avoid // content decoding errors in the browser. // // Similar-ish problem to https://github.com/wintercg/fetch/issues/23 let resp = await fetch(originUrl.toString()) if (resp.headers.get(`content-encoding`)) { const headers = new Headers(resp.headers) headers.delete(`content-encoding`) headers.delete(`content-length`) resp = new Response(resp.body, { status: resp.status, statusText: resp.statusText, headers, }) } return resp } ### Gatekeeper auth The Gatekeeper pattern works as follows: 1. post to a gatekeeper endpoint in your API to generate a shape-scoped auth token 2. make shape requests to Electric via an authorising proxy that validates the auth token against the request parameters The auth token should include a claim containing the shape definition. This allows the proxy to authorize the shape request by comparing the shape claim signed into the token with the shape defined in the request parameters. This keeps your main auth logic: * in your API (in the gatekeeper endpoint) where it's natural to do things like query the database and call external services * running _once_ when generating a token, rather than on the "hot path" of every shape request in your authorising proxy #### Implementation The GitHub example provides an `./api` service for generating auth tokens and three options for validating those auth tokens when proxying requests to Electric: 1. `./api` the API itself 2. `./caddy` a Caddy web server as a reverse proxy 3. `./edge` an edge function that you can run in front of a CDN The API is an Elixir/Phoenix web application that exposes two endpoints: 1. a gatekeeper endpoint at `POST /gatekeeper/:table` 2. a proxy endpoint at `GET /proxy/v1/shape` 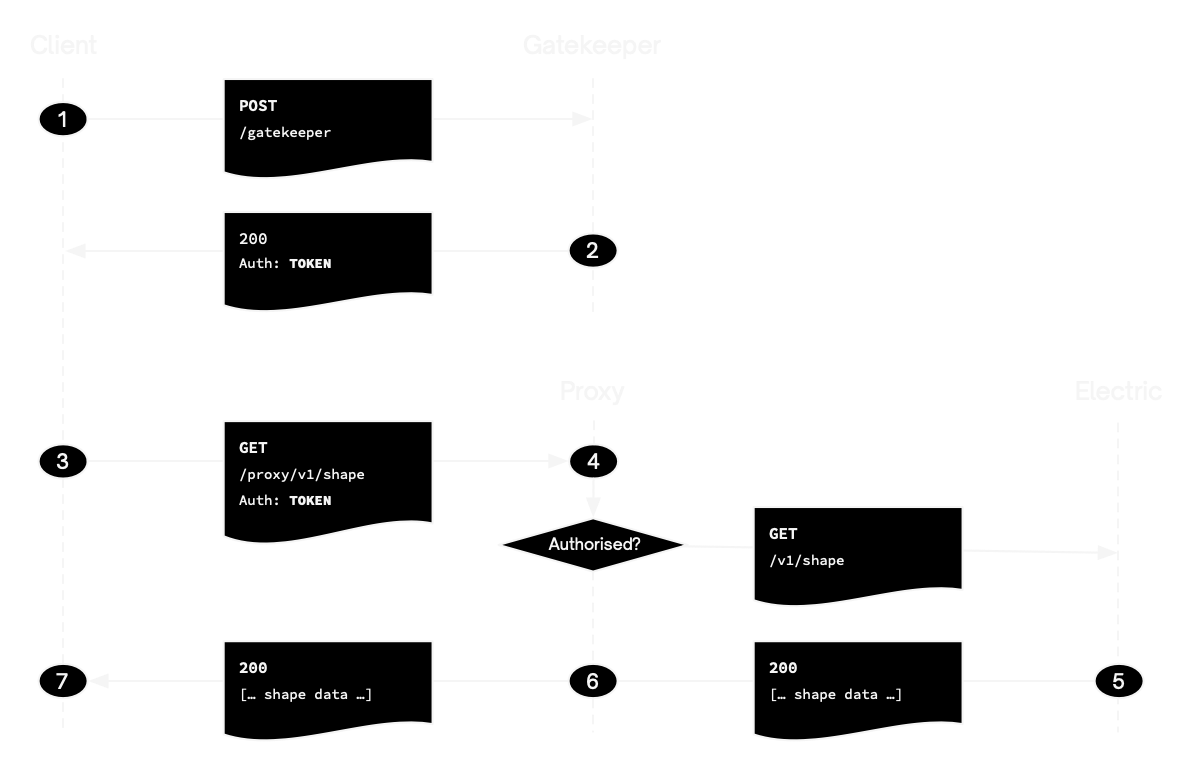 ##### Gatekeeper endpoint 1. the user makes a `POST` request to `POST /gatekeeper/:table` with some authentication credentials and a shape definition in the request parameters; the gatekeeper is then responsible for authorising the user's access to the shape 2. if access is granted, the gatekeeper generates a shape-scoped auth token and returns it to the client 3. the client can then use the auth token when connecting to the Electric HTTP API, via the proxy endpoint ##### Proxy endpoint 4. the proxy validates the JWT and verifies that the shape claim in the token matches the shape being requested; if so it sends the request on to Electric 5. Electric then handles the request as normal 6. sending a response back _through the proxy_ to the client The client can then process the data and make additional requests using the same token (step 3). If the token expires or is rejected, the client starts again (step 1). Interactive walkthrough See How to run on GitHub for an interactive walkthrough of the three different gatekeeper-auth example proxy options. #### Example See the ./client for an example using the Typescript client with gatekeeper and proxy endpoints: typescript import { FetchError, Shape, ShapeStream } from '@electric-sql/client' const API_URL = process.env.API_URL || 'http://localhost:4000' /* * Makes a request to the gatekeeper endpoint to fetch a config object * in the format expected by the ShapeStreamOptions including the * proxy `url` to connect to and auth `headers`. */ async function fetchConfig() { const url = `${API_URL}/gatekeeper/items` const resp = await fetch(url, {method: 'POST'}) return await resp.json() } // Stream the shape through the proxy, using the url and auth headers // provided by the gatekeeper. const config = await fetchConfig() const stream = new ShapeStream({ ...config, onError: async (error) => { if (error instanceof FetchError) { const status = error.status console.log('handling fetch error: ', status) // If the auth token is invalid or expires, hit the gatekeeper // again to update the auth headers and thus keep streaming // without interruption. if (status === 401 || status === 403) { return await fetchConfig() } } throw error } }) // Materialize the stream into a `Shape` and subscibe to data changes // so we can see the client working. const shape = new Shape(stream) shape.subscribe(({ rows }) => { console.log('num rows: ', rows ? rows.length : 0) }) ### Dynamic Auth Options The TypeScript client supports function-based options for headers and params, making it easy to handle dynamic auth tokens: typescript const stream = new ShapeStream({ url: 'http://localhost:3000/v1/shape', headers: { // Token will be refreshed on each request 'Authorization': async () => `Bearer ${await getAccessToken()}` } }) This pattern is particularly useful when: * Your auth tokens need periodic refreshing * You're using session-based authentication * You need to fetch tokens from a secure storage * You want to handle token rotation automatically The function is called when needed and its value is resolved in parallel with other dynamic options, making it efficient for real-world auth scenarios. ## Notes ### External services Both proxy and gatekeeper patterns work well with external auth services. If you're using an external authentication service, such as Auth0, to generate user credentials, for example, to generate a JWT, you just need to make sure that you can decode the JWT in your proxy or gatekeeper endpoint. If you're using an external authorization service to authorize a user's access to a shape, then you can call this whereever you run your authorization logic. For proxy auth this is the proxy. For gatekeeper auth this is the gatekeeper endpoint. Note that if you're using a distributed auth service to ensure consistent distributed auth, such as Authzed, then this works best with the proxy auth pattern. This is because you explicitly _want_ to authorize the user each shape request, as opposed to the gatekeeper generating a token that can potentially become stale. ### CDN <-> Proxy If you're deploying Electric behind a CDN, then it's best to run your authorising proxy at the edge, between your CDN and your user. Both proxy and gatekeeper patterns work well for this. The gatekeeper pattern is ideal because it minimises the logic that your proxy needs to perform at the edge and minimises the network and database access that you need to provide to your edge worker. See the edge function proxy option in the gatekeeper example for an example designed to run at the edge on Supabase Edge Functions. --- ## Page: https://electric-sql.com/docs/guides/shapes  Shapes are the core primitive for controlling sync in the ElectricSQL system. ## What is a Shape? Electric syncs little subsets of your Postgres data into local apps and services. Those subsets are defined using Shapes. ### Little subsets Imagine a Postgres database in the cloud with lots of data stored in it. It's often impractical or unwanted to sync all of this data over the network onto a local device. A shape is a way of defining a subset of that data that you'd like to sync into a local app. Defining shapes allows you to sync just the data you want and just the data that's practical to sync onto the local device.  A client can choose to sync one shape, or lots of shapes. Many clients can sync the same shape. Multiple shapes can overlap. ## Defining shapes Shapes are defined by: * a table, such as `items` * an optional where clause to filter which rows are included in the shape * an optional columns clause to select which columns are included A shape contains all of the rows in the table that match the where clause, if provided. If a columns clause is provided, the synced rows will only contain those selected columns. Limitations Shapes are currently single table. Shape definitions are immutable. ### Table This is the root table of the shape. All shapes must specify a table and it must match a table in your Postgres database. The value can be just a tablename like `projects`, or can be a qualified tablename prefixed by the database schema using a `.` delimiter, such as `foo.projects`. If you don't provide a schema prefix, then the table is assumed to be in the `public.` schema. #### Partitioned Tables Electric supports subscribing to declaratively partitioned tables, both individual partitions and the root table of all partitions. Consider the following partitioned schema: sql CREATE TABLE measurement ( city_id int not null, logdate date not null, peaktemp int, unitsales int ) PARTITION BY RANGE (logdate); CREATE TABLE measurement_y2025m02 PARTITION OF measurement FOR VALUES FROM ('2025-02-01') TO ('2025-03-01'); CREATE TABLE measurement_y2025m03 PARTITION OF measurement FOR VALUES FROM ('2025-03-01') TO ('2025-04-01'); We create 2 shapes, one on the root table `measurement` and one on the `measurement_y2025m03` partition: sh curl -i 'http://localhost:3000/v1/shape?table=measurement&offset=-1' curl -i 'http://localhost:3000/v1/shape?table=measurement_y2025m03&offset=-1' The shape based on the `measurement_y2025m03` partition will only receive writes that fall within the partition range, that is with `logdate >= '2025-02-01' AND logdate < '2025-03-01'` whereas the shape based on the root `measurements` table will receive all writes to all partitions. ### Where clause Shapes can define an optional where clause to filter out which rows from the table are included in the shape. Only rows that match the where clause will be included. The where clause must be a valid PostgreSQL query expression in SQL syntax, e.g.: * `title='Electric'` * `status IN ('backlog', 'todo')` Where clauses support: 1. columns of numerical types, `boolean`, `uuid`, `text`, `interval`, date and time types (with the exception of `timetz`), Arrays (but not yet Enums, except when explicitly casting them to `text`) 2. operators that work on those types: arithmetics, comparisons, logical/boolean operators like `OR`, string operators like `LIKE`, etc. 3. positional placeholders, like `$1`, values for which must be provided alongside the where clause. You can use `AND` and `OR` to group multiple conditions, e.g.: * `title='Electric' OR title='SQL'` * `title='Electric' AND status='todo'` Where clauses are limited in that they: 1. can only refer to columns in the target row 2. can't perform joins or refer to other tables 3. can't use non-deterministic SQL functions like `count()` or `now()` When constructing a where clause with user input as a filter, it's recommended to use a positional placeholder (`$1`) to avoid SQL injection-like situations. For example, if filtering a table on a user id, it's better to use `where=user = $1` with `params[1]=provided_id`. If not using positional placeholders and constructing where clauses yourself, take care to SQL-escape user input. See `known_functions.ex` and `parser.ex` for the source of truth on which types, operators and functions are currently supported. If you need a feature that isn't supported yet, please raise a feature request. Throughput Where clause evaluation impacts data throughput. Some where clauses are optimized. ### Columns This is an optional list of columns to select. When specified, only the columns listed are synced. When not specified all columns are synced. For example: * `columns=id,title,status` - only include the `id`, `title` and `status` columns * `columns=id,"Status-Check"` - only include `id` and `Status-Check` columns, quoting the identifiers where necessary The specified columns must always include the primary key column(s), and should be formed as a comma separated list of column names — exactly as they are in the database schema. If the identifier was defined as case sensitive and/or with special characters, then you must quote it. ## Subscribing to shapes Local clients establish shape subscriptions, typically using client libraries. These sync data from the Electric sync engine into the client using the HTTP API. The sync service maintains shape subscriptions and streams any new data and data changes to the local client. In the client, shapes can be held as objects in memory, for example using a `useShape` hook, or in a normalised store or database like PGlite. ### HTTP You can sync shapes manually using the `GET /v1/shape` endpoint. First make an initial sync request to get the current data for the Shape, such as: sh curl -i 'http://localhost:3000/v1/shape?table=foo&offset=-1' Then switch into a live mode to use long-polling to receive real-time updates: sh curl -i 'http://localhost:3000/v1/shape?table=foo&live=true&offset=...&handle=...' These requests both return an array of Shape Log entries. You can process these manually, or use a higher-level client. ### Typescript You can use the Typescript Client to process the Shape Log and materialised it into a `Shape` object for you. First install using: sh npm i @electric-sql/client Instantiate a `ShapeStream` and materialise into a `Shape`: ts import { ShapeStream, Shape } from '@electric-sql/client' const stream = new ShapeStream({ url: `http://localhost:3000/v1/shape`, params: { table: `foo` } }) const shape = new Shape(stream) // Returns promise that resolves with the latest shape data once it's fully loaded await shape.rows You can register a callback to be notified whenever the shape data changes: ts shape.subscribe(({ rows }) => { // rows is an array of the latest value of each row in a shape. }) Or you can use framework integrations like the `useShape` hook to automatically bind materialised shapes to your components. See the Quickstart and HTTP API docs for more information. ## Throughput Electric evaluates where clauses when processing changes from Postgres and matching them to shape logs. If there are lots of shapes, this means we have to evaluate lots of where clauses. This has an impact on data throughput. There are two kinds of where clauses: 1. optimized where clauses: a subset of clauses that we've optimized the evaluation of 2. non-optimized where clauses: all other where clauses With non-optimized where clauses, throughput is inversely proportional to the number of shapes. If you have 10 shapes, Electric can process 1,400 changes per second. If you have 100 shapes, throughput drops to 140 changes per second. With optimized where clauses, Electric can evaluate millions of clauses at once and maintain a consistent throughput of ~5,000 row changes per second **no matter how many shapes you have**. If you have 10 shapes, Electric can process 5,000 changes per second. If you have 1,000 shapes, throughput remains at 5,000 changes per second. For more details see the benchmarks. ### Optimized where clauses We currently optimize the evaluation of the following clauses: * `field = constant` - literal equality checks against a constant value. We optimize this by indexing shapes by their constant, allowing a single lookup to retrieve all shapes for that constant instead of evaluating the where clause for each shape. Note that this index is internal to Electric and unrelated to Postgres indexes. * `field = constant AND another_condition` - the `field = constant` part of the where clause is optimized as above, and any shapes that match are iterated through to check the other condition. Providing the first condition is enough to filter out most of the shapes, the write processing will be fast. If however `field = const` matches for a large number of shapes, then the write processing will be slower since each of the shapes will need to be iterated through. * `a_non_optimized_condition AND field = constant` - as above. The order of the clauses is not important (Electric will filter by optimized clauses first). ### Row filtering We use row filtering where possible to reduce the amount of data sent over the replication stream. Based on the active shapes and their where clauses, we can determine which rows should be included in the replication stream to be filtered directly in Postgres. When using custom data types in where clauses, like enums or domains, row filtering at the replication level is not available, and thus all changes will be sent over the replication stream for the relevant tables. ## Limitations ### Single table Shapes are currently single table only. In the old version of Electric, Shapes had an include tree that allowed you to sync nested relations. The new Electric has not yet implemented support for include trees. You can upvote and discuss adding support for include trees here: * Shape support for include trees #1608 Include tree workarounds There are some practical workarounds you can already use to sync related data, based on subscribing to multiple shapes and joining in the client. For a one-level deep include tree, such as "sync this project with its issues", you can sync one shape for projects `where="id=..."` and another for issues `where="project_id=..."`. For multi-level include trees, such as "sync this project with its issues and their comments", you can denormalise the `project_id` onto the lower tables so that you can also sync comments `where="project_id=1234"`. Where necessary, you can use triggers to update these denormalised columns. ### Immutable Shape definitions are currently immutable. Once a shape subscription has been started, it's definition cannot be changed. If you want to change the data in a shape, you need to start a new subscription. You can upvote and discuss adding support for mutable shapes here: * Editable shapes #1677 ### Dropping tables When dropping a table from Postgres you need to _manually_ delete all shapes that are defined on that table. This is especially important if you intend to recreate the table afterwards (possibly with a different schema) as the shape will contain stale data from the old table. Therefore, recreating the table only works if you first delete the shape. Electric does not yet automatically delete shapes when tables are dropped because Postgres does not stream DDL statements (such as `DROP TABLE`) on the logical replication stream that Electric uses to detect changes. However, we are actively exploring approaches for automated shape deletion in this GitHub issue. --- ## Page: https://electric-sql.com/docs/guides/writes  How to do local writes and write-path sync with Electric. Includes patterns for online writes, optimistic state, shared persistent optimistic state and through-the-database sync. With accompanying code in the write-patterns example. ## Local writes with Electric Electric does read-path sync. It syncs data out-of Postgres, into local apps and services. Electric does not do write-path sync. It doesn't provide (or prescribe) a built-in solution for getting data back into Postgres from local apps and services. So how do you handle local writes with Electric? Well, the design philosophy behind Electric is to be composable and integrate with your existing stack. So, just as you can sync into any client you like, you can implement writes in any way you like, using a variety of different patterns. ## Patterns This guide describes four different patterns for handling writes with Electric. It shows code examples and discusses trade-offs to consider when choosing between them. 1. online writes 2. optimistic state 3. shared persistent optimistic state 4. through-the-database sync All of the patterns use Electric for the read-path sync (i.e.: to sync data from Postgres into the local app) and use a different approach for the write-path (i.e.: how they handle local writes and get data from the local app back into Postgres). They are introduced in order of simplicity. So the simplest and easiest to implement first and the more powerful but more complex patterns further down ‐ where you may prefer to reach for a framework rather than implement yourself. ### 1\. Online writes (source code) The first pattern is simply to use online writes. Not every app needs local, offline writes. Some apps are read-only. Some only have occasional writes or are fine requiring the user to be online in order to edit data. In this case, you can combine Electric sync with web service calls to send writes to a server. For example, the implementation in `patterns/1-online-writes` runs a simple Node server (in `api.js`) and uses REST API calls for writes: tsx import React from 'react' import { v4 as uuidv4 } from 'uuid' import { useShape } from '@electric-sql/react' import api from '../../shared/app/client' import { ELECTRIC_URL, envParams } from '../../shared/app/config' type Todo = { id: string title: string completed: boolean created_at: Date } export default function OnlineWrites() { // Use Electric's `useShape` hook to sync data from Postgres // into a React state variable. const { isLoading, data } = useShape<Todo>({ url: `${ELECTRIC_URL}/v1/shape`, params: { table: 'todos', ...envParams, }, parser: { timestamptz: (value: string) => new Date(value), }, }) const todos = data ? data.sort((a, b) => +a.created_at - +b.created_at) : [] // Handle user input events by making requests to the backend // API to create, update and delete todos. async function createTodo(event: React.FormEvent) { event.preventDefault() const form = event.target as HTMLFormElement const formData = new FormData(form) const title = formData.get('todo') as string const path = '/todos' const data = { id: uuidv4(), title: title, created_at: new Date(), } await api.request(path, 'POST', data) form.reset() } async function updateTodo(todo: Todo) { const path = `/todos/${todo.id}` const data = { completed: !todo.completed, } await api.request(path, 'PUT', data) } async function deleteTodo(event: React.MouseEvent, todo: Todo) { event.preventDefault() const path = `/todos/${todo.id}` await api.request(path, 'DELETE') } if (isLoading) { return <div className="loading">Loading …</div> } // prettier-ignore return ( <div id="online-writes" className="example"> <h3>1. Online writes</h3> <ul> {todos.map((todo) => ( <li key={todo.id}> <label> <input type="checkbox" checked={todo.completed} onChange={() => updateTodo(todo)} /> <span className={`title ${ todo.completed ? 'completed' : '' }`}> { todo.title } </span> </label> <a href="#delete" className="close" onClick={(event) => deleteTodo(event, todo)}> ✕</a> </li> ))} {todos.length === 0 && ( <li>All done 🎉</li> )} </ul> <form onSubmit={createTodo}> <input type="text" name="todo" placeholder="Type here …" required /> <button type="submit"> Add </button> </form> </div> ) } #### Benefits Online writes are very simple to implement with your existing API. The pattern allows you to create apps that are fast and available offline for reading data. Good use-cases include: * live dashboards, data analytics and data visualisation * AI applications that generate embeddings in the cloud * systems where writes require online integration anyway, e.g.: making payments #### Drawbacks You have the network on the write path. This can be slow and laggy with the user left watching loading spinners. The UI doesn't update until the server responds. Applications won't work offline. ### 2\. Optimistic state (source code) The second pattern extends the online pattern above with support for local offline writes with simple optimistic state. Optimistic state is state that you display "optimistically" whilst waiting for an asynchronous operation, like sending data to a server, to complete. This allows local writes to be accepted when offline and displayed immediately to the user, by merging the synced state with the optimistic state when rendering. When the writes do succeed, they are automatically synced back to the app via Electric and the local optimistic state can be discarded. The example implementation in `patterns/2-optimistic-state` uses the same REST API calls as the online example above, along with React's built in `useOptimistic` hook to apply and discard the optimistic state. tsx import React, { useOptimistic, useTransition } from 'react' import { v4 as uuidv4 } from 'uuid' import { matchBy, matchStream } from '@electric-sql/experimental' import { useShape } from '@electric-sql/react' import api from '../../shared/app/client' import { ELECTRIC_URL, envParams } from '../../shared/app/config' type Todo = { id: string title: string completed: boolean created_at: Date } type PartialTodo = Partial<Todo> & { id: string } type Write = { operation: 'insert' | 'update' | 'delete' value: PartialTodo } export default function OptimisticState() { const [isPending, startTransition] = useTransition() // Use Electric's `useShape` hook to sync data from Postgres // into a React state variable. // // Note that we also unpack the `stream` from the useShape // return value, so that we can monitor it below to detect // local writes syncing back from the server. const { isLoading, data, stream } = useShape<Todo>({ url: `${ELECTRIC_URL}/v1/shape`, params: { table: 'todos', ...envParams, }, parser: { timestamptz: (value: string) => new Date(value), }, }) const sorted = data ? data.sort((a, b) => +a.created_at - +b.created_at) : [] // Use React's built in `useOptimistic` hook. This provides // a mechanism to apply local optimistic state whilst writes // are being sent-to and syncing-back-from the server. const [todos, addOptimisticState] = useOptimistic( sorted, (synced: Todo[], { operation, value }: Write) => { switch (operation) { case 'insert': return synced.some((todo) => todo.id === value.id) ? synced : [...synced, value as Todo] case 'update': return synced.map((todo) => todo.id === value.id ? { ...todo, ...value } : todo ) case 'delete': return synced.filter((todo) => todo.id !== value.id) } } ) // These are the same event handler functions from the online // example, extended with `startTransition` -> `addOptimisticState` // to apply local optimistic state. // // Note that the local state is applied: // // 1. whilst the HTTP request is being made to the API server; and // 2. until the write syncs back through the Electric shape stream // // This is slightly different from most optimistic state examples // because we wait for the sync as well as the api request. async function createTodo(event: React.FormEvent) { event.preventDefault() const form = event.target as HTMLFormElement const formData = new FormData(form) const title = formData.get('todo') as string const path = '/todos' const data = { id: uuidv4(), title: title, created_at: new Date(), completed: false, } startTransition(async () => { addOptimisticState({ operation: 'insert', value: data }) const fetchPromise = api.request(path, 'POST', data) const syncPromise = matchStream( stream, ['insert'], matchBy('id', data.id) ) await Promise.all([fetchPromise, syncPromise]) }) form.reset() } async function updateTodo(todo: Todo) { const { id, completed } = todo const path = `/todos/${id}` const data = { id, completed: !completed, } startTransition(async () => { addOptimisticState({ operation: 'update', value: data }) const fetchPromise = api.request(path, 'PUT', data) const syncPromise = matchStream(stream, ['update'], matchBy('id', id)) await Promise.all([fetchPromise, syncPromise]) }) } async function deleteTodo(event: React.MouseEvent, todo: Todo) { event.preventDefault() const { id } = todo const path = `/todos/${id}` startTransition(async () => { addOptimisticState({ operation: 'delete', value: { id } }) const fetchPromise = api.request(path, 'DELETE') const syncPromise = matchStream(stream, ['delete'], matchBy('id', id)) await Promise.all([fetchPromise, syncPromise]) }) } if (isLoading) { return <div className="loading">Loading …</div> } // The template below the heading is identical to the other patterns. // prettier-ignore return ( <div id="optimistic-state" className="example"> <h3> <span className="title"> 2. Optimistic state </span> <span className={isPending ? 'pending' : 'pending hidden'} /> </h3> <ul> {todos.map((todo) => ( <li key={todo.id}> <label> <input type="checkbox" checked={todo.completed} onChange={() => updateTodo(todo)} /> <span className={`title ${ todo.completed ? 'completed' : '' }`}> { todo.title } </span> </label> <a href="#delete" className="close" onClick={(event) => deleteTodo(event, todo)}> ✕</a> </li> ))} {todos.length === 0 && ( <li>All done 🎉</li> )} </ul> <form onSubmit={createTodo}> <input type="text" name="todo" placeholder="Type here …" required /> <button type="submit"> Add </button> </form> </div> ) } #### Benefits Using optimistic state allows you to take the network off the write path and allows you to create apps that are fast and available offline for both reading and writing data. The pattern is simple to implement. You can handle writes using your existing API. Good use-cases include: * management apps and interactive dashboards * apps that want to feel fast and avoid loading spinners on write * mobile apps that want to be resilient to patchy connectivity #### Drawbacks This example illustrates a "simple" approach where the optimistic state: 1. is component-scoped, i.e.: is only available within the component that makes the write 2. is not persisted This means that other components may display inconsistent information and users may be confused by the optimistic state dissapearing if they unmount the component or reload the page. These limitations are addressed by the more comprehensive approach in the next pattern. ### 3\. Shared persistent optimistic state (source code) The third pattern extends the second pattern above by storing the optimistic state in a shared, persistent local store. This makes offline writes more resilient and avoids components getting out of sync. It's a compelling point in the design space: providing good UX and DX without introducing too much complexity or any heavy dependencies. This pattern can be implemented with a variety of client-side state management and storage mechanisms. This example in `patterns/3-shared-persistent` uses valtio with localStorage for a shared, persistent, reactive store. This allows us to keep the code very similar to the simple optimistic state example above (with a valtio `useSnapshot` and plain reduce function replacing `useOptimistic`). tsx import React, { useTransition } from 'react' import { v4 as uuidv4 } from 'uuid' import { subscribe, useSnapshot } from 'valtio' import { proxyMap } from 'valtio/utils' import { type Operation, ShapeStream } from '@electric-sql/client' import { matchBy, matchStream } from '@electric-sql/experimental' import { useShape } from '@electric-sql/react' import api from '../../shared/app/client' import { ELECTRIC_URL, envParams } from '../../shared/app/config' const KEY = 'electric-sql/examples/write-patterns/shared-persistent' type Todo = { id: string title: string completed: boolean created_at: Date } type PartialTodo = Partial<Todo> & { id: string } type LocalWrite = { id: string operation: Operation value: PartialTodo } // Define a shared, persistent, reactive store for local optimistic state. const optimisticState = proxyMap<string, LocalWrite>( JSON.parse(localStorage.getItem(KEY) || '[]') ) subscribe(optimisticState, () => { localStorage.setItem(KEY, JSON.stringify([...optimisticState])) }) /* * Add a local write to the optimistic state */ function addLocalWrite(operation: Operation, value: PartialTodo): LocalWrite { const id = uuidv4() const write: LocalWrite = { id, operation, value, } optimisticState.set(id, write) return write } /* * Subscribe to the shape `stream` until the local write syncs back through it. * At which point, delete the local write from the optimistic state. */ async function matchWrite( stream: ShapeStream<Todo>, write: LocalWrite ): Promise<void> { const { operation, value } = write const matchFn = operation === 'delete' ? matchBy('id', value.id) : matchBy('write_id', write.id) try { await matchStream(stream, [operation], matchFn) } catch (_err) { return } optimisticState.delete(write.id) } /* * Make an HTTP request to send the write to the API server. * If the request fails, delete the local write from the optimistic state. * If it succeeds, return the `txid` of the write from the response data. */ async function sendRequest( path: string, method: string, { id, value }: LocalWrite ): Promise<void> { const data = { ...value, write_id: id, } let response: Response | undefined try { response = await api.request(path, method, data) } catch (_err) { // ignore } if (response === undefined || !response.ok) { optimisticState.delete(id) } } export default function SharedPersistent() { const [isPending, startTransition] = useTransition() // Use Electric's `useShape` hook to sync data from Postgres. const { isLoading, data, stream } = useShape<Todo>({ url: `${ELECTRIC_URL}/v1/shape`, params: { table: 'todos', ...envParams, }, parser: { timestamptz: (value: string) => new Date(value), }, }) const sorted = data ? data.sort((a, b) => +a.created_at - +b.created_at) : [] // Get the local optimistic state. const localWrites = useSnapshot<Map<string, LocalWrite>>(optimisticState) const computeOptimisticState = ( synced: Todo[], writes: LocalWrite[] ): Todo[] => { return writes.reduce( (synced: Todo[], { operation, value }: LocalWrite): Todo[] => { switch (operation) { case 'insert': return [...synced, value as Todo] case 'update': return synced.map((todo) => todo.id === value.id ? { ...todo, ...value } : todo ) case 'delete': return synced.filter((todo) => todo.id !== value.id) default: return synced } }, synced ) } const todos = computeOptimisticState(sorted, [...localWrites.values()]) // These are the same event handler functions from the previous optimistic // state pattern, adapted to add the state to the shared, persistent store. async function createTodo(event: React.FormEvent) { event.preventDefault() const form = event.target as HTMLFormElement const formData = new FormData(form) const title = formData.get('todo') as string const path = '/todos' const data = { id: uuidv4(), title: title, completed: false, created_at: new Date(), } startTransition(async () => { const write = addLocalWrite('insert', data) const fetchPromise = sendRequest(path, 'POST', write) const syncPromise = matchWrite(stream, write) await Promise.all([fetchPromise, syncPromise]) }) form.reset() } async function updateTodo(todo: Todo) { const { id, completed } = todo const path = `/todos/${id}` const data = { id, completed: !completed, } startTransition(async () => { const write = addLocalWrite('update', data) const fetchPromise = sendRequest(path, 'PUT', write) const syncPromise = matchWrite(stream, write) await Promise.all([fetchPromise, syncPromise]) }) } async function deleteTodo(event: React.MouseEvent, todo: Todo) { event.preventDefault() const { id } = todo const path = `/todos/${id}` const data = { id, } startTransition(async () => { const write = addLocalWrite('delete', data) const fetchPromise = sendRequest(path, 'DELETE', write) const syncPromise = matchWrite(stream, write) await Promise.all([fetchPromise, syncPromise]) }) } if (isLoading) { return <div className="loading">Loading …</div> } // The template below the heading is identical to the other patterns. // prettier-ignore return ( <div id="optimistic-state" className="example"> <h3> <span className="title"> 3. Shared persistent </span> <span className={isPending ? 'pending' : 'pending hidden'} /> </h3> <ul> {todos.map((todo) => ( <li key={todo.id}> <label> <input type="checkbox" checked={todo.completed} onChange={() => updateTodo(todo)} /> <span className={`title ${ todo.completed ? 'completed' : '' }`}> { todo.title } </span> </label> <a href="#delete" className="close" onClick={(event) => deleteTodo(event, todo)}> ✕</a> </li> ))} {todos.length === 0 && ( <li>All done 🎉</li> )} </ul> <form onSubmit={createTodo}> <input type="text" name="todo" placeholder="Type here …" required /> <button type="submit"> Add </button> </form> </div> ) } #### Benefits This is a powerful and pragmatic pattern, occupying a compelling point in the design space. It's relatively simple to implement. Persisting optimistic state makes local writes more resilient. Storing optimistic state in a shared store allows all your components to see and react to it. This avoids the weaknesses with ephemoral, component-scoped optimistic state and makes this pattern more suitable for more complex, real world apps. Seperating immutable synced state from mutable local state also makes it easy to reason about and implement rollback strategies. Worst case, you can always just wipe the local state and/or re-sync the server state, without having to unpick some kind of merged mutable store. Good use-cases include: * building local-first software * interactive SaaS applications * collaboration and authoring software #### Drawbacks Combining data on-read makes local reads slightly slower. Whilst a persistent local store is used for optimistic state, writes are still made via an API. This can often be helpful and pragmatic, allowing you to re-use your existing API. However, you may prefer to avoid this, with a purer local-first approach based on syncing through a local embedded database. #### Implementation notes The merge logic in the `matchWrite` function differs from the previous optimistic state example in that it supports rebasing local optimistic state on concurrent updates from other users. The entrypoint for handling rollbacks has the local write context available. So it's able to rollback individual writes, rather than wiping the whole local state. Because it has the shared store available, it would also be possible to extend this to implement more sophisticated strategies. Such as also removing other local writes that causally depended-on or were related-to the rejected write. ### 4\. Through the database sync (source code) The fourth pattern extends the concept of shared, persistent optimistic state all the way to an embedded local database. This provides a pure local-first experience, where the application code talks directly to a local database and changes sync automatically in the background. This "power" comes at the cost of increased complexity in the form of an embedded database, complex local schema and loss of context when handling rollbacks. The example in `patterns/4-through-the-db` uses PGlite to store both synced and local optimistic state. Specifically, it: 1. syncs data into an immutable `todos_synced` table 2. persists optimistic state in a shadow `todos_local` table; and 3. combines the two on read using a `todos` view. For the write path sync it: 4. uses `INSTEAD OF` triggers to * redirect writes made to the `todos` view to the `todos_local` table * keep a log of local writes in a `changes` table 5. uses `NOTIFY` to drive a sync utility * which sends the changes to the server Through this, the implementation: * automatically manages optimistic state lifecycle * presents a single table interface for reads and writes * auto-syncs the local writes to the server The application code in `index.tsx` stays very simple. Most of the complexity is abstracted into the local database schema, defined in `local-schema.sql`. The write-path sync utility in `sync.ts` handles sending data to the server. These are shown in the three tabs below: tsx import React, { useEffect, useState } from 'react' import { v4 as uuidv4 } from 'uuid' import { PGliteProvider, useLiveQuery, usePGlite, } from '@electric-sql/pglite-react' import { type PGliteWithLive } from '@electric-sql/pglite/live' import loadPGlite from './db' import ChangeLogSynchronizer from './sync' type Todo = { id: string title: string completed: boolean created_at: Date } /* * Setup the local PGlite database, with automatic change detection and syncing. * * See `./local-schema.sql` for the local database schema, including view * and trigger machinery. * * See `./sync.ts` for the write-path sync utility, which listens to changes * using pg_notify, as per https://pglite.dev/docs/api#listen */ export default function Wrapper() { const [db, setDb] = useState<PGliteWithLive>() useEffect(() => { let isMounted = true let writePathSync: ChangeLogSynchronizer async function init() { const pglite = await loadPGlite() if (!isMounted) { return } writePathSync = new ChangeLogSynchronizer(pglite) writePathSync.start() setDb(pglite) } init() return () => { isMounted = false if (writePathSync !== undefined) { writePathSync.stop() } } }, []) if (db === undefined) { return <div className="loading">Loading …</div> } return ( <PGliteProvider db={db}> <ThroughTheDB /> </PGliteProvider> ) } function ThroughTheDB() { const db = usePGlite() const results = useLiveQuery<Todo>('SELECT * FROM todos ORDER BY created_at') async function createTodo(event: React.FormEvent) { event.preventDefault() const form = event.target as HTMLFormElement const formData = new FormData(form) const title = formData.get('todo') as string await db.sql` INSERT INTO todos ( id, title, completed, created_at ) VALUES ( ${uuidv4()}, ${title}, ${false}, ${new Date()} ) ` form.reset() } async function updateTodo(todo: Todo) { const { id, completed } = todo await db.sql` UPDATE todos SET completed = ${!completed} WHERE id = ${id} ` } async function deleteTodo(event: React.MouseEvent, todo: Todo) { event.preventDefault() await db.sql` DELETE FROM todos WHERE id = ${todo.id} ` } if (results === undefined) { return <div className="loading">Loading …</div> } const todos = results.rows // The template below the heading is identical to the other patterns. // prettier-ignore return ( <div id="optimistic-state" className="example"> <h3> <span className="title"> 4. Through the DB </span> </h3> <ul> {todos.map((todo: Todo) => ( <li key={todo.id}> <label> <input type="checkbox" checked={todo.completed} onChange={() => updateTodo(todo)} /> <span className={`title ${ todo.completed ? 'completed' : '' }`}> { todo.title } </span> </label> <a href="#delete" className="close" onClick={(event) => deleteTodo(event, todo)}> ✕</a> </li> ))} {todos.length === 0 && ( <li>All done 🎉</li> )} </ul> <form onSubmit={createTodo}> <input type="text" name="todo" placeholder="Type here …" required /> <button type="submit"> Add </button> </form> </div> ) } #### Benefits This provides full offline support, shared optimistic state and allows your components to interact purely with the local database, rather than coding over the network. Data fetching and sending is abstracted away behind Electric (for reads) and the sync utility processing the change log (for writes). Good use-cases include: * building local-first software * mobile and desktop applications * collaboration and authoring software #### Drawbacks Using a local embedded database adds quite a heavy dependency to your app. The shadow table and trigger machinery complicate your client side schema definition. Syncing changes in the background complicates any potential rollback handling. In the shared persistent optimistic state pattern, you can detect a write being rejected by the server whilst in context, still handling user input. With through-the-database sync, this context is harder to reconstruct. #### Implementation notes The merge logic in the `delete_local_on_synced_insert_and_update_trigger` in `./local-schema.sql` supports rebasing local optimistic state on concurrent updates from other users. The rollback strategy in the `rollback` method of the `ChangeLogSynchronizer` in `./sync.ts` is very naive: clearing all local state and writes in the event of any write being rejected by the server. You may want to implement a more nuanced strategy. For example, to provide information to the user about what is happening and / or minimise data loss by only clearing local-state that's causally dependent on a rejected write. This opens the door to a lot of complexity that may best be addressed by using an existing framework or one of the simpler patterns. ## Advanced There are two key complexities introduced by handling offline writes or local writes with optimistic state: 1. merge logic when receiving synced state from the server 2. handling rollbacks when writes are rejected ### Merge logic When a change syncs in over the Electric replication stream, the application has to decide how to handle any overlapping optimistic state. This can be complicated by concurrency, when changes syncing in may be made by other users (or devices, or even tabs). The third and fourth examples both demonstrate approaches to rebasing the local state on the synced state, rather than just naively clearing the local state, in order to preserve local changes. Linearlite is another example of through-the-DB sync with more sophisticated merge logic. ### Rollbacks If an offline write is rejected by the server, the local application needs to find some way to revert the local state and potentially notify the user. A baseline approach can be to clear all local state if any write is rejected. More sophisticated and forgiving strategies are possible, such as: * marking local writes as rejected and displaying for manual conflict resolution * only clearing the set of writes that are causally dependent on the rejected operation One consideration is the indirection between making a write and handling a rollback. When sending write operations directly to an API, your application code can handle a rollback with the write context still available. When syncing through the database, the original write context is much harder to reconstruct. ### YAGNI Adam Wiggins, one of the authors of the local-first paper, developed a canvas-based thinking tool called Muse, explicitly designed to support concurrent, collaborative editing of an infinite canvas. Having operated at scale with a large user base, one of his main findings reported back at the first local-first meetup in Berlin in 2023 was that in reality, conflicts are extremely rare and can be mitigated well by strategies like presence. If you're crafting a highly concurrent, collaborative experience, you may want to engage with the complexities of merge logic and rebasing local state. However, blunt strategies like those illustrated by the patterns in this guide can be much easier to implement and reason about — and are perfectly serviceable for many applications. ## Tools Below we list some useful tools that work well for implementing writes with Electric. ### Libraries * React `useOptimistic` * React Router * SolidJS * Svelte Optimistic Store * TanStack Query * Valtio * Vue `vue-useoptimistic` ### Frameworks * LiveStore * TinyBase * tRPC See also the list of local-first projects on the alternatives page. --- ## Page: https://electric-sql.com/docs/guides/installation  You need to have a Postgres database and to run the Electric sync service in front of it. ## How to run Electric Electric is a web application published as a Docker image at electricsql/electric. It connects to Postgres via a `DATABASE_URL`. ## Recommended The simplest way to run Electric is using Docker. ### Using Docker You can run a fresh Postgres and Electric connected together using Docker Compose with this `docker-compose.yaml`: yaml version: "3.3" name: "electric_quickstart" services: postgres: image: postgres:16-alpine environment: POSTGRES_DB: electric POSTGRES_USER: postgres POSTGRES_PASSWORD: password ports: - 54321:5432 tmpfs: - /var/lib/postgresql/data - /tmp command: - -c - listen_addresses=* - -c - wal_level=logical electric: image: electricsql/electric environment: DATABASE_URL: postgresql://postgres:password@postgres:5432/electric?sslmode=disable # Not suitable for production. Only use insecure mode in development or if you've otherwise secured the Electric API. # See https://electric-sql.com/docs/guides/security ELECTRIC_INSECURE: true ports: - "3000:3000" depends_on: - postgres For example you can run this using: sh curl -O https://electric-sql.com/docker-compose.yaml docker compose up Alternatively, you can run the Electric sync service on its own and connect it to an existing Postgres database, e.g.: sh docker run \ -e "DATABASE_URL=postgresql://..." \ -p 3000:3000 \ -t \ electricsql/electric:latest ### Postgres requirements You can use any Postgres (new or existing) that has logical replication enabled. You also need to connect as a database user that has the `REPLICATION` role. ## Advanced You can also choose to build and run Electric from source as an Elixir application. ### Build from source Clone the Electric repo: sh git clone https://github.com/electric-sql/electric.git cd electric Install the system dependencies with asdf. Versions are defined in .tool-versions: sh asdf plugin-add elixir asdf plugin-add erlang asdf plugin-add nodejs asdf plugin-add pnpm asdf install Install the packages/sync-service dependencies using Mix.: sh cd packages/sync-service mix deps.get Run the development server: sh mix run --no-halt This will try to connect to Postgres using the `DATABASE_URL` configured in packages/sync-service/.env.dev, which defaults to: shell ELECTRIC_LOG_LEVEL=debug DATABASE_URL=postgresql://postgres:password@localhost:54321/electric?sslmode=disable ELECTRIC_ENABLE_INTEGRATION_TESTING=true ELECTRIC_CACHE_MAX_AGE=1 ELECTRIC_CACHE_STALE_AGE=3 # using a small chunk size of 10kB for dev to speed up tests ELECTRIC_SHAPE_CHUNK_BYTES_THRESHOLD=10000 # configuring a second database for multi-tenancy integration testing OTHER_DATABASE_URL=postgresql://postgres:password@localhost:54322/electric?sslmode=disable ELECTRIC_PROFILE_WHERE_CLAUSES=false ELECTRIC_OTEL_SAMPLING_RATIO=1 ELECTRIC_OTEL_DEBUG=false ELECTRIC_INSECURE=true You can edit this file to change the configuration. To run the tests, you'll need a Postgres running that matches the `:test` env config in config/runtime.exs and then: sh mix test If you need any help, ask on Discord. --- ## Page: https://electric-sql.com/docs/guides/deployment  How to deploy the Electric sync engine, with links to integration docs for specific platforms like Supabase, Neon, Render and AWS. Electric Cloud – the simplest way to use Electric The simplest way to use Electric is via the Electric Cloud, which is a simple, scalable, low-cost, managed Electric hosting service. View Cloud ## The ingredients of a successful deployment An Electric deployment has three main components. Your Postgres database, the Electric sync service and your app. Electric connects to your Postgres using a `DATABASE_URL`. Your app connects to Electric over HTTP, usually using a Client library. 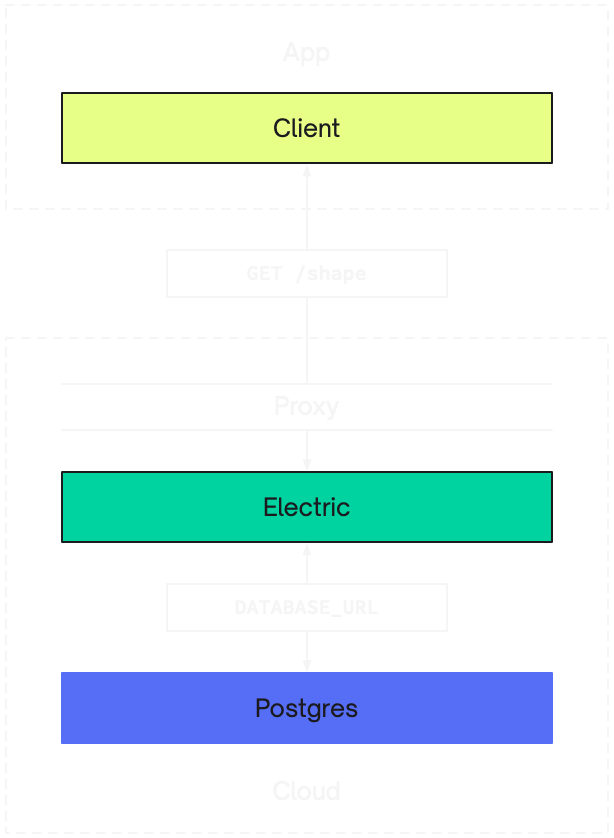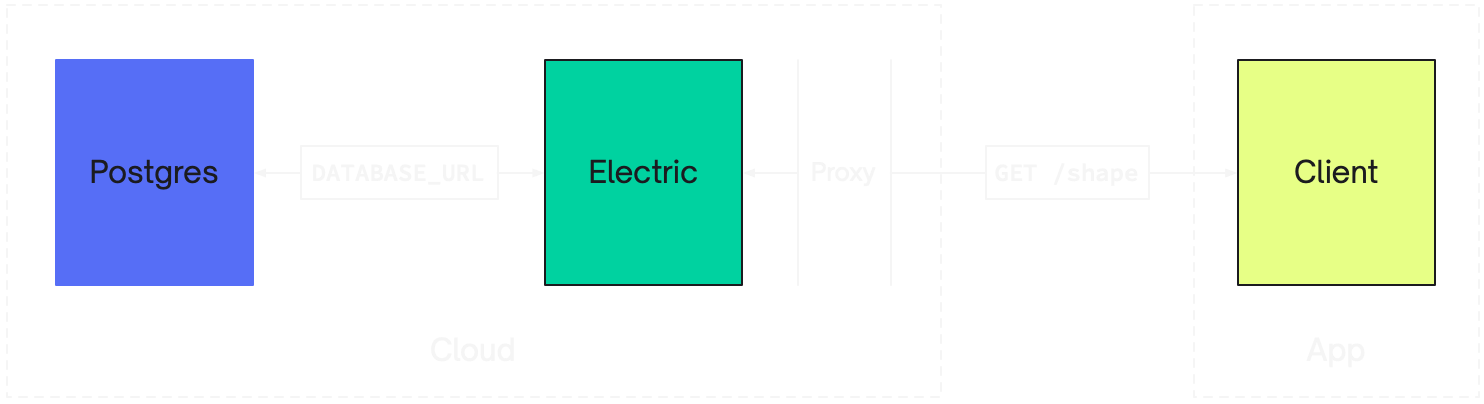 As a result, there are three ingredients to a successful Electric deployment: 1. you need to be running a Postgres database 2. you need to run and connect the Electric sync service 3. you need your app/client to connect to Electric over HTTP ### Proxying requests to Electric You also often want to proxy requests to Electric through your API, or other proxy. For example, to implement auth and/or caching. In these cases, you'll also need to deploy your API and/or proxy layer in front of Electric. Note also that, when running Electric behind a CDN, you may want your proxy in front of the CDN. This is where primitives like edge functions and edge workers can be very useful. ### Securing data access By default, Electric exposes public access to the contents of your database. You generally don't want to expose the contents of your database, so you need to lock down access to the Electric HTTP API. See the Security guide for information. ## 1\. Running Postgres You can use _**any standard Postgres**_, version 14 and above. This includes Postgres you host yourself, or Postgres hosted by managed database hosting providers, including: * Supabase * Neon * AWS (RDS and Aurora) * GCP (Cloud SQL and Alloy) * Digital Ocean * Crunchy Postgres must have logical replication enabled. You also need to connect as a database role that has the `REPLICATION` attribute. ### Data model compatibility Electric is compatible with _**any Postgres data model**_. Electric will work as a drop on to any existing data model. There are no limitations on the database features, data types or extensions you can use. ### Connecting to Postgres You connect to Postgres using a `DATABASE_URL` env var. This connection string contains your user credentials and an `sslmode` parameter. You usually want to connect directly to Postgres and not via a connection pool. This is because Electric uses logical replication and most connection poolers don't support it. (pgBouncer does support logical replication, as of version 1.23 so this may change in future). You can optionally provide a separate `ELECTRIC_QUERY_DATABASE_URL` env var, which can use a pooler and will be used for all queries other than replication. Troubleshooting common errors If you get a TCP connection error saying `non-existing domain - :nxdomain` or `network is unreachable - :enetunreach` then you may need to connect using IPv6. You can enable this by setting `ELECTRIC_DATABASE_USE_IPV6=true`. If you get a TCP connection `timeout` error then make sure you're connecting directly to Postgres and not via a connection pool. For example, when using Supabase you need to untick their "Use connection pooling" option on the database settings page. If you're using IPv6 with Docker, then assuming the machine you're running Electric on has IPv6 connectivity, you may also need to enable IPv6 for the Docker daemon. You can do this by defining an IPv6-capable network) in your Compose file and then adding the `networks` key to the Electric service definition. ### Database resources Electric creates a logical replication publication and replication slot inside Postgres. These are called `electric_publication_default` and `electric_slot_default` by default. You can configure the name suffix using the `ELECTRIC_REPLICATION_STREAM_ID` env var. When running, Electric also keeps a pool of active database connections open. The size of this pool defaults to `20` and can be configured using `ELECTRIC_DB_POOL_SIZE`. Cleaning up resources If you decide to stop using Electric with a given Postgres database or switch to a different database but keep the old one around, make sure to clean up both the publication and the replication slot. See this troubleshooting advice for details. ## 2\. Running Electric The Electric sync engine is an Elixir web service, packaged using Docker. You can deploy it anywhere you can run a container with a filesystem and exposed HTTP port. This includes cloud and application hosting platforms like: * AWS * GCP * Digital Ocean * Fly.io * Render ### Docker container Images are deployed to Docker Hub at electricsql/electric. ### Optimizing for disk Electric caches Shape logs and metadata on the filesystem. Your Electric host must provide a persistent filesystem. Ideally this should be large, fast and locally mounted, such as a NVMe SSD. If you're configuring a machine and you want to optimise it for Electric, the factors to optimise for, in order of important, are: 1. disk speed — low latency, high throughput reads and writes 2. memory 3. CPU For example, on AWS, Storage Optimized instances such as the `i3en.large`, or on Hetzner the SX-line of dedicated servers would both be great choices. ### Configuring storage The path to Electric's persistent storage can be configured via the `ELECTRIC_STORAGE_DIR` environment variable, e.g. `ELECTRIC_STORAGE_DIR=/var/lib/electric/persistent`. Electric will create the directory at that path if it doesn't exist yet. However, you need to make sure that the OS user that Electric is running as has the necessary permissions in the parent directory. The file system location configured via `ELECTRIC_STORAGE_DIR` and the data Electric stores there must survive sync service's restarts. For example, when using Kubernetes, you'll want to create a persistent volume and attach it to your Electric deployment. Clear one, clear the other The persistent state that Electric maintains in Postgres (via the logical replication publication and replication slot) **must** stay in sync with the shape data cached on disk by Electric. If you change the value of `ELECTRIC_STORAGE_DIR` or switch to a different `DATABASE_URL` at any point, you **must** clean up the other location by hand, whether it's removing a directory tree on disk or dropping the replication slot and publication in Postgres. How much storage space? Electric trades storage for low memory use and fast sync. How much storage you need is highly application dependent. We encourage you to test with your own workload. We plan to implement compaction and other features to limit and optimise storage use, such as garbage collecting LRU shapes. ### HTTP port Electric provides an HTTP API exposed on a configurable `ELECTRIC_PORT`. You should make sure this is exposed to the Internet. ### Caching proxy Electric is designed to run behind a caching proxy, such as Nginx, Caddy, Varnish or a CDN like Cloudflare or Fastly. You don't _have_ to run a proxy in front of Electric but you will benefit from radically better performance if you do. See the Caching section of the HTTP API docs for more information. ## 3\. Connecting your app You can then connect your app to Electric over HTTP. Typically you use a Client library and configure the URL in the constructor, e.g.: ts const stream = new ShapeStream({ url: `https://your-electric-service.example.com/v1/shape`, params: { table: `foo` } }) const shape = new Shape(stream) You can connect to Electric from any language/environment that speaks HTTP. See the HTTP API and Client docs for more information. --- ## Page: https://electric-sql.com/docs/guides/security  How to secure data access and encrypt data with Electric. ## Data access Electric is a sync service that runs in front of Postgres. It connects to a Postgres database using a `DATABASE_URL` and exposes the data in that database via an HTTP API.  This API is public by default. It should be secured in production using an API token, network security and/or an authorization proxy. ### Public by default Electric connects to Postgres as a normal database user. It then exposes access to **any data** that its database user can access in Postgres to **any client** that can connect to the Electric HTTP API. You generally do _not_ want to expose public access to the contents of your database, so you **must** secure access to the Electric HTTP API. ### Network security One way of securing access to Electric is to use a network firewall or IP whitelist. You can often configure this using the networking rules of your cloud provider. Or you can use these to restrict public access to Electric and only expose Electric via a reverse-proxy such as Nginx or Caddy. This reverse proxy can then enforce network security rules, for example, using Caddy's `remote-ip` request matcher: hcl @denied not remote_ip 100.200.30.40 100.200.30.41 abort @denied This approach is useful when you're using Electric to sync into trusted infrastructure. However, it doesn't help when you're syncing data into client devices, like apps and web browsers. For those, you need to restrict access using an authorizing proxy. Electric is designed to run behind an authorizing proxy. This is the primary method for securing data access to clients and apps and is documented in detail, with examples, in the Auth guide. ### API token Access to Electric can be secured with an API token. This is a secret string that can be set when starting Electric and will be used to authenticate requests to the Electric HTTP API. When an API token is set, Electric will require all requests to include the API token. The token should _not_ be sent from the client as it will be exposed in the HTTP requests. Instead, it should be added by the authorizing proxy when proxying requests to Electric. ## Encryption Electric syncs ciphertext as well as it syncs plaintext. You can encrypt and decrypt data in HTTP middleware or in the local client. ### End-to-end encryption For example, you can achieve end-to-end encryption by: * _encrypting_ data before it leaves the client * _decrypting_ data when it comes off the replication stream into the client You can see an example of this in the encryption example: tsx import base64 from 'base64-js' import React, { useEffect, useState } from 'react' import { useShape } from '@electric-sql/react' import './Example.css' type Item = { id: string title: string } type EncryptedItem = { id: string ciphertext: string iv: string } const API_URL = import.meta.env.API_URL || 'http://localhost:3001' const ELECTRIC_URL = import.meta.env.ELECTRIC_URL ?? 'http://localhost:3000' // For this example, we hardcode a deterministic key that works across page loads. // In a real app, you would implement a key management strategy. Electric is great // at syncing keys between users :) const rawKey = new Uint8Array(16) const key = await crypto.subtle.importKey('raw', rawKey, 'AES-GCM', true, [ 'encrypt', 'decrypt', ]) /* * Encrypt an `Item` into an `EncryptedItem`. */ async function encrypt(item: Item): Promise<EncryptedItem> { const { id, title } = item const enc = new TextEncoder() const encoded = enc.encode(title) const iv = crypto.getRandomValues(new Uint8Array(12)) const encrypted = await crypto.subtle.encrypt( { iv, name: 'AES-GCM', }, key, encoded ) const ciphertext = base64.fromByteArray(new Uint8Array(encrypted)) const iv_str = base64.fromByteArray(iv) return { id, ciphertext, iv: iv_str, } } /* * Decrypt an `EncryptedItem` to an `Item`. */ async function decrypt(item: EncryptedItem): Promise<Item> { const { id, ciphertext, iv: iv_str } = item const encrypted = base64.toByteArray(ciphertext) const iv = base64.toByteArray(iv_str) const decrypted = await crypto.subtle.decrypt( { iv, name: 'AES-GCM', }, key, encrypted ) const dec = new TextDecoder() const title = dec.decode(decrypted) return { id, title, } } export const Example = () => { const [items, setItems] = useState<Item[]>() const { data } = useShape<EncryptedItem>({ url: `${ELECTRIC_URL}/v1/shape`, params: { table: 'items', }, }) const rows = data !== undefined ? data : [] // There are more efficient ways of updating state than always decrypting // all the items on any change but just to demonstate the decryption ... useEffect(() => { async function init() { const items = await Promise.all( rows.map(async (row) => await decrypt(row)) ) setItems(items) } init() }, [rows]) /* * Handle adding an item by creating the item data, encrypting it * and sending it to the API */ async function createItem(event: React.FormEvent) { event.preventDefault() const form = event.target as HTMLFormElement const formData = new FormData(form) const title = formData.get('title') as string const id = crypto.randomUUID() const item = { id, title, } const data = await encrypt(item) const url = `${API_URL}/items` const options = { method: 'POST', body: JSON.stringify(data), headers: { 'Content-Type': 'application/json', }, } await fetch(url, options) form.reset() } if (items === undefined) { return <div>Loading...</div> } return ( <div> <div> {items.map((item: Item, index: number) => ( <p key={index} className="item"> <code>{item.title}</code> </p> ))} </div> <form onSubmit={createItem}> <input type="text" name="title" placeholder="Type here …" required /> <button type="submit">Add</button> </form> </div> ) } ### Key management One of the primary challenges with encryption is key management. I.e.: choosing which data to encrypt with which keys and sharing the right keys with the right users. Electric doesn't provide or prescribe any specific key management solution. You're free to use any existing key management system, such as Hashicorp Vault, for key management. However, for end-to-end encryption of shared data, you will at some point need to share keys between clients. This is a job that Electric is good at: syncing the right data to the right users. For example, imagine you store keys in a seperate, extra secure, Postgres database and you segment your encryption by tenant (or group, or some other shared resource). You could sync keys to the client using a shape like this: ts import { ShapeStream } from '@electric-sql/client' const stream = new ShapeStream({ url: `${ELECTRIC_URL}/v1/shape`, params: { table: 'tenants', columns: [ 'keys' ], where: `id in ('${user.tenant_ids.join(`', '`)}')` } }) You could then put a denormalised `tenant_id` column on all of the synced tables in your main database and lookup the correct key to use when decrypting and encrypting the row in the client. --- ## Page: https://electric-sql.com/docs/guides/troubleshooting  Tips and answers to FAQs about how to run Electric successfully. ## Local development ### Slow shapes — why are my shapes slow in the browser in local development? Sometimes people encounter a mysterious slow-down with Electric in local development, when your web app is subscribed to 6 or more shapes. This slow-down is caused by a limitation of the legacy version of HTTP, 1.1. With HTTP/1.1, browsers only allow 6 simultaneous requests to a specific backend. This is because each HTTP/1.1 request uses its own expensive TCP connection. As shapes are loaded over HTTP, this means only 6 shapes can be getting updates with HTTP/1.1 due to this browser restriction. All other requests pause until there's an opening. Luckily, HTTP/2, introduced in 2015, fixes this problem by _multiplexing_ each request to a server over the same TCP connection. This allows essentially unlimited connections. HTTP/2 is standard across the vast majority of hosts now. Unfortunately it's not yet standard in local dev environments. ##### Solution — run Caddy To fix this, you can setup a local reverse-proxy using the popular Caddy server. Caddy automatically sets up HTTP/2 and proxies requests to Electric, getting around the 6 requests limitation with HTTP/1.1 in the browser. 1. Install Caddy for your OS — https://caddyserver.com/docs/install 2. Run `caddy trust` so Caddy can install its certificate into your OS. This is necessary for http/2 to Just Work™ without SSL warnings/errors in your browser — https://caddyserver.com/docs/command-line#caddy-trust Note — it's really important you run Caddy directly from your computer and not in e.g. a Docker container as otherwise, Caddy won't be able to use http/2 and will fallback to http/1 defeating the purpose of using it! Once you have Caddy installed and have added its certs — you can run this command to start Caddy listening on port 3001 and proxying shape requests to Electric on port 3000. If you're loading shapes through your API or framework dev server, replace `3000` with the port that your API or dev server is listening on. The browser should talk directly to Caddy. sh caddy run \ --config - \ --adapter caddyfile \ <<EOF localhost:3001 { reverse_proxy localhost:3000 encode { gzip } } EOF Now change your shape URLs in your frontend code to use port `3001` instead of port 3000 and everything will run much faster 🚀 ### Shape logs — how do I clear the server state? Electric writes shape logs to disk. During development, you may want to clear this state. However, just restarting Electric doesn't clear the underlying storage, which can lead to unexpected behaviour. ##### Solution — clear shape logs You can remove `STORAGE_DIR` to delete all shape logs. This will ensure that following shape requests will be re-synced from scratch. ###### Using docker If you're running using Docker Compose, the simplest solution is to bring the Postgres and Electric services down, using the `--volumes` flag to also clear their mounted storage volumes: sh docker compose down --volumes You can then bring a fresh backend up from scratch: sh docker compose up ### Unexpected 409 — why is my shape handle invalid? If, when you request a shape, you get an unexpected `409` status despite the shape existing (for example, straight after you've created it), e.g.: url: http://localhost:3000/v1/shape?table=projects&offset=-1 sec: 0.086570622 seconds status: 200 url: http://localhost:3000/v1/shape?table=projects&offset=0_0&handle=17612588-1732280609822 sec: 1.153542301 seconds status: 409 conflict reading Location url: http://localhost:3000/v1/shape?table=projects&offset=0_0&handle=51930383-1732543076951 sec: 0.003023737 seconds status: 200 This indicates that your client library or proxy layer is caching requests to Electric and responding to them without actually hitting Electric for the correct response. For example, when running unit tests your library may be maintaining an unexpected global HTTP cache. ##### Solution — clear your cache The problem will resolve itself as client/proxy caches empty. You can force this by clearing your client or proxy cache. See https://electric-sql.com/docs/api/http#control-messages for context on 409 messages. ## Production ### WAL growth — why is my Postgres database storage filling up? Electric creates a durable replication slot in Postgres to prevent data loss during downtime. During normal execution, Electric consumes the WAL file and keeps advancing `confirmed_flush_lsn`. However, if Electric is disconnected, the WAL file accumulates the changes that haven't been delivered to Electric. ##### Solution — Remove replication slot after Electric is gone If you're stopping Electric for the weekend, we recommend removing the `electric_slot_default` replication slot to prevent unbounded WAL growth. When Electric restarts, if it doesn't find the replication slot at resume point, it will recreate the replication slot and drop all shape logs. You can also control the size of the WAL with `wal_keep_size`. On restart, Electric will detect if the WAL is past the resume point too. ## IPv6 support If Electric or Postgres are running behind an IPv6 network, you might have to perform additional configurations on your network. ### Postgres running behind IPv6 network In order for Electric to connect to Postgres over IPv6, you need to set `ELECTRIC_DATABASE_USE_IPV6` to `true`. #### Local development If you're running Electric on your own computer, check if you have IPv6 support by opening test-ipv6.com. If you see "No IPv6 address detected" on that page, consider `ssh`ing into another machine or using a VPN service that works with IPv6 networks. When running Electric in a Docker container, there's an additional hurdle in that Docker does not enable IPv6 out-of-the-box. Follow the official guide to configure your Docker daemon for IPv6. #### Cloud If you're running Electric in a Cloud provider, you need to ensure that your VPC is configured with IPv6 support. Check your Cloud provider documentation to learn how to set it up. ### Electric running behind IPv6 network By default Electric only binds to IPv4 addresses. You need to set `ELECTRIC_LISTEN_ON_IPV6` to `true` to bind to bind to IPv6 addresses as well. ### Missing headers — why is the client complaining about missing headers? When Electric responds to shape requests it includes headers that are required by the client to follow the shape log. It is common to run Electric behind a proxy to authenticate users and authorise shape requests. However, the proxy might not keep the response headers in which case the client may complain about missing headers. ##### Solution — configure proxy to keep headers Verify the proxy configuration and make sure it doesn't remove any of the `electric-...` headers. --- ## Page: https://electric-sql.com/docs/guides/client-development  How to write an Electric client for any language that speaks HTTP and JSON. ## HTTP and JSON You can create a client for Electric by: 1. implementing a long-polling strategy to consume the HTTP API 2. (optionally) materialising the shape log into a data structure or local store 3. (optionally) providing reactivity bindings ## Consume the HTTP API The Electric sync service syncs data over an HTTP API. The primary job of a client is to consume this API using HTTP requests. The HTTP API exposes Shapes. There are two phases to syncing a shape: 1. initial sync where you load all the data the server is currently aware of 2. live mode where you wait for and consume live updates in real-time ### Initial sync In the initial sync phase, you make a series of requests to get Shape data, increasing the `offset` parameter until you get an `up-to-date` message. #### Construct your shape URL Encode a shape definition into a `GET /v1/shape` URL. See the specification for the URL structure here. For example, a Shape that contains all of the rows in the `items` table would be requested with: http GET /v1/shape?table=items #### Make the initial `offset=-1` request The first request to a shape should set the `offset` parameter to `-1`. This indicates to Electric that you want to consume all of the data from the beginning of the Shape log. For example, you might make a request to: http GET /v1/shape?table=items?offset=-1 The body of the response will contain a JSON array of messages. The headers of the response will contain two pieces of important information: * `electric-handle` an ephemeral identifier to an existing shape log * `electric-offset` the offset value for your next request If the last message in the response body contains an `up-to-date` control message: json {"headers":{"control":"up-to-date"}} Then the response will also contain an: * `electric-up-to-date` header Either of which indicate that you can process the messages and switch into live mode. Otherwise, you should continue to accumulate messages by making additional requests to the same URL, with the new shape handle and offset. For example: http GET /v1/shape?table=items&handle=38083685-1729874417404&offset=0_0 In this way, you keep making GET requests with increasing offsets until you load all the data that the server is aware of, at which point you get the `up-to-date` message. ### Live mode In live mode, if the server doesn't have any new data, it will hold open your request until either a timeout or new data arrives. This allows you to implement long polling, where you keep the request open, and reconnect immediately when new data arrives. Why not websockets?! Consuming data over HTTP allows us to leverage CDNs, simplifies observability and allows you to implement auth (and other capabilities) using HTTP proxies. #### Add `live` and `cursor` parameters Set `live=true` to switch Electric into live mode. Make sure your request timeout is higher than the server timeout (which defaults to `20s`) If the previous response contains an `electric-cursor` header, then also set the `cursor` parameter to its value. (This is an extra cache-busting parameter used to normalise request-collapsing behaviour across different CDNs). For example: http GET /v1/shape?table=items&handle=38083685-1729874417404&offset=27344208_0&cursor=1674440&live=true #### Keep polling Live requests will either timeout, returning `204 No content`, or will return an array of messages and headers, just as with non live responses. Keep pooling and whenever you get new data with an `up-to-date` header/message then process the messages. ## Materialise the shape log How you choose to process shape log messages is up-to you. You can: * stream the shape log messages through * materialise the shape log into a data structure or database ### Streaming messages If you just want a stream of logical database operations, you can simply stream or broadcast these onwards. This is what both the Typescript client `ShapeStream` class and Elixir client `stream/3` function do. ### Into a data structure If you want to maintain a materialised Shape in your client, you can apply the operations in the shape log to a data structure. This is what both the Typescript client `Shape` class and Redis example do. Shape log messages are either control messages or logical `insert`, `update` or `delete` operations. You can materialise a Shape by applying these to your chosen data structure. For example, for a Javascript `Map`: ts switch (message.headers.operation) { case `insert`: data.set(message.key, message.value) break case `update`: data.set(message.key, { ...data.get(message.key)!, ...message.value, }) break case `delete`: data.delete(message.key) break } ### Into a database As well as just a single data structure, it's possible to materialise one or more shapes into a local store. This can be very simple -- just update entries in a normalised store, no matter which shape they came through -- or can be complex, when aiming to maintain database invariants in a local embedded database such as PGlite. ### Transactions Only apply logical operations to your materialised structure when you get an `up-to-date` message. Then either apply that batch of operations to your data structure or store atomically, for example using some kind of transactional application primitive, or only trigger reactivity once all the changes are applied. ## Reactivity bindings If you maintain a materialised data structure, it's often useful to know when it changes. This is what the Typescript client's `Shape.subscribe` function enables, for example. This can then be used by a framework to trigger re-rendering. See the `useShape` React hook source code for a real example but in short, e.g.: for a React component: tsx import { useEffect, useState } from 'react' const MyComponent = ({ shapeDefinition }) => { const [ data, setData ] = useState([]) useEffect(() => { const stream = new ShapeStream(shapeDefinition) const shape = new Shape(stream) shape.subscribe(setData) return () => { shape.unsubscribe() } }, [shapeDefinition]) } How you choose to provide this kind of API is very language dependent. You could support registering callbacks (like `shape.subscribe`) and then call these whenever you've finished materialising your shape, or you could some kind of broadcast mechanism. ## Examples Let's walk through the process of implementing a client in a real programming language. ### Brainfuck shell ++++++++[>++++++++++>++++++++++++++>+++++++++++++++>++++>+++++++>+++++<<<<<<-]>-.>--.--.>+.>.<<--.+++++.----.--.+++++.-------.>>.>+++.>+. ### Python Let's build a simple happy-path client in Python to materialise a Shape into a `dict`. First create a new folder and make it a Python package: shell mkdir example-client cd example-client touch __init__.py Install the Requests HTTP client: shell # Optionally in a virtualenv: # virtualenv .venv # source .venv/bin/activate python -m pip install requests Now let's write our `Shape` client, saving the following in `client.py`: python import requests from urllib.parse import urlencode class Shape(object): """Syncs a shape log and materialises it into a `data` dict.""" def __init__(self, base_url='http://localhost:3000', offset=-1, handle=None, table=None, where=None): if table is None: raise "Must provide a table" # Request state used to build the URL. self.base_url = base_url self.cursor = None self.handle = handle self.live = False self.offset = offset self.table = table self.where = where # Materialiased data. self.data = {} # Accumulated messages (waiting for an `up-to-date` to apply). self.messages = [] # Registered callbacks to notify when the data changes. self.subscribers = [] def subscribe(self, callback): """Register a function that's called whenever the data changes.""" self.subscribers.append(callback) def sync(self): """Start syncing. Note that this blocks the current thread.""" while True: self.request() def request(self): """Make a request to `GET /v1/shape` and process the response.""" # Build the URL based on the current parameters. url = self.build_url() # Fetch the response. response = requests.get(url) # This is a happy path example, so we just log error codes. # A real client should handle errors, backoff, reconnect, etc. if response.status_code > 204: raise Exception("Error: {}".format(response.status_code)) # If the response is 200 then we may have new data to process. if response.status_code == 200: self.messages.append(response.json()) # If we're up-to-date, switch into live mode and process # the accumulated messages. if 'electric-up-to-date' in response.headers: self.live = True self.process_messages() # Set the shape handle, offset and optionally cursor for # the next request from the response headers. self.handle = response.headers['electric-handle'] self.offset = response.headers['electric-offset'] if 'electric-cursor' in response.headers: self.cursor = r.headers['electric-cursor'] def process_messages(self): """Process any batched up messages. If the data has changed, notify the subscribers. """ has_changed = False # Process the accumulated messages. for batch in self.messages: for message in batch: if 'operation' in message.get('headers', {}): op_changed = self.apply_operation(message) if op_changed: has_changed = True # Clear the queue. self.messages = [] # If the data has changed, notify the subscribers. if has_changed: self.notify_subscribers() def apply_operation(self, message): """Apply a logical operation message to the data dict. Return whether the data has changed. """ key = message['key'].replace('"', '').split("/")[-1] value = message.get('value') operation = message['headers']['operation'] if operation == 'insert': self.data[key] = value return True if operation == 'update': has_changed = False current_value = self.data[key] for k, v in value: if current_value.get(k) != v: has_changed = True current_value.update(new_value) return has_changed if operation == 'delete': if key in self.data: del self.data[key] return True return False def notify_subscribers(self): for callback in self.subscribers: callback(self.data) def build_url(self): params = { 'offset': self.offset, 'table': self.table } if self.cursor is not None: params['cursor'] = self.cursor if self.handle is not None: params['handle'] = self.handle if self.live: params['live'] = True if self.where is not None: params['where'] = self.where return "{}/v1/shape?{}".format(self.base_url, urlencode(params)) Now let's create a test file to test running the client. Save the following in `client.test.py`: python import multiprocessing import unittest from client import Shape class TestClient(unittest.TestCase): def test_shape_sync(self): parent_conn, child_conn = multiprocessing.Pipe() shape = Shape(table='items') shape.subscribe(child_conn.send) p = multiprocessing.Process(target=shape.sync) p.start() data = parent_conn.recv() self.assertEqual(type(data), dict) p.kill() if __name__ == '__main__': unittest.main() Make sure you have Electric running and then: shell $ python client.test.py . ---------------------------------------------------------------------- Ran 1 test in 0.087s OK